В последние годы инновации в моделях больших языков (LLM) появлялись одна за другой, постоянно бросая вызов ограничениям существующих архитектур. Редактор Downcodes узнал, что исследователи из Стэнфорда, Калифорнийского университета в Беркли и Meta совместно предложили новую архитектуру под названием TTT (уровни тестирования и обучения). Ожидается, что ее революционный дизайн полностью изменит наше понимание языка. Модель признана и применяется. Умело сочетая преимущества RNN и Transformer, архитектура TTT значительно улучшает выразительные возможности модели, обеспечивая при этом линейную сложность. Она особенно хорошо работает при обработке длинных текстов, открывая новые возможности в таких областях, как моделирование длинных видео.
В мире искусственного интеллекта перемены всегда происходят неожиданно. Совсем недавно появилась новая архитектура под названием TTT. Она была совместно предложена исследователями из Стэнфорда, Калифорнийского университета в Беркли и Meta. Она в одночасье разрушила Transformer и Mamba и внесла революционные изменения в языковые модели.
TTT, полное название слоев Test-Time-Training, представляет собой совершенно новую архитектуру, которая сжимает контекст посредством градиентного спуска и напрямую заменяет традиционный механизм внимания. Этот подход не только повышает эффективность, но и открывает архитектуру линейной сложности с выразительной памятью, что позволяет нам обучать LLM, содержащие миллионы или даже миллиарды токенов в контексте.

Предложение уровня TTT основано на глубоком понимании существующих архитектур RNN и Transformer. Хотя RNN очень эффективен, он ограничен своими выразительными возможностями, в то время как Transformer обладает сильными выразительными возможностями, но его вычислительные затраты растут линейно с длиной контекста; Уровень TTT умело сочетает в себе преимущества обоих, сохраняя линейную сложность и расширяя выразительные возможности.
В экспериментах оба варианта, TTT-Linear и TTT-MLP, продемонстрировали отличную производительность, превосходя Transformer и Mamba как в коротком, так и в длинном контексте. Преимущества уровня TTT более очевидны, особенно в сценариях с длинным контекстом, что обеспечивает огромный потенциал для сценариев применения, таких как моделирование длинного видео.
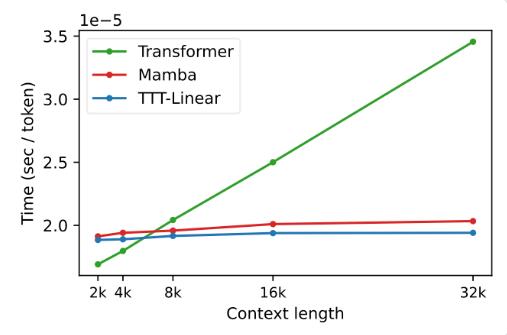
Предложение уровня ТТТ не только является инновационным в теории, но и демонстрирует большой потенциал в практическом применении. Ожидается, что в будущем уровень TTT будет применяться к моделированию длинных видео, чтобы предоставлять более полную информацию за счет плотной выборки кадров. Это бремя для преобразователя, но это благо для уровня TTT.
Это исследование является результатом пятилетней напряженной работы команды и назревало с момента постдокторской деятельности доктора Ю Суня. Они упорно исследовали и пытались и, наконец, достигли этого революционного результата. Успех слоя ТТТ является результатом неустанных усилий команды и новаторского духа.
Появление уровня ТТТ принесло новую жизнь и возможности в область искусственного интеллекта. Это не только меняет наше понимание языковых моделей, но и открывает новый путь для будущих приложений ИИ. Давайте с нетерпением ждем будущего применения и развития уровня TTT и станем свидетелями прогресса и прорывов в области технологий искусственного интеллекта.
Адрес статьи: https://arxiv.org/abs/2407.04620.
Появление архитектуры TTT, несомненно, дало импульс развитию области искусственного интеллекта. Ее революционный прогресс в обработке длинных текстов указывает на то, что будущие приложения искусственного интеллекта будут иметь более мощные возможности обработки и более широкие перспективы применения. Давайте подождем и посмотрим, как архитектура ТТТ еще больше изменит наш мир.