Редактор Downcodes приносит вам большие новости! Компания Cerebras Systems запустила самый быстрый в мире сервис вывода ИИ — Cerebras Inference, который полностью изменил правила игры в области вывода ИИ благодаря своей удивительной скорости и чрезвычайно конкурентоспособной цене. Он хорошо работает при обработке различных моделей искусственного интеллекта, особенно моделей больших языков (LLM), и в 20 раз быстрее, чем традиционные системы графических процессоров, при цене всего в одну десятую или даже сотую долю. Как это повлияет на будущее развитие приложений ИИ? Давайте посмотрим поближе.
Cerebras Systems, пионер в области высокопроизводительных вычислений на базе искусственного интеллекта, представила революционное решение, которое произведет революцию в выводах искусственного интеллекта. 27 августа 2024 года компания объявила о запуске Cerebras Inference, самой быстрой в мире службы вывода ИИ. Показатели производительности Cerebras Inference превосходят традиционные системы на базе графических процессоров, обеспечивая в 20 раз большую скорость при чрезвычайно низкой цене, устанавливая новый стандарт для вычислений с использованием искусственного интеллекта.
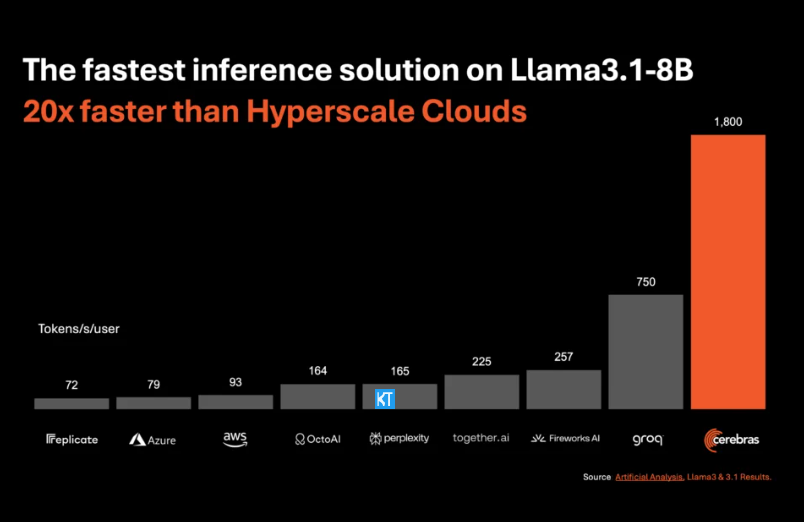
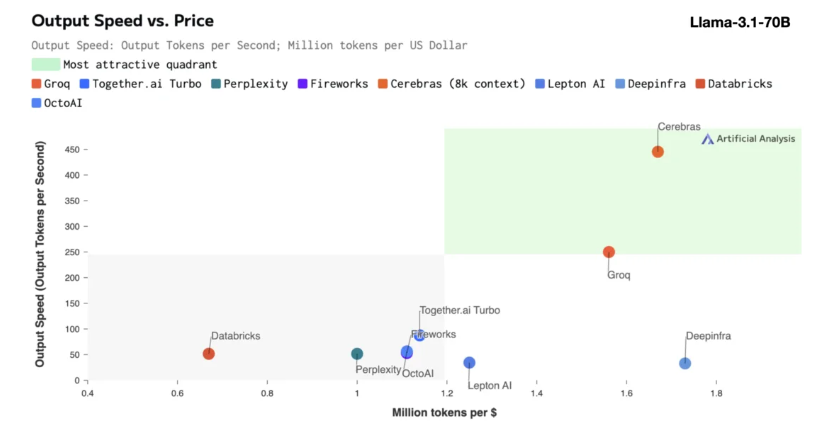
Вывод Cerebras особенно подходит для обработки различных типов моделей ИИ, особенно быстро развивающихся «больших языковых моделей» (LLM). Если взять в качестве примера последнюю модель Llama3.1, ее версия 8B может обрабатывать 1800 токенов в секунду, а версия 70B — 450 токенов. Это не только в 20 раз быстрее, чем решения NVIDIA GPU, но и более конкурентоспособно по цене. Цена Cerebras Inference начинается всего с 10 центов за миллион токенов, а версия 70B — с 60 центов. По сравнению с существующими продуктами на основе графических процессоров соотношение цена/производительность улучшено в 100 раз.
Впечатляет, что Cerebras Inference достигает такой скорости, сохраняя при этом лучшую в отрасли точность. В отличие от других решений, ориентированных на скорость, Cerebras всегда выполняет вывод в 16-битной области, гарантируя, что повышение производительности не происходит за счет качества вывода модели ИИ. Миша Хилл-Смит, генеральный директор Artificial Analytics, заявил, что Cerebras достигла скорости вывода более 1800 токенов в секунду на модели Llama3.1 от Meta, установив новый рекорд.
Вывод ИИ — самый быстрорастущий сегмент ИИ-вычислений, на который приходится около 40% всего рынка аппаратного обеспечения ИИ. Высокоскоростной вывод ИИ, такой как тот, который обеспечивает Cerebras, подобен появлению широкополосного Интернета, открывая новые возможности и открывая новую эру для приложений ИИ. Разработчики могут использовать Cerebras Inference для создания приложений искусственного интеллекта следующего поколения, которым требуется сложная производительность в реальном времени, таких как интеллектуальные агенты и интеллектуальные системы.
Cerebras Inference предлагает три недорогих уровня обслуживания: бесплатный уровень, уровень разработчика и корпоративный уровень. Уровень бесплатного пользования обеспечивает доступ к API с большими ограничениями на использование, что делает его идеальным для широкого круга пользователей. Уровень разработчика предоставляет гибкие варианты бессерверного развертывания, а уровень предприятия предоставляет индивидуальные услуги и поддержку для организаций с непрерывными рабочими нагрузками.
Что касается базовой технологии, Cerebras Inference использует систему CerebrasCS-3, управляемую ведущим в отрасли Wafer Scale Engine3 (WSE-3). Этот процессор искусственного интеллекта не имеет себе равных по масштабу и скорости: он обеспечивает в 7000 раз большую пропускную способность памяти, чем NVIDIA H100.
Cerebras Systems не только лидирует в области вычислений с использованием искусственного интеллекта, но также играет важную роль во многих отраслях, таких как медицина, энергетика, правительство, научные вычисления и финансовые услуги. Постоянно продвигая технологические инновации, Cerebras помогает организациям в различных областях решать сложные проблемы искусственного интеллекта.
Выделять:
Скорость обслуживания Cerebras Systems увеличена в 20 раз, цена более конкурентоспособна, и это открывает новую эру рассуждений ИИ.
Поддерживает различные модели искусственного интеллекта, особенно хорошо работает на больших языковых моделях (LLM).
Предусмотрено три уровня обслуживания, чтобы разработчики и корпоративные пользователи могли гибко выбирать.
В целом, появление Cerebras Inference знаменует собой важную веху в области вывода ИИ. Его превосходная производительность и экономичность будут способствовать широкой популяризации и инновационному развитию приложений ИИ, и он заслуживает внимания и ожиданий со стороны отрасли. Редактор Downcodes продолжит предоставлять вам больше информации о передовых технологиях.