Редактор Downcodes познакомит вас с Emu3, новейшей мультимодальной моделью мира, выпущенной Исследовательским институтом Чжиюань! Emu3 полагается на свою уникальную способность «предсказания следующего токена» для достижения революционного понимания и возможностей генерации в трех модальностях: текст, изображение и видео. Он может не только генерировать высококачественные изображения и плавные и естественные видеоролики, но также точно распознавать изображения и прогнозировать видео. Его производительность превосходит многие известные модели с открытым исходным кодом. Открытый исходный код Emu3 также придает новую жизнь развитию мультимодального искусственного интеллекта. Давайте рассмотрим технологические инновации и будущий потенциал, стоящий за ними.
Исследовательский институт Чжиюань официально выпустил свою мультимодальную модель мира Emu3. Самая большая особенность этой модели заключается в том, что она может прогнозировать следующий токен в трех различных режимах: текст, изображение и видео для понимания и генерации.

Что касается генерации изображений, Emu3 способен генерировать высококачественные изображения на основе прогнозирования визуальных токенов. Это означает, что пользователи могут рассчитывать на гибкое разрешение и разнообразие стилей.

Что касается генерации видео, Emu3 работает совершенно по-новому. В отличие от других моделей, которые генерируют видео с помощью шума, Emu3 генерирует видео напрямую посредством последовательного прогнозирования. Этот технологический прогресс делает создание видео более плавным и естественным.

В таких задачах, как генерация изображений, видео и понимание визуального языка, производительность Emu3 превосходит производительность многих известных моделей с открытым исходным кодом, таких как SDXL, LLaVA и OpenSora. За ним стоит мощный визуальный токенизатор, который может конвертировать видео и изображения в отдельные токены. Этот дизайн предлагает новые идеи для унифицированной обработки текста, изображений и видео.
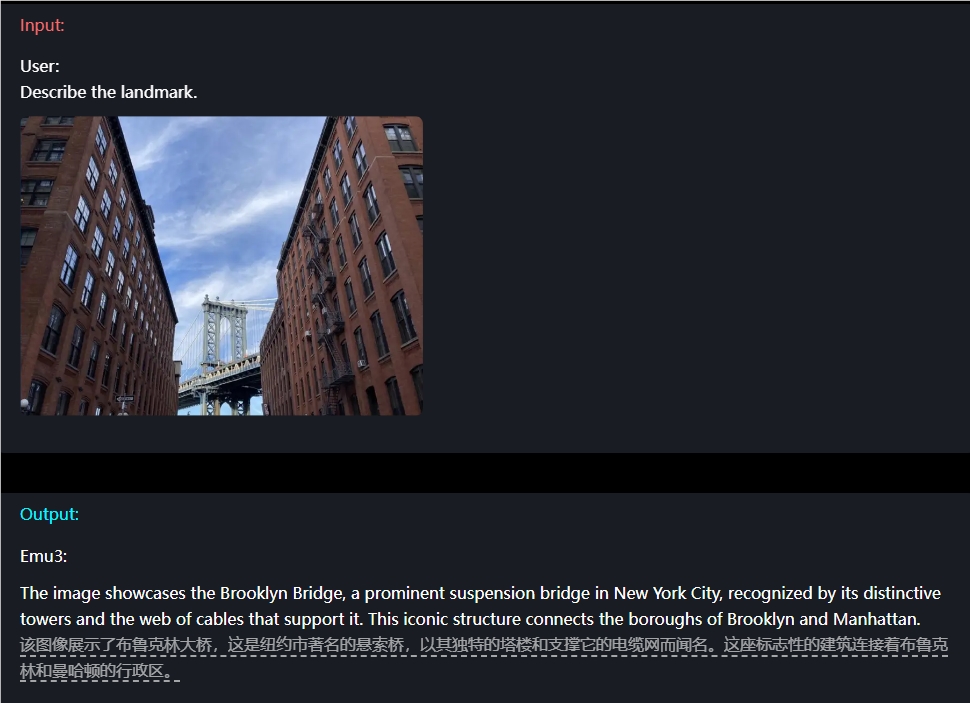
Например, чтобы понять изображение, пользователям достаточно просто ввести вопрос, и Emu3 сможет точно описать содержимое изображения.
Emu3 также имеет возможности прогнозирования видео. Получив видео, Emu3 может предсказать, что произойдет дальше, на основе существующего контента. Это позволяет ему демонстрировать сильные возможности моделирования окружающей среды, поведения людей и животных, позволяя пользователям испытать более реалистичный интерактивный опыт.

Кроме того, гибкость дизайна Emu3 впечатляет. Его можно оптимизировать непосредственно с учетом предпочтений человека, чтобы создаваемый контент больше соответствовал ожиданиям пользователей. Более того, Emu3, как модель с открытым исходным кодом, вызвала бурные дискуссии в техническом сообществе. Многие считают, что это достижение полностью изменит модель развития мультимодального ИИ.
URL-адрес проекта: https://emu.baai.ac.cn/about
Статья: https://arxiv.org/pdf/2409.18869.
Выделять:
Emu3 реализует мультимодальное понимание и генерацию текста, изображений и видео посредством прогнозирования следующего токена.
В ряде задач производительность Emu3 превзошла производительность многих известных моделей с открытым исходным кодом, продемонстрировав свои мощные возможности.
Гибкий дизайн Emu3 и функции с открытым исходным кодом предоставляют разработчикам новые возможности и, как ожидается, будут способствовать инновациям и развитию мультимодального искусственного интеллекта.
Появление Emu3 знаменует собой новую веху в области мультимодального искусственного интеллекта. Его высокая производительность, гибкий дизайн и функции с открытым исходным кодом, несомненно, окажут глубокое влияние на будущее развитие искусственного интеллекта. Мы с нетерпением ждем, когда Emu3 будет использоваться в большем количестве областей и принесет человечеству больше удобства и сюрпризов!