Недавно лаборатория искусственного интеллекта Tencent запустила новую модель под названием VTA-LDM, которая предназначена для эффективного преобразования видеоконтента в семантически и временно согласованный звук. Основная технология этой модели заключается в «неявном выравнивании», которое идеально согласовывает сгенерированный аудио- и видеоконтент, значительно улучшая качество и сценарии применения генерации звука. Редактор Downcodes поможет вам глубже понять инновации и перспективы применения модели VTA-LDM.
Благодаря значительному прогрессу в технологии преобразования текста в видео, вопрос о том, как генерировать семантически и временно согласованный аудиоконтент из видеовхода, стал горячей темой среди исследователей. Недавно исследовательская группа лаборатории искусственного интеллекта Tencent запустила новую модель под названием «Implicitly Aligned Video to Audio Generation» — VTA-LDM, целью которой является предоставление эффективных решений для генерации звука.
Вход в проект: https://top.aibase.com/tool/vta-ldm
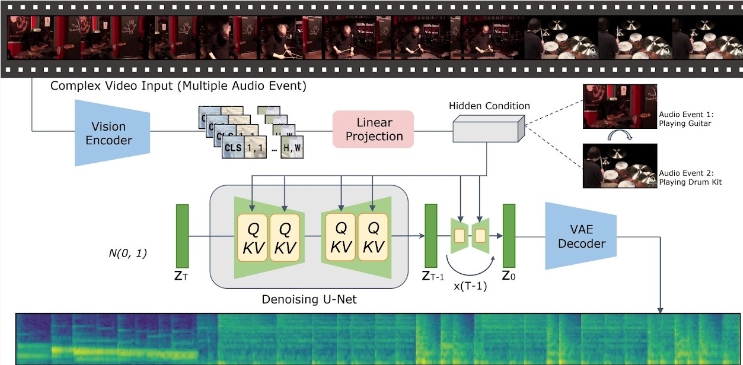
Основная идея модели VTA-LDM заключается в семантическом и временном сопоставлении сгенерированного аудио- и видеоконтента с помощью технологии неявного выравнивания. Этот метод не только улучшает качество генерации звука, но и расширяет сценарии применения технологии генерации видео. Исследовательская группа провела углубленное исследование конструкции модели и объединила различные технические средства для обеспечения точности и согласованности генерируемого звука.
Исследование сосредоточено на трех ключевых аспектах: визуальных кодировщиках, вспомогательных встраиваниях и методах увеличения данных. Исследовательская группа сначала создала базовую модель и провела на ее основе большое количество экспериментов по абляции, чтобы оценить влияние различных визуальных кодеров и вспомогательных вложений на эффект генерации. Результаты этих экспериментов показывают, что модель хорошо работает с точки зрения качества генерации и одновременного выравнивания видео и звука, достигая авангарда современных технологий.
Что касается вывода, пользователям нужно всего лишь поместить видеоклипы в указанный каталог данных и запустить предоставленный сценарий вывода для создания соответствующего аудиоконтента. Исследовательская группа также предоставляет набор инструментов, которые помогут пользователям объединить сгенерированный звук с исходным видео, что еще больше повышает удобство приложения.
Модель VTA-LDM в настоящее время предоставляет несколько различных версий модели для удовлетворения различных исследовательских потребностей. Эти модели охватывают базовые модели и множество расширенных моделей, стремясь предоставить пользователям гибкий выбор для адаптации к различным экспериментам и сценариям применения.
Запуск модели VTA-LDM знаменует собой важный прогресс в области преобразования видео в аудио. Исследователи надеются использовать эту модель для содействия развитию связанных технологий и создания более широких возможностей применения.
## Основные моменты:
Появление модели VTA-LDM принесло новые прорывы в области генерации видео и аудио. Ее эффективные и удобные методы работы и мощные функции предвещают более широкую перспективу применения в будущем. Считается, что с постоянным развитием технологий модель VTA-LDM будет играть важную роль во многих областях.