Редактор Downcodes познакомит вас с революционным исследованием Google DeepMind: Mixture of Experts (MoE). Это исследование привело к революционному прогрессу в архитектуре Transformer. Его суть заключается в эффективном по параметрам механизме экспертного поиска, который использует технологию ключей продукта для балансировки вычислительных затрат и количества параметров, тем самым значительно улучшая потенциал модели при сохранении эффективности. Это исследование не только изучает экстремальные условия Министерства образования, но и впервые доказывает, что структуру индекса обучения можно эффективно передать более чем миллиону экспертов, открывая новые возможности в области искусственного интеллекта.
Модель Mixture с участием миллиона экспертов, предложенная Google DeepMind, представляет собой исследование, предпринявшее революционные шаги в архитектуре Transformer.
Представьте себе модель, которая может выполнять разреженный поиск информации от миллиона микроэкспертов. Звучит ли это немного как сюжет научно-фантастического романа? Но именно это показывают последние исследования DeepMind. Ядром этого исследования является механизм экспертного поиска с эффективным использованием параметров, который использует технологию ключей продукта для отделения вычислительных затрат от количества параметров, тем самым раскрывая больший потенциал архитектуры Transformer, сохраняя при этом вычислительную эффективность.
Изюминкой этой работы является то, что она не только исследует экстремальные условия МО, но и впервые демонстрирует, что изученную структуру индекса можно эффективно передать более чем миллиону экспертов. Это похоже на быстрый поиск нескольких экспертов, способных решить проблему в огромной толпе, и все это делается при условии контролируемых вычислительных затрат.
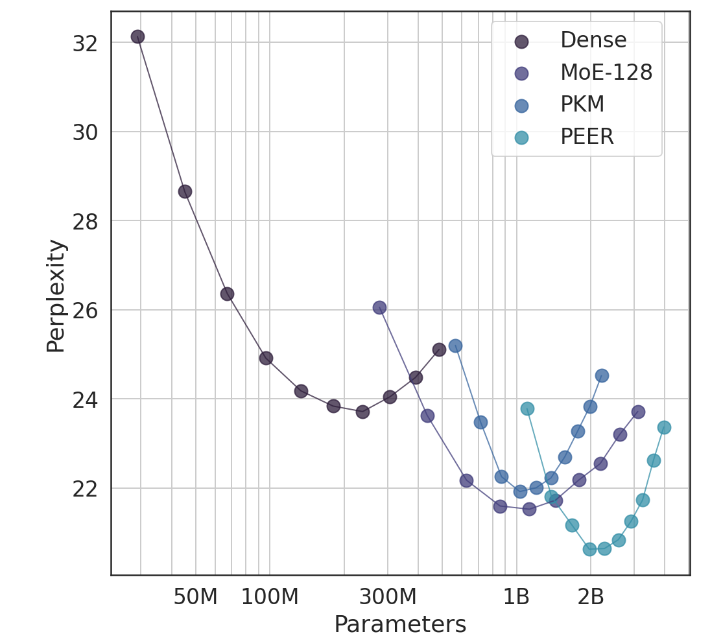
В экспериментах архитектура PEER продемонстрировала превосходную вычислительную производительность и была более эффективной, чем плотные уровни FFW, крупнозернистый MoE и уровни памяти ключа продукта (PKM). Это не только теоретическая победа, но и огромный скачок в практическом применении. Благодаря эмпирическим результатам мы можем видеть превосходную производительность PEER в задачах языкового моделирования. Он не только имеет меньшую запутанность, но и в эксперименте по удалению, регулируя количество экспертов и количество активных экспертов, производительность PEER. модель была значительно улучшена.
Автор этого исследования, Сюй Хэ (Оуэн), является научным сотрудником Google DeepMind. Его исследование в одиночку, несомненно, принесло новые открытия в области искусственного интеллекта. Как он показал, с помощью персонализированных и интеллектуальных методов мы можем значительно улучшить показатели конверсии и удержать пользователей, что особенно важно в сфере AIGC.
Адрес статьи: https://arxiv.org/abs/2407.04153
В целом, исследование гибридной модели Google DeepMind, в котором участвуют миллионы экспертов, дает новые идеи для построения крупномасштабных языковых моделей. Его эффективный механизм экспертного поиска и отличные экспериментальные результаты указывают на большой потенциал для будущей разработки моделей ИИ. Редактор Downcodes с нетерпением ждет новых подобных революционных результатов исследований!