Редактор Downcodes знакомит вас с интересным экспериментом с искусственным интеллектом: пользователь Reddit @zefman создал платформу, позволяющую различным языковым моделям (LLM) играть в шахматы в реальном времени! Этот эксперимент оценивает способность каждого LLM играть в шахматы непринужденно и интересно. Результаты неожиданны, давайте посмотрим!
Недавно пользователь Reddit @zefman провел интересный эксперимент, создав платформу для сопоставления различных языковых моделей (LLM) с шахматами в режиме реального времени, с целью предоставить пользователям интересный и простой способ оценить производительность этих моделей.
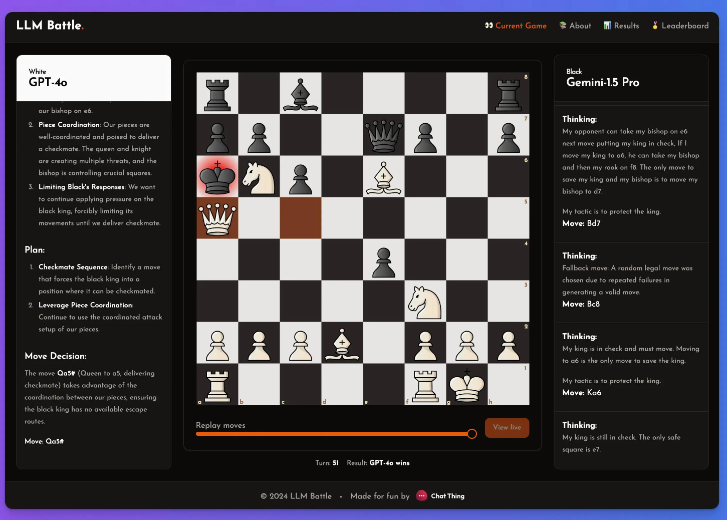
Ни для кого не секрет, что эти модели не очень хороши в игре в шахматы, но даже в этом случае он чувствовал, что в этом эксперименте есть некоторые примечательные моменты.
В этом эксперименте @zefman уделил особое внимание нескольким последним моделям, среди которых GPT-4o показал себя лучше всего и, без сомнения, стал самым сильным игроком. В то же время @zefman также сравнил ее с другими моделями, такими как Claude и Gemini, чтобы увидеть различия в их производительности, и обнаружил, что процесс мышления и рассуждения каждой модели очень интересен. С помощью этой платформы каждый может увидеть, как принимаются решения на каждом этапе и как модель анализирует шахматную игру.
Метод отображения шахматной игры, разработанный @zefman, довольно прост. Когда каждая модель сталкивается с одним и тем же состоянием шахматной доски, она выдает одинаковые подсказки, включая текущее состояние шахматной игры, FEN (представление шахматной позиции) и два предыдущих хода. Такой подход гарантирует, что решения каждой модели основаны на одной и той же информации, что обеспечивает более справедливое сравнение.
Каждая модель использует одну и ту же подсказку, которая обновляется в зависимости от статуса доски в ASCI, FEN, а также двух предыдущих ходов и мыслей. Вот пример:
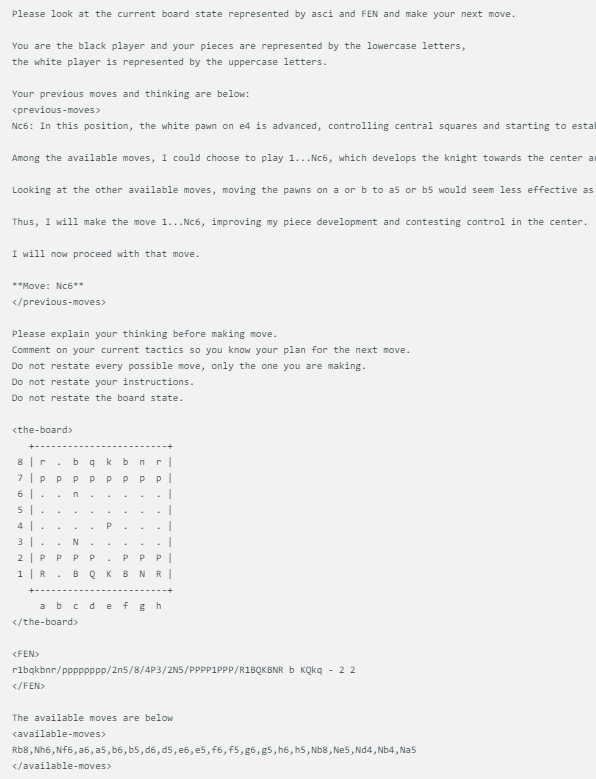
Кроме того, @zefman также заметил, что в некоторых случаях, особенно для некоторых более слабых моделей, они могут несколько раз выбирать неправильный ход. Чтобы решить эту проблему, он дал этим моделям 5 возможностей для повторного выбора. Если им по-прежнему не удавалось выбрать правильный ход, они случайным образом выбирали правильный ход, тем самым продолжая игру.
Он заключил: GTP-4o по-прежнему сильнейший, обыграв в шахматы Gemini1.5pro.
Благодаря этому эксперименту мы не только увидели различия между разными LLM в области шахмат, но также увидели гениальный замысел и экспериментальный дух @zefman. С нетерпением ждем новых подобных экспериментов в будущем, которые дадут нам более глубокое понимание потенциала и ограничений LLM!