Сегодня, с быстрым развитием технологий искусственного интеллекта, модели малого языка (SLM) привлекли большое внимание благодаря их способности работать на устройствах с ограниченными ресурсами. Команда Nvidia недавно выпустила Llama-3.1-Minitron4B, отличную модель малого языка, основанную на сжатии модели Llama 3. Он использует технологии сокращения и дистилляции моделей, чтобы конкурировать с более крупными моделями по производительности, обеспечивая при этом преимущества эффективного обучения и развертывания, открывая новые возможности для приложений искусственного интеллекта. Редактор Downcodes поможет вам глубже понять этот технологический прорыв.
В эпоху, когда технологические компании гоняются за искусственным интеллектом на устройствах, появляется все больше и больше моделей малых языков (SLM), которые могут работать на устройствах с ограниченными ресурсами. Недавно исследовательская группа Nvidia использовала передовые технологии обрезки и дистилляции моделей для запуска Llama-3.1-Minitron4B, сжатой версии модели Llama3. Эта новая модель не только сравнима по производительности с более крупными моделями, но и конкурирует с меньшими моделями того же размера, будучи более эффективной в обучении и развертывании.
Очистка и дистилляция — два ключевых метода создания меньших по размеру и более эффективных языковых моделей. Под обрезкой подразумевается удаление неважных частей модели, включая «обрезку по глубине» — удаление целых слоев и «обрезку по ширине» — удаление определенных элементов, таких как нейроны и центры внимания. С другой стороны, дистилляция модели переносит знания и способности из большой модели (т. е. «модели учителя») в меньшую и более простую «модель ученика».
Существует два основных метода дистилляции. Первый - это «обучение SGD», которое позволяет модели ученика изучить входные данные и реакцию модели учителя. Второй - «дистилляция классических знаний». Здесь, помимо результатов обучения, есть два основных метода дистилляции. модель ученика также требует внутренней активации модели обучающегося учителя.
В предыдущем исследовании исследователи Nvidia успешно сократили модель Nemotron15B до модели с 800 миллионами параметров посредством обрезки и дистилляции, а затем еще больше сократили ее до 400 миллионов параметров. Этот процесс не только повышает производительность на 16% по знаменитому тесту MMLU, но и требует в 40 раз меньше обучающих данных, чем обучение с нуля.
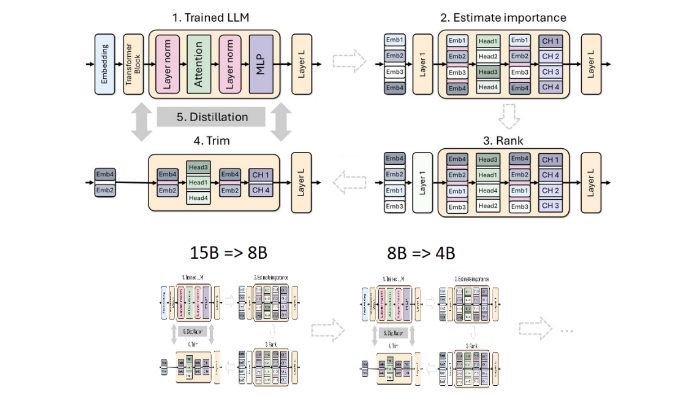
На этот раз команда Nvidia использовала тот же метод для создания модели с 400 миллионами параметров на основе модели Llama3.18B. Во-первых, они настроили необрезанную модель 8B на наборе данных, содержащем 94 миллиарда токенов, чтобы справиться с различиями в распределении между обучающими данными и очищенным набором данных. Затем были использованы два метода обрезки по глубине и по ширине, и в итоге были получены две разные версии Llama-3.1-Minitron4B.
Исследователи настроили сокращенную модель с помощью NeMo-Aligner и оценили ее возможности в следовании инструкциям, ролевых играх, генерации дополнений поиска (RAG) и вызове функций.
