Редактор Downcodes расскажет вам правду о моделях визуального языка (VLM)! Как вы думаете, могут ли VLM «понимать» изображения, подобные людям? Правда не так проста. В этой статье мы глубоко исследуем ограничения VLM в понимании изображений и посредством серии экспериментальных результатов покажем огромный разрыв между ними и зрительными возможностями человека. Готовы ли вы пересмотреть свое понимание VLM?
Каждый должен был слышать о моделях визуального языка (VLM). Эти маленькие специалисты в области искусственного интеллекта умеют не только читать текст, но и «видеть» картинки. Но это не так. Сегодня давайте посмотрим на их «трусы», чтобы увидеть, действительно ли они могут «видеть» и понимать изображения, как мы, люди.
Прежде всего, я должен рассказать вам немного научно-популярной информации о том, что такое VLM. Проще говоря, это большие языковые модели, такие как GPT-4o и Gemini-1.5Pro, которые очень хорошо справляются с обработкой изображений и текста и даже достигают высоких результатов во многих тестах на визуальное понимание. Но не позволяйте этим высоким результатам ввести вас в заблуждение: сегодня мы проверим, действительно ли они так хороши.
Исследователи разработали набор тестов под названием BlindTest, который содержит семь чрезвычайно простых для человека задач. Например, определить, перекрываются ли два круга, пересекаются ли две линии или подсчитать, сколько кругов в олимпийском логотипе. Кажется ли, что с этими задачами легко справятся дети из детского сада? Но позвольте мне сказать вам, что производительность этих VLM не так уж и впечатляет?
Результаты шокируют. Средняя точность этих так называемых продвинутых моделей на BlindTest составляет всего 56,20%, а лучшая Sonnet-3.5 имеет точность 73,77%. Это похоже на лучшего ученика, который утверждает, что может поступить в Университет Цинхуа и Пекинский университет, но оказывается, что он даже не может правильно ответить на математические вопросы в начальной школе.

Почему это происходит? Исследователи проанализировали, что это может быть потому, что VLM похожи на близорукость при обработке изображений и не могут четко видеть детали. Хотя они могут примерно увидеть общую тенденцию изображения, когда дело доходит до точной пространственной информации, например, пересекаются ли два изображения или перекрываются, они приходят в замешательство.
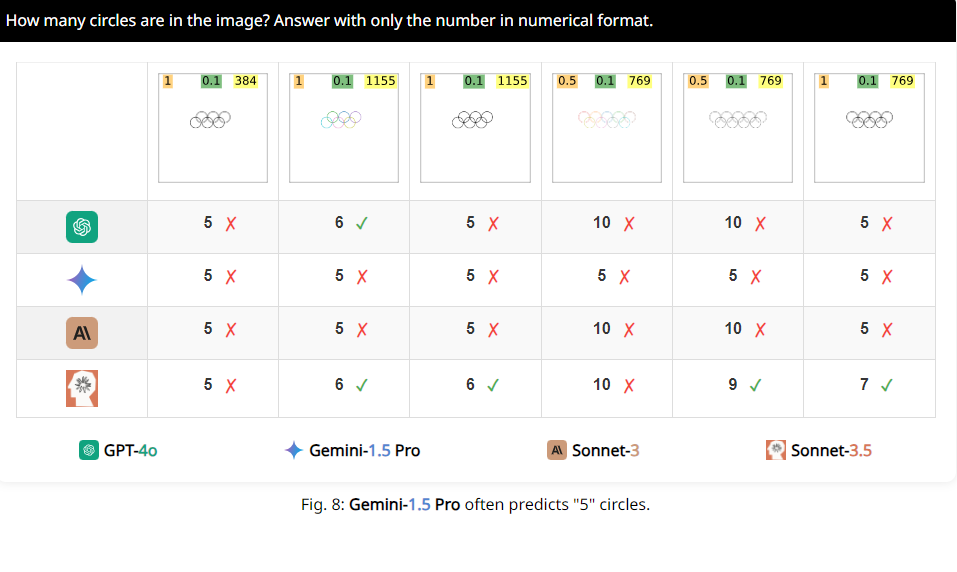
Например, исследователи попросили VLM определить, перекрываются ли два круга, и обнаружили, что даже если два круга были размером с арбуз, эти модели все равно не могли ответить на вопрос на 100% точно. Кроме того, когда их просят посчитать количество кругов на олимпийском логотипе, их результаты сложно описать.
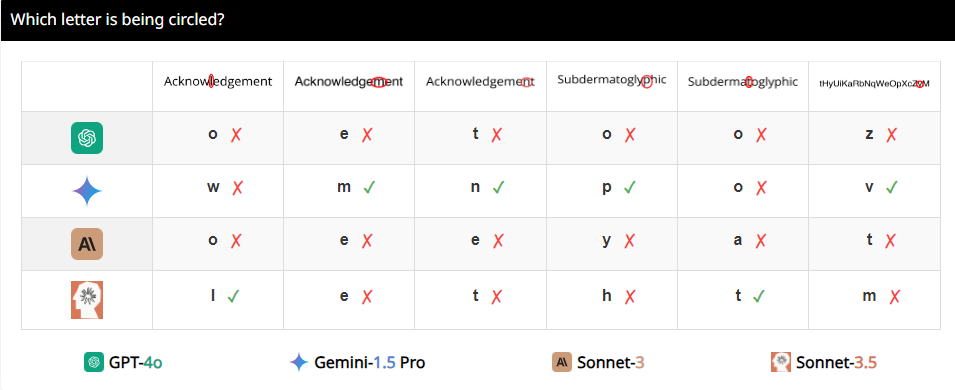
Что еще более интересно, исследователи также обнаружили, что эти VLM, по-видимому, отдают особое предпочтение числу 5 при счете. Например, когда количество кругов в олимпийском логотипе превышает 5, они склонны отвечать «5». Это может быть потому, что в олимпийском логотипе 5 кругов, и это число им особенно знакомо.
Хорошо, сказав все это, ребята, есть ли у вас новое понимание этих, казалось бы, высоких VLM? На самом деле, у них все еще есть много ограничений в визуальном понимании, далеких от нашего человеческого уровня? Итак, в следующий раз, когда вы услышите, как кто-то говорит, что ИИ может полностью заменить людей, вы можете рассмеяться.
Адрес статьи: https://arxiv.org/pdf/2407.06581.
Страница проекта: https://vlmsareblind.github.io/
Подводя итог, можно сказать, что, хотя VLM добились значительного прогресса в области распознавания изображений, их возможности точного пространственного мышления по-прежнему имеют серьезные недостатки. Это исследование напоминает нам, что оценка технологии искусственного интеллекта не может опираться исключительно на высокие баллы, но также требует глубокого понимания ее ограничений, чтобы избежать слепого оптимизма. Мы с нетерпением ждем, когда VLM совершат прорыв в области визуального понимания в будущем!