В академическом мире поток ложных работ стал серьезной проблемой, которая серьезно препятствовала прогрессу научных исследований и распространение знаний. Чтобы справиться с этой проблемой, Ахмад Абута Хард, исследователь из Университета Бинхамтона, штат Нью -Йорк, разработал алгоритм машинного обучения под названием Xfakesci. В этой статье будут изучены принципы, приложения и будущие направления развития алгоритма Xfakesci и демонстрируют его огромный потенциал в расстройстве академического мошенничества.
В эту эпоху информационного взрыва, особенно в области научных исследований, появление поддельных документов является непобедимым.
Недавно Ахмед Абдин Хамед, исследователь Университета Бинхамона, Нью -Йорк, разработал алгоритм машинного обучения под названием Xfakesci, который может достичь 94% идентификации точности.
Хард сказал, что его основное направление исследования - биомедицинская информатика, а во время эпидемии фальшивые научные исследования бесконечны.
Он провел большое количество экспериментов с командой, выпустил 50 поддельных статей по трем популярным медицинским темам: болезнь, рак и депрессию Альцгеймера, а также сравнил и проанализировал с реальными статьями с той же темой. Он надеется найти различия и модели с помощью этого метода.
В ходе исследовательского процесса Hardeid извлекла соответствующие документы, используя базу данных PubMed Национального института здравоохранения, и использовал те же ключевые слова для запроса CHATGPT для создания статей. Его интуиция говорит ему, что между ложными документами и реальными документами должна быть определенная модель.
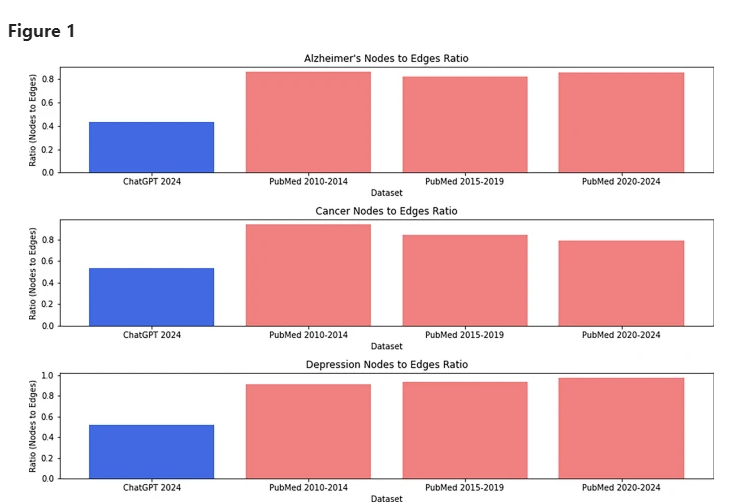
Узлы к краю соотношения различных наборов данных и научных статей.
После анализа в ходе, алгоритм Xfakesci фокусируется на двух основных характеристиках: одним из них является двойная комбинация (биграм) в статье, таких как «изменение климата», «клиническое испытание» и т. Д. Другая -это связь между этими Двойные комбинации с другим словарным запасом и понятиями.
Он обнаружил, что количество комбинаций с двойным характером, появляющиеся в поддельных документах, значительно меньше, чем реальные статьи, хотя эти комбинации тесно связаны с другим контентом в поддельных документах.
Он отметил, что статьи, создаваемые ИИ, часто убедительно убедить читателей, и цель человеческих исследователей состоит в том, чтобы честно сообщать о результатах и методах экспериментальной экспериментальности.
В будущем жесткие планы по расширению алгоритма Xfakesci до большего количества областей, включая инженерию, науку и гуманитарные науки и т. Д., Чтобы проверить, являются ли характеристики поддельных работ. Он подчеркнул, что с постоянным улучшением технологии ИИ сложность идентификации подлинных документов будет продолжать расти. Поэтому особенно важно разработать комплексное решение.
Хотя текущий алгоритм может обнаружить 94% ложных документов, 6% поддельных документов могут упустить сеть. Он скромно сказал, что, хотя был достигнут важный прогресс, ему все еще нужно усердно работать, чтобы повысить уровень признания и повысить бдительность общественности.
Вход в диссертацию: https://www.nature.com/articles/s41598-024-66784-6
Очки:
** Новый инструмент Xfakesci может идентифицировать фальшивые научные исследования до 94% точности и эскортных научных исследований. **
? **
** В будущем масштаб алгоритма расширения будет использоваться для решения все более сложных задач, генерирующих AI. **
Появление алгоритма Xfakesci обеспечивает сильное оружие для устранения академического мошенничества, но его все равно необходимо постоянно улучшать и улучшать. Содействие технологии и поддержание академической целостности должны работать вместе для создания более здоровой академической экологии.