Jina AI выпустила Reader-LM, облегченную языковую модель, специально разработанную для преобразования HTML в чистый Markdown. Он может эффективно удалять беспорядочный контент с веб-страниц, например рекламу и скрипты, для создания четко структурированных файлов Markdown без сложных регулярных выражений или ручных операций. Reader-LM доступен в двух версиях: Reader-LM-0.5B и Reader-LM-1.5B, обе из которых оптимизированы для эффективной работы даже в средах с ограниченными ресурсами и поддерживают контексты до 256 000 токенов.
Jina AI запустила две небольшие языковые модели, специально разработанные для преобразования исходного HTML-контента в чистый и аккуратный формат Markdown, что позволяет нам избавиться от утомительной обработки данных веб-страниц.
Самая большая особенность этой модели под названием Reader-LM заключается в том, что она может быстро и эффективно конвертировать веб-контент в файлы Markdown.
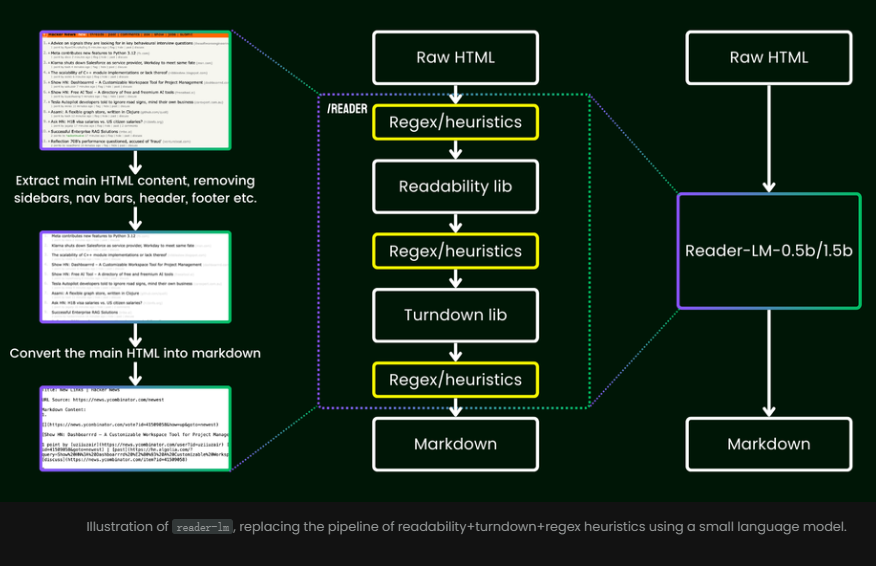
Преимущество его использования заключается в том, что вам больше не нужно полагаться на сложные правила или трудоемкие регулярные выражения. Эти модели разумно и автоматически удаляют с веб-страниц беспорядочный контент, такой как реклама, скрипты и панели навигации, и, наконец, представляют понятный и организованный формат Markdown.
«Ридер-ЛМ» предоставляет две модели с разными параметрами: «Ридер-ЛМ-0,5Б» и «Ридер-ЛМ-1,5Б». Хотя количество параметров этих двух моделей невелико, они оптимизированы для задачи преобразования HTML в Markdown. Результаты удивительны, а их производительность превосходит многие крупные языковые модели.
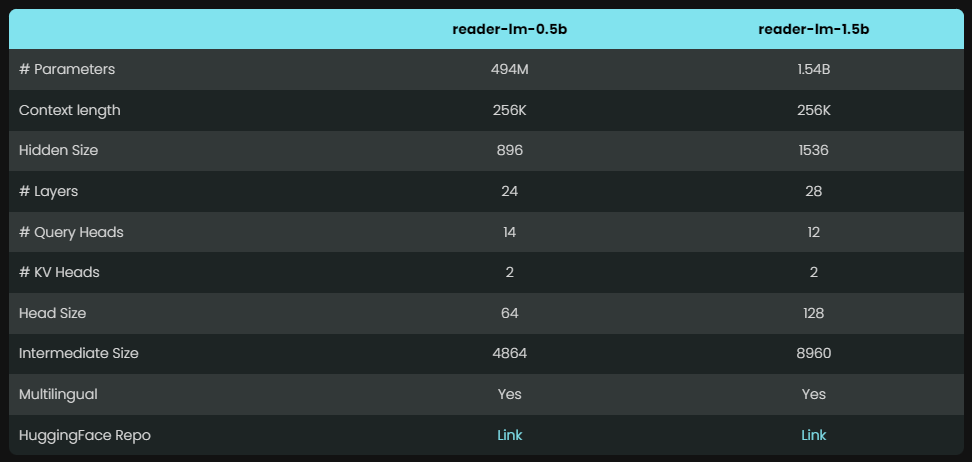
Благодаря компактной конструкции эти модели могут эффективно работать в условиях ограниченных ресурсов. Что еще более похвально, так это то, что Reader-LM не только поддерживает несколько языков, но также может обрабатывать контекстные данные размером до 256 000 токенов, что позволяет с легкостью обрабатывать даже сложные HTML-файлы.
