Редактор Downcodes познакомит вас с последними исследованиями Технического университета Дармштадта в Германии. В этом исследовании проблема Бонгарда использовалась в качестве инструмента тестирования для оценки производительности современной модели изображения искусственного интеллекта в простых задачах визуального мышления. Результаты исследования удивительны. Даже точность лучших мультимодальных моделей, таких как GPT-4o, намного ниже ожидаемой, что заставляет задуматься о существующих стандартах оценки зрительных способностей ИИ.
Последние исследования Технического университета Дармштадта в Германии раскрывают феномен, заставляющий задуматься: даже самые продвинутые модели изображений, созданные искусственным интеллектом, могут допускать серьезные ошибки при выполнении простых задач визуального мышления. Результаты этого исследования выдвинули новый взгляд на стандарты оценки зрительных способностей ИИ.
В качестве инструмента тестирования исследовательская группа использовала задачу Бонгарда, разработанную российским учёным Михаилом Бонгардом. Этот тип визуальной головоломки состоит из 12 простых изображений, разделенных на две группы, и требует выявления правил, по которым эти две группы различаются. Эта абстрактная задача рассуждения не сложна для большинства людей, но производительность модели ИИ удивила.
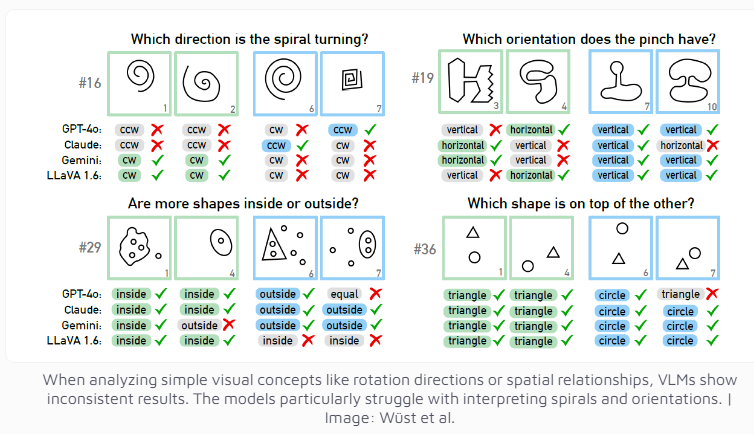
Даже мультимодальная модель GPT-4o, считающаяся на данный момент самой совершенной, успешно решила лишь 21 из 100 визуальных задач. Производительность других известных моделей искусственного интеллекта, таких как Claude, Gemini и LLaVA, еще менее удовлетворительна. Эти модели демонстрируют значительные трудности с определением основных визуальных понятий, таких как вертикальные и горизонтальные линии, или с оценкой направления спирали.
Исследователи обнаружили, что даже когда было предоставлено несколько вариантов выбора, производительность модели ИИ улучшилась лишь незначительно. Только при строгих ограничениях на количество возможных ответов GPT-4 и Клод улучшили свои показатели успеха до 68 и 69 головоломок соответственно. Благодаря углубленному анализу четырех конкретных случаев исследовательская группа обнаружила, что у систем ИИ иногда возникают проблемы на базовом уровне визуального восприятия, прежде чем они достигают стадии мышления и рассуждения, но конкретные причины все еще трудно определить.
Это исследование также заставляет задуматься о критериях оценки систем искусственного интеллекта. Исследовательская группа отметила: почему модели визуального языка хорошо справляются с установленными тестами, но с трудом справляются с, казалось бы, простой проблемой Бонгарда. Насколько значимы эти тесты для оценки реальных способностей к рассуждению? Эти вопросы предполагают, что текущая система оценки ИИ? возможно, потребуется перепроектировать, чтобы более точно измерить возможности визуального мышления ИИ.
Это исследование не только демонстрирует ограничения нынешних технологий искусственного интеллекта, но и указывает путь для будущего развития визуальных возможностей искусственного интеллекта. Это напоминает нам о том, что хотя мы и приветствуем быстрый прогресс ИИ, мы также должны четко осознавать, что еще есть возможности для улучшения базовых когнитивных способностей ИИ.
Это исследование ясно показывает, что модели ИИ еще имеют много возможностей для улучшения визуального мышления, и в будущем необходимы более эффективные методы оценки и технологические прорывы для улучшения когнитивных способностей ИИ. Редактор Downcodes продолжит уделять внимание передовым достижениям в области искусственного интеллекта и публиковать для вас еще больше интересных репортажей.