Повышение эффективности больших языковых моделей всегда было горячей точкой исследований в области искусственного интеллекта. Недавно исследовательские группы из Алеф Альфа, Технического университета Дармштадта и других учреждений разработали новый метод под названием T-FREE, который значительно повышает эффективность работы больших языковых моделей. Этот метод уменьшает количество параметров слоя внедрения за счет использования троек символов для разреженной активации и эффективно моделирует морфологическое сходство между словами. Он значительно снижает потребление вычислительных ресурсов, обеспечивая при этом производительность модели. Эта революционная технология открывает новые возможности для применения больших языковых моделей.
Исследовательская группа недавно представила новый потрясающий метод под названием T-FREE, который позволяет резко повысить эффективность работы больших языковых моделей. Ученые из Алеф Альфа, Технического университета Дармштадта, hessian.AI и Немецкого исследовательского центра искусственного интеллекта (DFKI) совместно запустили эту удивительную технологию, полное название которой — «Разреженное представление без таггеров, возможно эффективное встраивание с использованием памяти».
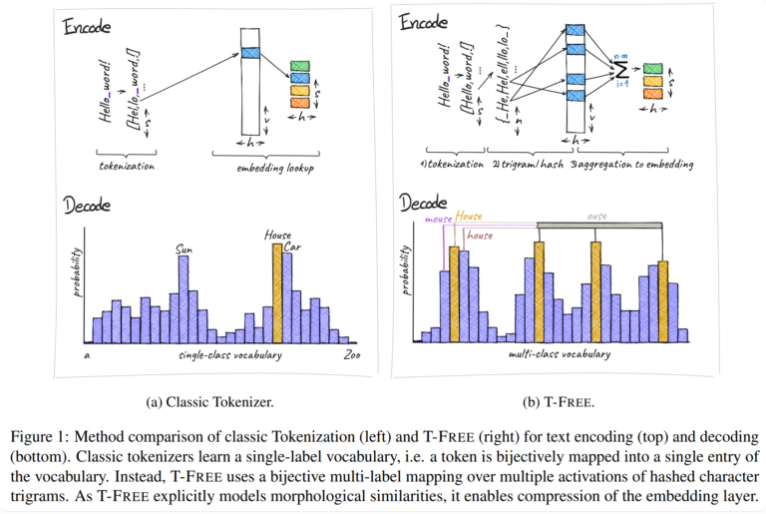
Традиционно мы используем токенизаторы для преобразования текста в числовую форму, понятную компьютерам, но T-FREE выбрал другой путь. Он использует тройки символов, которые мы называем «тройками», для встраивания слов непосредственно в модель посредством разреженной активации. В результате этого инновационного шага количество параметров на уровне внедрения сократилось на целых 85 % и более, при этом производительность модели совершенно не пострадала при выполнении таких задач, как классификация текста и ответы на вопросы.
Еще одной особенностью T-FREE является то, что он очень умело моделирует морфологическое сходство между словами. Точно так же, как слова «дом», «дома» и «домашний», с которыми мы часто сталкиваемся в повседневной жизни, T-FREE может более эффективно представлять эти похожие слова в модели. Исследователи считают, что похожие слова следует вставлять ближе друг к другу, чтобы добиться более высокой степени сжатия. Таким образом, T-FREE не только уменьшает размер слоя внедрения, но и уменьшает среднюю длину кодирования текста на 56%.
Стоит еще отметить, что T-FREE особенно хорошо справляется с переносом обучения между разными языками. В одном эксперименте исследователи использовали модель с 3 миллиардами параметров, обученную сначала на английском, а затем на немецком языке, и обнаружили, что T-FREE гораздо более адаптируем, чем традиционные методы, основанные на тегах.
Однако исследователи по-прежнему скромны в отношении своих текущих результатов. Они признают, что эксперименты до сих пор ограничивались моделями с числом параметров до 3 миллиардов, а в будущем планируются дальнейшие оценки более крупных моделей и больших наборов данных.
Появление метода T-FREE дает новые идеи по повышению эффективности больших языковых моделей. Его преимущества в снижении вычислительных затрат и повышении производительности модели заслуживают внимания. Будущие направления исследований будут сосредоточены на проверке крупномасштабных моделей и наборов данных для дальнейшего расширения сферы применения T-FREE и содействия дальнейшему развитию технологии крупномасштабных языковых моделей. Считается, что в ближайшем будущем T-FREE сыграет важную роль во многих областях.