Большой релиз Meta Company! Открыт исходный код своей последней модели большого языка Llama 3.1 405B с объемом параметров до 128 миллиардов, а ее производительность сравнима с GPT-4 в нескольких задачах. После года тщательной подготовки, от планирования проекта до окончательной проверки, модели серии Llama 3 наконец-то предстают перед публикой. Этот открытый исходный код включает не только саму модель, но также ее оптимизированную обработку данных перед обучением, контроль качества данных после обучения и эффективную технологию количественного анализа, позволяющую снизить требования к вычислительным ресурсам и упростить использование разработчиками. Редактор Downcodes подробно объяснит улучшения и особенности Llama 3.1 405B.
Вчера вечером Meta объявила об открытом исходном коде своей последней модели большого языка Llama3.1 405B. Эта важная новость означает, что после года тщательной подготовки, от планирования проекта до окончательного обзора, модели серии Llama3 наконец-то представлены публике.
Llama3.1405B — это многоязычная модель использования инструмента со 128 миллиардами параметров. После предварительного обучения с длиной контекста 8 КБ модель дополнительно обучается с длиной контекста 128 КБ. По данным Meta, производительность этой модели при выполнении нескольких задач сравнима с ведущей в отрасли GPT-4.
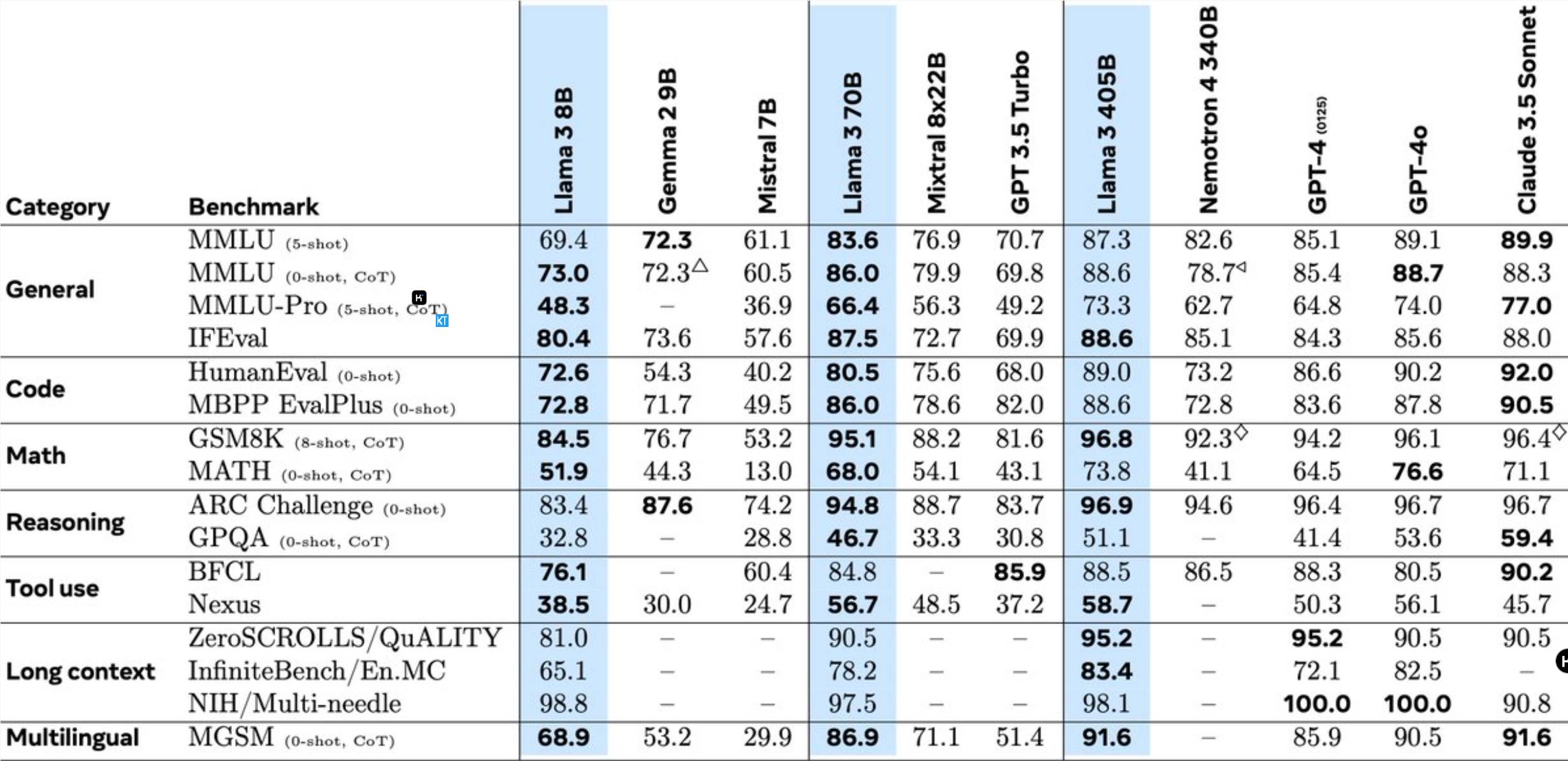
По сравнению с предыдущей моделью Llama Meta была оптимизирована во многих аспектах:
Предварительное обучение модели 405B — это огромная задача, включающая 15,6 триллионов токенов и 3,8x10^25 операций с плавающей запятой. С этой целью Meta оптимизировала всю архитектуру обучения и использовала более 16 000 графических процессоров H100.
Чтобы поддержать массовое производство модели 405B, Meta квантовала ее с 16-битного (BF16) до 8-битного (FP8), что значительно снизило вычислительные требования и позволило одному серверному узлу запускать модель.
Кроме того, Meta использует модель 405B для улучшения качества моделей 70B и 8B после обучения. На этапе после обучения команда усовершенствовала модель чата с помощью нескольких этапов согласования, включая контролируемую точную настройку (SFT), выборку отклонений и прямую оптимизацию предпочтений. Стоит отметить, что большинство выборок SFT создаются с использованием синтетических данных.
Llama3 также объединяет функции изображения, видео и голоса, используя комбинированный подход, позволяющий модели распознавать изображения и видео и поддерживать голосовое взаимодействие. Однако эти функции все еще находятся в стадии разработки и еще не были официально выпущены.
Meta также обновила свое лицензионное соглашение, чтобы позволить разработчикам использовать результаты модели Llama для улучшения других моделей.
Исследователи из Meta заявили: «Чрезвычайно интересно работать в авангарде ИИ с лучшими талантами отрасли и публиковать результаты исследований открыто и прозрачно». Мы с нетерпением ждем возможности увидеть инновации, которые приносят модели с открытым исходным кодом, и потенциал будущих моделей серии Llama!
Эта инициатива с открытым исходным кодом, несомненно, принесет новые возможности и вызовы в области искусственного интеллекта и будет способствовать дальнейшему развитию технологии больших языковых моделей.
Открытый исходный код Llama 3.1 405B будет в значительной степени способствовать развитию технологии больших языковых моделей и предоставит больше возможностей в области искусственного интеллекта. Мы с нетерпением ждем, когда разработчики создадут еще больше потрясающих приложений на основе этой модели!