В голосовом общении в реальном времени изменение тембра говорящего без ущерба для семантики и просодии всегда было технической проблемой. Редактор Downcodes сегодня представит революционную технологию — StreamVC, которая может изменять тембр голоса говорящего в реальном времени, сохраняя при этом голосовое содержание и ритм. Она подходит для мобильных платформ и обеспечивает общение в реальном времени и анонимизацию голоса. Низкая задержка, высококачественный синтез речи и стабильность высоты тона StreamVC дают ему значительные преимущества в области связи в реальном времени.
В мире общения в реальном времени, будь то телефонный звонок или видеоконференция, звук является для нас важным инструментом самовыражения. Но задумывались ли вы когда-нибудь о том, что произошло бы, если бы мы могли изменять тембр голоса говорящего в реальном времени, не влияя на содержание и ритм языка. Появление технологии StreamVC позволяет нам это сделать.
StreamVC — это инновационное решение для преобразования голоса, которое соответствует тембру целевого голоса, сохраняя при этом содержание и просодию исходного голоса. В отличие от традиционных методов, StreamVC создает результирующий сигнал с низкой задержкой входного сигнала даже на мобильных платформах, что делает его пригодным для сценариев связи в реальном времени, таких как телефонные звонки и видеоконференции, а также для анонимизации голоса в этих сценариях.
Технические характеристики:
В реальном времени: StreamVC способен выполнять вывод с малой задержкой в течение 70,8 миллисекунд на мобильных устройствах.
Высококачественный синтез речи. Используйте архитектуру и стратегию обучения нейронного аудиокодека SoundStream для достижения легкого и высококачественного синтеза речи.
Стабильность высоты тона: за счет введения информации о белой основной частоте (f0) улучшается согласованность высоты тона без утечки информации о тембре исходного динамика.
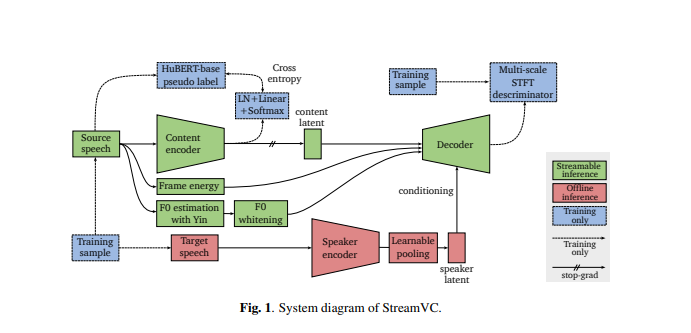
Дизайн StreamVC вдохновлен Soft-VC и SoundStream. Он использует дискретные речевые единицы, извлеченные с помощью модели HuBERT, в качестве целей прогнозирования для сети кодировщика контента. Архитектура кодера и декодера контента, а также стратегия обучения разработаны на основе нейронного аудиокодека SoundStream для достижения высококачественного причинного синтеза звука.
StreamVC сравнивали с существующими технологиями по нескольким критериям, включая естественность, понятность, сходство говорящих и постоянство высоты тона. Результаты экспериментов показывают, что StreamVC хорошо сохраняет высоту исходного языка и сравним с точно настроенной моделью с точки зрения сходства говорящих.
StreamVC доказывает, что эффективное преобразование звука с низкой задержкой на мобильных устройствах вполне осуществимо. Единицы мягкой речи, созданные на основе HuBERT, можно изучить с помощью потоковой причинно-следственной архитектуры сверточной нейронной сети, а введение выбеленной информации f0 в декодер имеет решающее значение для обеспечения высококачественного вывода.
Адрес статьи: https://arxiv.org/pdf/2401.03078.
Появление технологии StreamVC открыло новые возможности для голосовой связи в реальном времени. Ее возможности высококачественного преобразования голоса с малой задержкой будут способствовать применению голосовых технологий во многих областях. Я считаю, что в будущем StreamVC будет играть большую роль в анонимизации голоса, голосовых спецэффектах и т. д. С нетерпением ждем новых инновационных приложений на базе StreamVC!