В отличие от традиционных методов, основанных на регулярных выражениях или ручных настройках, Reader-LM предоставляет комплексное решение, которое автоматически очищает данные HTML и извлекает ключевую информацию.
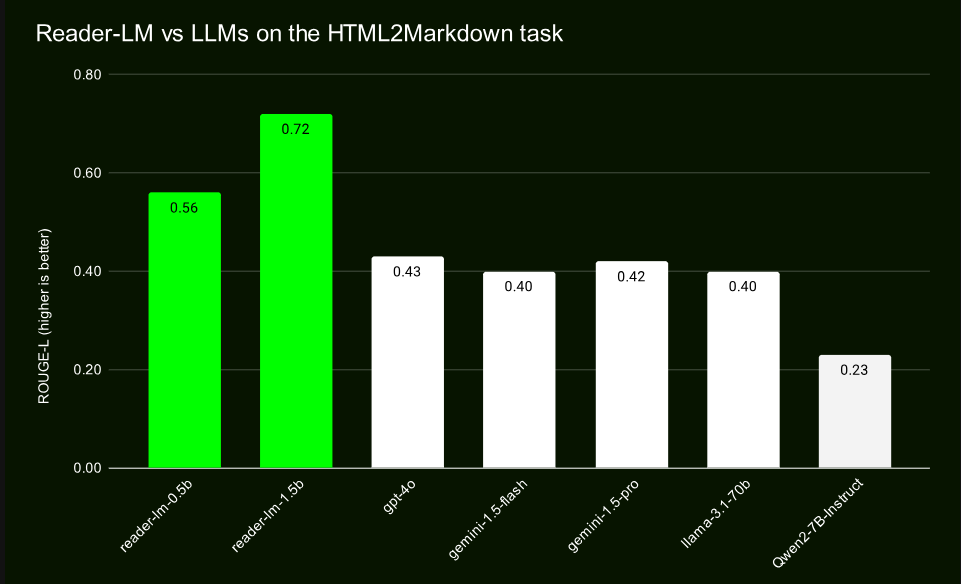
Благодаря сравнительному тестированию с крупномасштабными моделями, такими как GPT-4 и Gemini, Reader-LM продемонстрировал отличную производительность, особенно с точки зрения сохранения структуры и использования синтаксиса Markdown. Reader-LM-1.5B показывает особенно хорошие результаты по различным показателям: показатель ROUGE-L составляет 0,72, что свидетельствует о его высокой точности генерации контента, а уровень ошибок также значительно ниже, чем у аналогичных продуктов.
Благодаря компактной конструкции Reader-LM он меньше использует аппаратные ресурсы, особенно модель 0,5B, которая может бесперебойно работать в средах с низкой конфигурацией, таких как Google Colab. Несмотря на свой небольшой размер, Reader-LM по-прежнему обладает мощными возможностями обработки длинного контекста и может эффективно обрабатывать большой и сложный веб-контент без ущерба для производительности.
Что касается обучения, Reader-LM использует многоэтапный процесс и фокусируется на извлечении контента Markdown из оригинального и шумного HTML.
Процесс обучения включает в себя сопоставление большого количества реальных веб-страниц и синтетических данных, что обеспечивает эффективность и точность модели. После тщательно разработанного двухэтапного обучения Reader-LM постепенно улучшил свои возможности обработки сложных HTML-файлов и эффективно избежал проблемы повторной генерации.
Официальное введение: https://jina.ai/news/reader-lm-small-language-models-for-cleaning-and-converting-html-to-markdown/
В целом, Reader-LM представляет собой эффективное, удобное и точное решение для преобразования HTML в Markdown. Его легкий дизайн упрощает работу в различных средах, что делает его идеальным выбором для обработки данных веб-страниц. Для получения дополнительной информации посетите официальную ссылку.