Редактор даункодов приносит большие новости! Революционная технология ускорения Transformer FlashAttention-3 официально выпущена! Эта технология произведет революцию в скорости вывода и стоимости больших языковых моделей (LLM), достигнув беспрецедентного повышения эффективности. Скорость увеличивается в 1,5–2 раза, режим низкой точности (FP8) сохраняет высокую точность, а возможности обработки длинного текста значительно расширяются, что открывает новые возможности для приложений искусственного интеллекта! Давайте поближе познакомимся с этой революционной технологией.
Выпущена новая технология ускорения Transformer FlashAttention-3. Это не просто обновление, это знаменует собой резкое увеличение скорости вывода и резкое падение стоимости наших больших языковых моделей (LLM)!
Давайте сначала поговорим об этом FlashAttention-3. По сравнению с предыдущей версией это просто изменение дробовика:
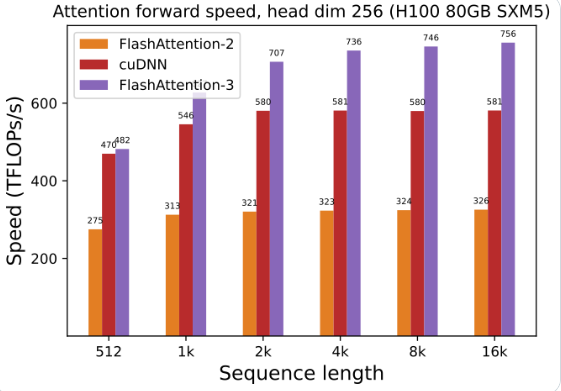
Использование графического процессора было значительно улучшено: при использовании FlashAttention-3 для обучения и запуска больших языковых моделей скорость увеличивается вдвое, в 1,5–2 раза. Это потрясающая эффективность!
Низкая точность, высокая производительность: он также может работать с числами низкой точности (FP8), сохраняя при этом точность. Что это означает? Снижение затрат без ущерба для производительности!
Обработка длинных текстов — проще простого: FlashAttention-3 значительно расширяет возможности модели ИИ по обработке длинных текстов, что раньше было невообразимо.
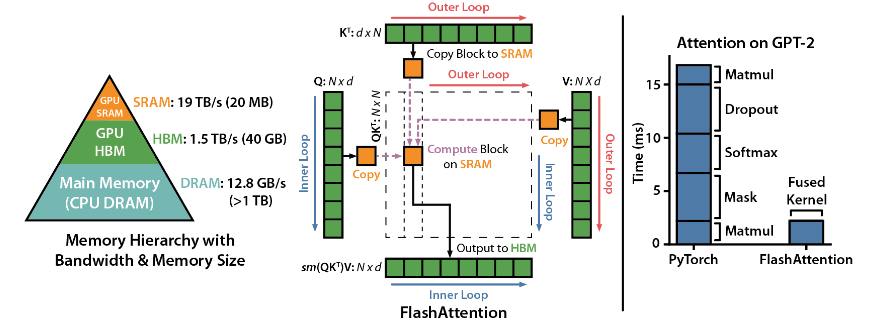
FlashAttention — это библиотека с открытым исходным кодом, разработанная Dao-AILab. Она основана на двух важных статьях и обеспечивает оптимизированную реализацию механизма внимания в моделях глубокого обучения. Эта библиотека особенно подходит для обработки крупномасштабных наборов данных и длинных последовательностей. Существует линейная зависимость между потреблением памяти и длиной последовательности, которая гораздо более эффективна, чем традиционная квадратичная зависимость.
Технические характеристики:
Поддержка передовых технологий: локальное внимание, детерминированное обратное распространение ошибки, ALiBi и т. д. Эти технологии выводят выразительность и гибкость модели на более высокий уровень.
Оптимизация графического процессора Hopper: FlashAttention-3 специально оптимизировал поддержку графического процессора Hopper, производительность повышена более чем на полтора пункта.
Простота установки и использования: поддерживает CUDA11.6 и PyTorch1.12 или выше, легко устанавливается с помощью команды pip в системе Linux. Хотя пользователям Windows может потребоваться дополнительное тестирование, попробовать определенно стоит.
Основные функции:
Эффективная производительность: оптимизированный алгоритм значительно снижает требования к вычислениям и памяти, особенно для обработки данных длинных последовательностей, а улучшение производительности видно невооруженным глазом.
Оптимизация памяти: по сравнению с традиционными методами FlashAttention потребляет меньше памяти, а линейная зависимость делает использование памяти больше не проблемой.
Расширенные функции: интеграция различных передовых технологий значительно повышает производительность модели и расширяет возможности применения.
Простота использования и совместимость. Простое руководство по установке и использованию в сочетании с поддержкой нескольких архитектур графических процессоров позволяет быстро интегрировать FlashAttention-3 в различные проекты.
Адрес проекта: https://github.com/Dao-AILab/flash-attention
Появление FlashAttention-3, несомненно, ускорит применение и разработку крупномасштабных языковых моделей и принесет новые прорывы в области искусственного интеллекта. Его эффективная производительность и простота использования делают его идеальным выбором для разработчиков. Поторопитесь и испытайте это!