Последний проект Meta AI Llama3 привлек широкое внимание. Редактор Downcodes даст вам глубокое понимание его основной технологии и будущего направления развития. Исследователь мета-ИИ Томас Сьялом недавно дал интервью, в котором поделился подробностями разработки Llama3 и предоставил уникальную информацию о проблемах, существующих при крупномасштабном обучении языковых моделей. Он особенно подчеркнул важную роль синтетических данных в обучении Llama3 и то, как эффективно использовать обратную связь от людей для улучшения производительности модели. В этой статье подробно объясняются методы обучения, области применения и планы дальнейшего развития Llama3, представляя читателям всестороннюю и глубокую перспективу.
Томас Сиалом, исследователь из Meta AI, недавно поделился в интервью некоторыми мыслями об их последнем проекте Llama3. Он прямо указывает на то, что большие объемы текста в сети разного качества, и считает, что обучение на этих данных — пустая трата ресурсов. Таким образом, процесс обучения Llama3 не опирается на какие-либо ответы, написанные человеком, а полностью основан на синтетических данных, генерируемых Llama2.
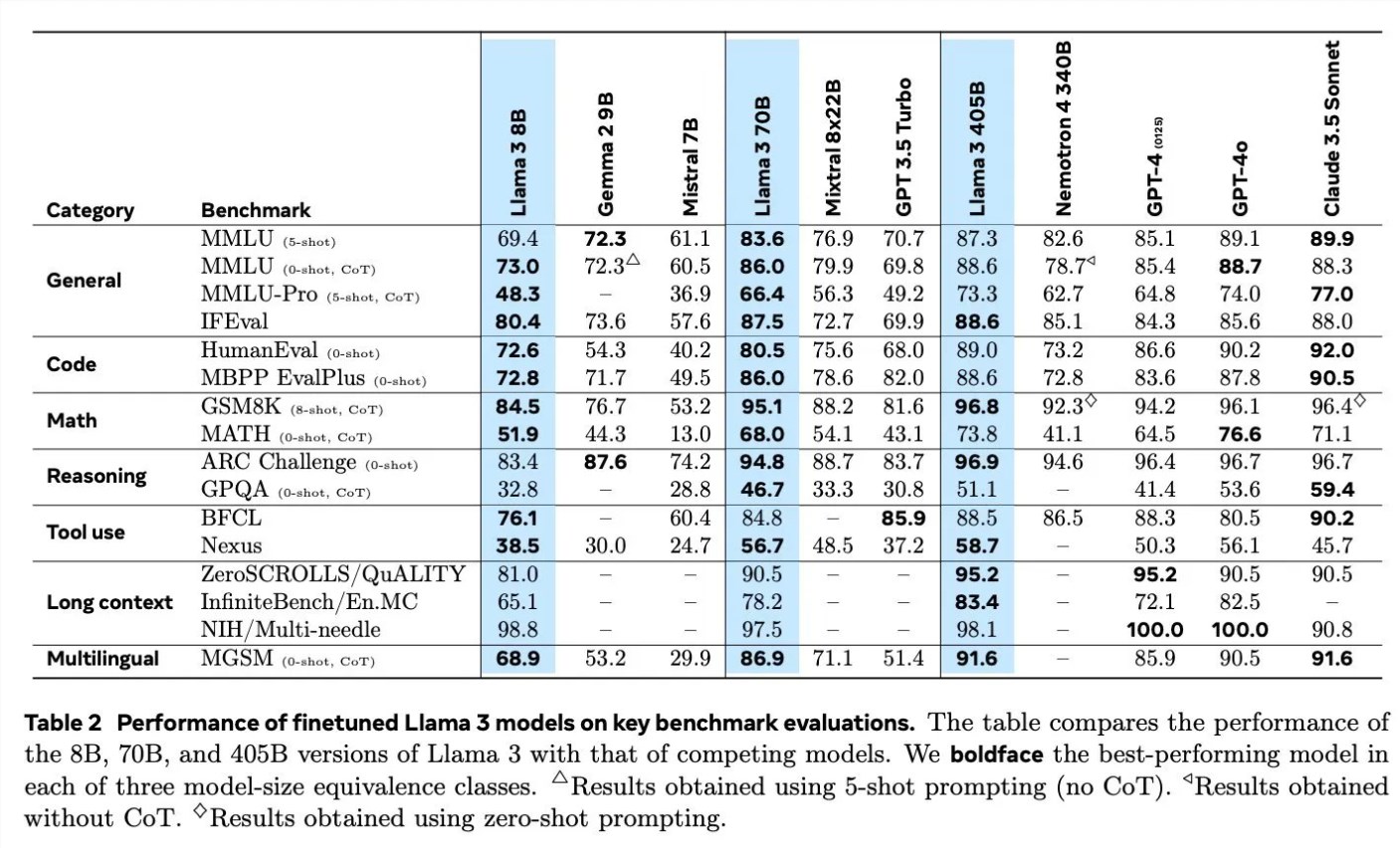
Обсуждая детали обучения Llama3, Scialom подробно рассказал о применении синтетических данных в различных областях. Например, что касается генерации кода, они использовали три разных метода для генерации синтетических данных, включая обратную связь от выполнения кода, перевод языков программирования и обратный перевод документации. Что касается математических рассуждений, они использовали исследовательский подход «давайте шаг за шагом» к генерированию данных. Кроме того, Llama3 продолжает предварительно обучаться с использованием 90% многоязычных токенов для сбора высококачественных человеческих аннотаций, что особенно важно при многоязычной обработке.
Обработка длинного текста также является основной задачей Llama3, и они полагаются на синтетические данные для обработки ответов на длинные текстовые вопросы, обобщения длинных документов и вывода базы кода. Что касается использования инструментов, Llama3 прошла обучение на Brave search, Wolfram Alpha и интерпретаторах Python для реализации одиночных, вложенных, параллельных и многораундовых вызовов функций.
Scialom также упомянул важность обучения с подкреплением и обратной связью от человека (RLHF) при обучении Llama3. Они широко использовали данные о предпочтениях людей для обучения модели, подчеркивая способность людей делать выбор (например, выбирать, какое из двух стихотворений предпочесть), а не начинать с нуля.
Meta начала обучение Llama4 в июне, и Scialom сообщил, что основное внимание Llama4 будет сосредоточено на интеллектуальном агенте. Кроме того, он также упомянул мультимодальную версию Llama, которая будет иметь больше параметров и которую планируется выпустить в ближайшее время.
Интервью Scialom раскрывает последние достижения Meta AI и будущие направления развития в области искусственного интеллекта, особенно в том, как использовать синтетические данные и отзывы людей для улучшения производительности моделей.
Из интервью Scialom мы узнали об инновациях Llama3 в использовании данных и обучении моделей, а также о продолжающихся исследованиях Meta AI в области крупномасштабных языковых моделей. Успешный опыт Llama3 предоставляет ценную информацию для разработки будущих моделей искусственного интеллекта, а также указывает на то, что технология искусственного интеллекта будет развиваться в более точном и эффективном направлении. Редактор Downcodes с нетерпением ждет выхода Llama4 и мультимодальной Llama и продолжает обращать внимание на прорывной прогресс Meta AI в области искусственного интеллекта.