Исследования команды Mamba совершили прорыв. Они успешно «превратили» большую модель Трансформера Llama в более эффективную модель Mamba. В этом исследовании умело сочетаются такие технологии, как прогрессивная дистилляция, контролируемая точная настройка и оптимизация предпочтений по направлению, а также разрабатывается новый алгоритм декодирования вывода, основанный на уникальной структуре модели Мамбы, который значительно повышает скорость вывода модели, не обеспечивая при этом существенного улучшения. КПД был достигнут без потерь. Это исследование не только снижает стоимость обучения крупномасштабных моделей, но и дает новые идеи для будущей оптимизации моделей, что имеет важное академическое значение и прикладную ценность.
В последнее время исследования команды Mamba привлекают внимание: исследователи из таких университетов, как Корнелл и Принстон, успешно «перегнали» Llama, большую модель Трансформера, в Mamba и разработали новый алгоритм декодирования вывода, который значительно улучшил скорость вывода модели.
Цель исследователей — превратить ламу в мамбу. Зачем это делать? Потому что обучение большой модели с нуля стоит дорого, и Mamba привлекла широкое внимание с момента ее создания, но лишь немногие команды на самом деле обучают крупномасштабные модели Mamba самостоятельно. Хотя на рынке есть несколько надежных вариантов, таких как Jamba от AI21 и Hybrid Mamba2 от NVIDIA, во многие успешные модели Transformer заложен богатый опыт. Если бы мы могли зафиксировать эти знания и точно настроить Трансформер на Мамбу, проблема была бы решена.
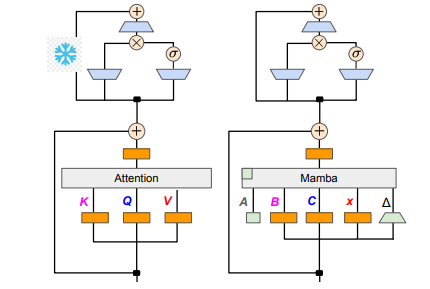
Исследовательская группа успешно достигла этой цели, объединив различные методы, такие как прогрессивная дистилляция, контролируемая точная настройка и оптимизация предпочтений по направлению. Стоит отметить, что скорость также имеет решающее значение без ущерба для производительности. Mamba имеет очевидные преимущества в рассуждениях с длинными последовательностями, а Transformer также предлагает решения для ускорения рассуждений, такие как спекулятивное декодирование. Поскольку уникальная структура Mamba не может напрямую применить эти решения, исследователи специально разработали новый алгоритм и объединили его с аппаратными функциями для реализации спекулятивного декодирования на основе Mamba.
Наконец, исследователи успешно преобразовали Zephyr-7B и Llama-38B в линейные модели RNN, и их производительность была сопоставима со стандартной моделью до дистилляции. Весь процесс обучения использует только 20 млрд токенов, а результаты сопоставимы с моделью Mamba7B, обученной с нуля с использованием токенов 1,2 тыс., и моделью NVIDIA Hybrid Mamba2, обученной с использованием токенов 3,5 тыс.
С точки зрения технических деталей линейная RNN и линейное внимание связаны, поэтому исследователи могут напрямую повторно использовать матрицу проекции в механизме внимания и завершить построение модели посредством инициализации параметров. Кроме того, исследовательская группа заморозила параметры слоя MLP в Transformer, постепенно заменила головку внимания линейным слоем RNN (т. е. Mamba) и обработала внимание групповых запросов для общих ключей и значений по головкам.
В процессе дистилляции принимается стратегия постепенной замены слоев внимания. Контролируемая точная настройка включает в себя два основных метода: один основан на расхождении KL на уровне слов, а другой — на дистилляции знаний на уровне последовательности. На этапе настройки пользовательских предпочтений команда использовала метод прямой оптимизации предпочтений (DPO), чтобы гарантировать, что модель может лучше соответствовать ожиданиям пользователей при создании контента путем сравнения его с результатами модели учителя.
Затем исследователи начали применять умозрительное декодирование Трансформера к модели Мамбы. Спекулятивное декодирование можно просто понимать как использование небольшой модели для генерации нескольких выходных данных, а затем использование большой модели для проверки этих выходных данных. Маленькие модели выполняются быстро и могут быстро генерировать несколько выходных векторов, тогда как большие модели отвечают за оценку точности этих выходных данных, тем самым увеличивая общую скорость вывода.
Чтобы реализовать этот процесс, исследователи разработали набор алгоритмов, которые используют небольшую модель для генерации K черновых выходных данных каждый раз, а затем большая модель возвращает окончательный результат и кэширует промежуточные состояния посредством проверки. Этот метод показал хорошие результаты на графическом процессоре Mamba2.8B, добившись ускорения вывода в 1,5 раза, а уровень принятия достиг 60%. Хотя эффекты различаются на графических процессорах разных архитектур, исследовательская группа дополнительно оптимизировала их за счет интеграции ядер и корректировки методов реализации и, наконец, добилась идеального эффекта ускорения.
На экспериментальном этапе исследователи использовали Zephyr-7B и Llama-3Instruct8B для проведения трехэтапного обучения дистилляции. В конечном итоге для успешного воспроизведения результатов исследования на 8-карточном 80G A100 потребовалось всего 3–4 дня. Это исследование не только показывает трансформацию между Мамбой и Ламой, но и предлагает новые идеи для улучшения скорости вывода и производительности будущих моделей.
Адрес статьи: https://arxiv.org/pdf/2408.15237.
Это исследование предоставляет ценный опыт и технические решения для повышения эффективности крупномасштабных языковых моделей. Ожидается, что результаты будут применяться в большем количестве областей и будут способствовать дальнейшему развитию технологий искусственного интеллекта. Указание адреса статьи помогает читателям глубже понять детали исследования.