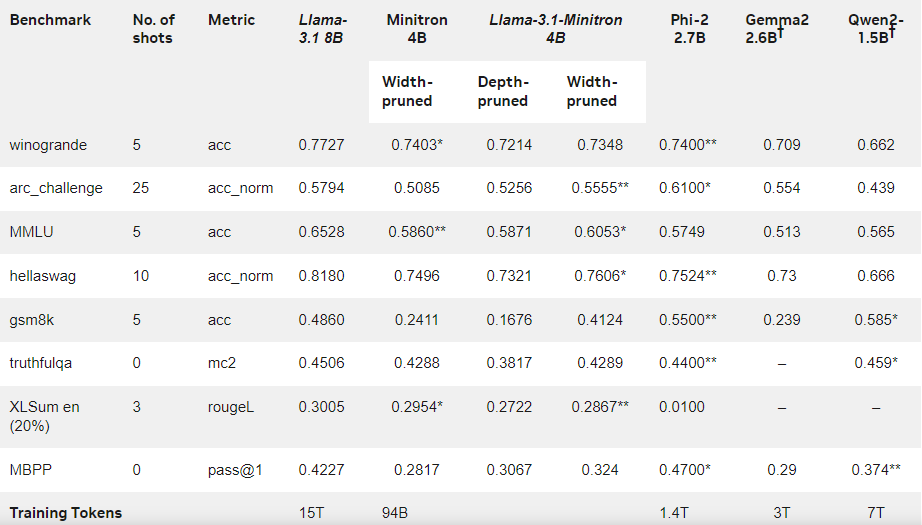
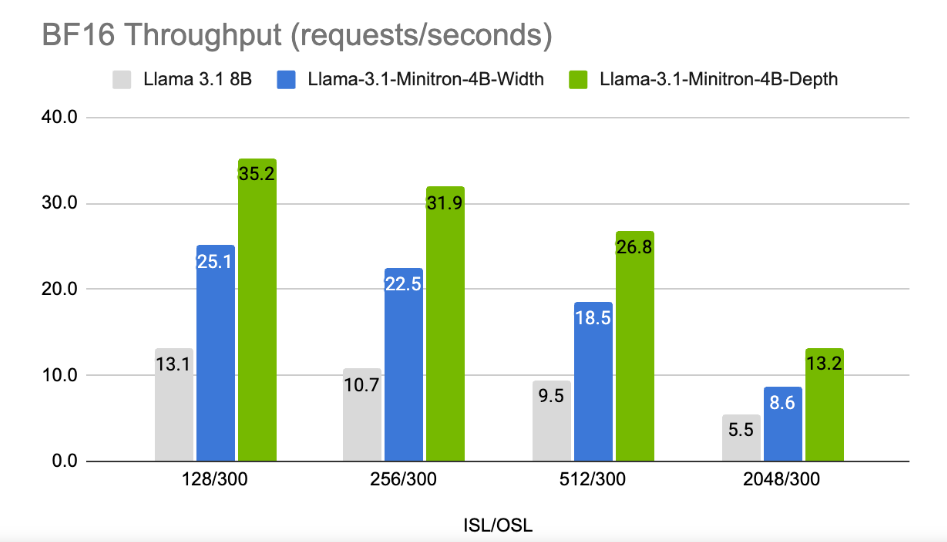
Результаты показывают, что, несмотря на небольшой объем обучающих данных, производительность Llama-3.1-Minitron4B по-прежнему близка к другим небольшим моделям и работает хорошо. Версия модели с урезанной шириной была выпущена на Hugging Face, что позволяет использовать ее в коммерческих целях, чтобы помочь большему количеству пользователей и разработчиков извлечь выгоду из ее эффективности и превосходной производительности.
Официальный блог: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
Выделять:
Llama-3.1-Minitron4B — это небольшая языковая модель, выпущенная Nvidia на основе технологии сокращения и дистилляции, с эффективными возможностями обучения и развертывания.
Количество маркеров, используемых в процессе обучения этой модели, уменьшено в 40 раз по сравнению с обучением с нуля, но производительность значительно улучшена.
? Версия с обрезкой ширины была выпущена на Hugging Face, чтобы облегчить пользователям коммерческое использование и разработку.
В целом, появление Llama-3.1-Minitron4B знаменует собой новую веху в разработке малых языковых моделей. Его эффективная производительность и удобный метод развертывания принесут хорошие новости большему количеству разработчиков и пользователей и ускорят популяризацию и применение технологии искусственного интеллекта. Редактор Downcodes надеется на появление новых подобных нововведений в будущем.