Kunlun Technology недавно объявила, что две разработанные ею модели вознаграждений, Skywork-Reward-Gemma-2-27B и Skywork-Reward-Llama-3.1-8B, показали отличные результаты на RewardBench, причем модель 27B возглавила список. Это означает, что Kunlun Wanwei совершил крупный прорыв в области искусственного интеллекта, особенно в исследовании и разработке моделей вознаграждения, и предоставляет новую техническую поддержку для обучения большим языковым моделям. Модели вознаграждения имеют решающее значение в обучении с подкреплением, поскольку они могут направлять обучение модели и генерировать контент, который больше соответствует предпочтениям человека. Модель Куньлуня Ванвея обладает уникальными преимуществами при выборе данных и обучении модели, что позволяет ей хорошо работать в таких аспектах, как диалог и безопасность, и особенно демонстрирует сильные возможности при обработке сложных выборок.
Kunlun Wanwei Technology Co., Ltd. недавно объявила, что две новые модели вознаграждений, разработанные компанией, Skywork-Reward-Gemma-2-27B и Skywork-Reward-Llama-3.1-8B, хорошо зарекомендовали себя на RewardBench, всемирно авторитетной модели вознаграждений. Среди них модель Skywork-Reward-Gemma-2-27B заняла первое место и была высоко оценена официальными лицами RewardBench.
Модель вознаграждения занимает центральное место в обучении с подкреплением, оценивая производительность агента в различных состояниях и предоставляя сигналы вознаграждения для управления процессом обучения агента, чтобы он мог сделать оптимальный выбор в конкретной среде. При обучении больших языковых моделей модель вознаграждения играет особенно важную роль, помогая модели более точно понимать и генерировать контент, соответствующий предпочтениям человека.
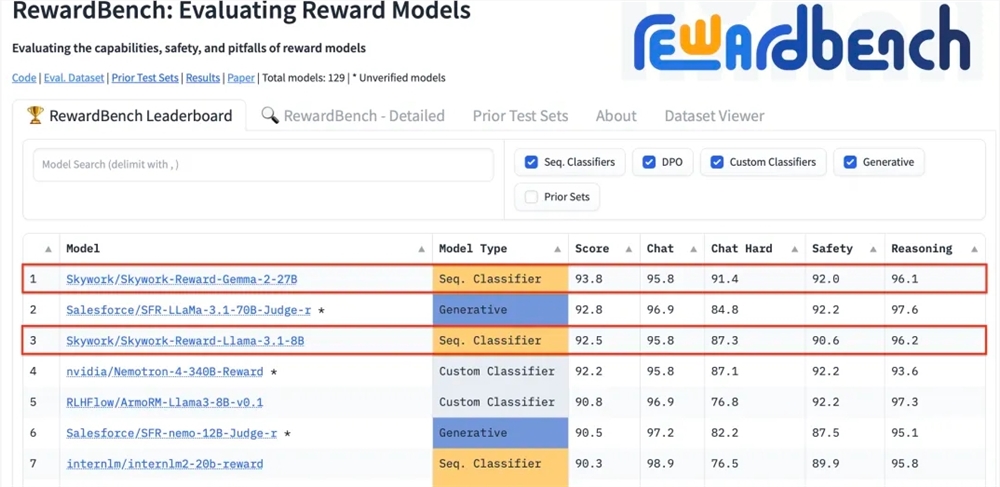
RewardBench — это список тестов, специально оценивающий эффективность моделей вознаграждения в больших языковых моделях. Он всесторонне оценивает модели с помощью множества задач, включая диалог, рассуждение и безопасность. Набор тестовых данных этого списка состоит из троек, состоящих из слов-подсказок, выбранных ответов и отклоненных ответов. Он используется для проверки того, может ли модель вознаграждения правильно ранжировать выбранные ответы среди отклоненных ответов с учетом слов-подсказок перед отклонением ответа. .
Модель Skywork-Reward от Kunlun Wanwei разработана на основе тщательно отобранных частично упорядоченных наборов данных и относительно небольших базовых моделей. По сравнению с существующими моделями вознаграждений, ее частично упорядоченные данные поступают только из общедоступных данных в Интернете и фильтруются с помощью специальных фильтров для получения высоких результатов. - наборы данных о предпочтениях качества. Данные охватывают широкий спектр тем, включая безопасность, математику и код, и проверяются вручную, чтобы обеспечить объективность данных и значимость пробелов в вознаграждении.
После тестирования модель вознаграждения Куньлунь Ванвэй показала отличную производительность в таких областях, как диалог и безопасность. Особенно при работе со сложными образцами только модель Skywork-Reward-Gemma-2-27B давала правильные прогнозы. Это достижение отмечает техническую мощь и инновационные возможности Kunlun Wanwei в глобальной области искусственного интеллекта, а также открывает новые возможности для разработки и применения технологий искусственного интеллекта.
Адрес модели 27Б:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
Адрес модели 8B:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
Превосходное выступление Kunlun Wanwei на RewardBench демонстрирует его передовые технологические и инновационные возможности в области искусственного интеллекта. Оно также открывает новые направления и возможности для будущей разработки больших языковых моделей. Мы надеемся, что в будущем он принесет новые прорывы.