В последние годы мультимодальные большие модели быстро развиваются, и появилось много отличных моделей. Однако большинство существующих моделей полагаются на визуальные кодеры, которые страдают от проблем смещения зрительной индукции, вызванных разделением обучения, что ограничивает эффективность и производительность. Редактор Downcodes представляет вам новую модель визуального языка EVE, запущенную Исследовательским институтом Чжиюань совместно с университетами. Она использует архитектуру без кодирования и добилась отличных результатов в многочисленных тестах производительности, предоставляя новые возможности для разработки мультимодальных моделей. идеи.
В последнее время достигнут значительный прогресс в исследовании и применении мультимодальных больших моделей. Иностранные компании, такие как OpenAI, Google, Microsoft и т. д., запустили ряд передовых моделей, а отечественные институты, такие как Zhipu AI и Step Star, добились прорыва в этой области. Эти модели обычно полагаются на визуальные кодировщики для извлечения визуальных функций и объединения их с большими языковыми моделями, но существует проблема смещения визуальной индукции, вызванная разделением обучения, что ограничивает эффективность развертывания и производительность мультимодальных больших моделей.
Чтобы решить эти проблемы, Чжиюаньский научно-исследовательский институт совместно с Даляньским технологическим университетом, Пекинским университетом и другими университетами запустил новое поколение модели визуального языка EVE, не требующей кодирования. EVE интегрирует визуально-лингвистическое представление, выравнивание и вывод в единую чистую архитектуру декодера посредством усовершенствованных стратегий обучения и дополнительного визуального контроля. Используя общедоступные данные, EVE показывает хорошие результаты в нескольких визуально-лингвистических тестах, приближаясь или даже превосходя основные мультимодальные методы на основе кодировщиков.
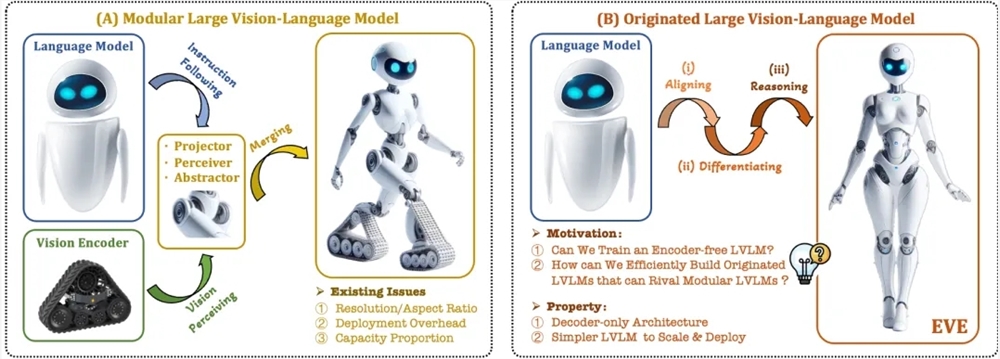
Ключевые особенности EVE включают в себя:
Модель собственного визуального языка: удален визуальный кодировщик и обрабатывается любое соотношение сторон изображения, что значительно лучше, чем у модели Fuyu-8B того же типа.
Низкие затраты на данные и обучение: для предварительного обучения используются общедоступные данные, такие как OpenImages, SAM и LAION, а время обучения короткое.
Прозрачное и эффективное исследование: обеспечивает эффективный и прозрачный путь разработки собственных мультимодальных архитектур чистых декодеров.
Структура модели:
Слой встраивания патчей: получите 2D-карту объектов изображения с помощью одного слоя свертки и среднего слоя пула для улучшения локальных функций и глобальной информации.
Слой выравнивания патчей: интегрируйте многоуровневые сетевые визуальные функции для достижения точного выравнивания с выходными данными визуального кодировщика.
Стратегия обучения:
Предварительный этап обучения с использованием больших языковых моделей: установление первоначальной связи между зрением и языком.
Генеративный этап предварительной подготовки: улучшите способность модели понимать визуально-лингвистический контент.
Фаза контролируемой тонкой настройки: регулирует способность модели следовать языковым инструкциям и изучать модели разговора.
Количественный анализ: EVE хорошо работает во многих тестах визуального языка и сравнима с различными моделями визуального языка на основе кодировщиков. Несмотря на трудности с точным реагированием на конкретные инструкции, благодаря эффективной стратегии обучения EVE достигает производительности, сравнимой с моделями визуального языка с базами кодировщиков.
EVE продемонстрировала потенциал моделей визуального языка без кодирования. В будущем она может продолжать способствовать развитию мультимодальных моделей посредством дальнейшего улучшения производительности, оптимизации архитектур без кодировщиков и создания собственных мультимодальных моделей. модели.
Адрес статьи: https://arxiv.org/abs/2406.11832.
Код проекта: https://github.com/baaivision/EVE.
Адрес модели: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
В целом, появление модели EVE открывает новые направления и возможности для разработки мультимодальных больших моделей. Ее эффективная стратегия обучения и отличная производительность заслуживают внимания. Мы с нетерпением ожидаем, что будущая модель EVE сможет продемонстрировать свои мощные возможности в большем количестве областей.