Google DeepMind объединилась с рядом университетов для разработки нового метода под названием Generative Reward Model (GenRM), целью которого является решение проблемы недостаточной точности и надежности генеративного ИИ в задачах рассуждения. Хотя существующие генеративные модели ИИ широко используются в таких областях, как обработка естественного языка, они часто уверенно выдают ошибочную информацию, особенно в областях, требующих чрезвычайно высокой точности, что ограничивает область их применения. Инновация GenRM заключается в том, чтобы переопределить процесс проверки как задачу предсказания следующего слова, интегрировать возможности генерации текста больших языковых моделей (LLM) в процесс проверки и поддержать цепное рассуждение, тем самым обеспечивая более полную и систематическую проверку.
Недавно исследовательская группа Google DeepMind объединилась с рядом университетов, чтобы предложить новый метод под названием «Генеративная модель вознаграждения» (GenRM), целью которого является повышение точности и надежности генеративного ИИ в задачах рассуждения.
Генеративный ИИ широко используется во многих областях, таких как обработка естественного языка. Он в основном генерирует связный текст, предсказывая следующее слово из серии слов. Однако эти модели иногда уверенно выдают неверную информацию, что является большой проблемой, особенно в областях, где точность имеет решающее значение, таких как образование, финансы и здравоохранение.
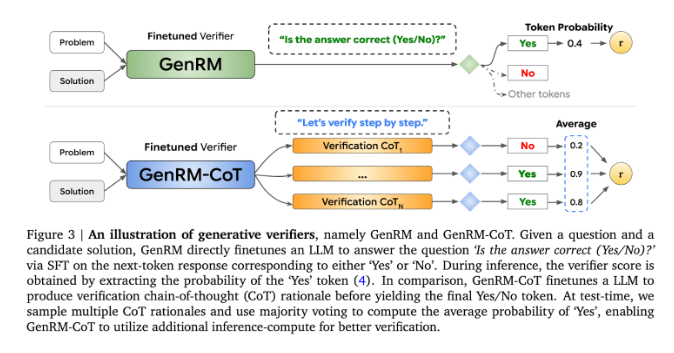
В настоящее время исследователи пробовали различные решения проблем, с которыми сталкиваются генеративные модели ИИ в отношении точности вывода. Среди них дискриминационные модели вознаграждения (RM) используются для определения правильности потенциальных ответов на основе оценок, но этот метод не может полностью использовать генеративные возможности больших языковых моделей (LLM). Другой часто используемый метод — «LLM как судья», но этот метод часто не так эффективен, как профессиональный проверяющий, при решении сложных рассуждений.
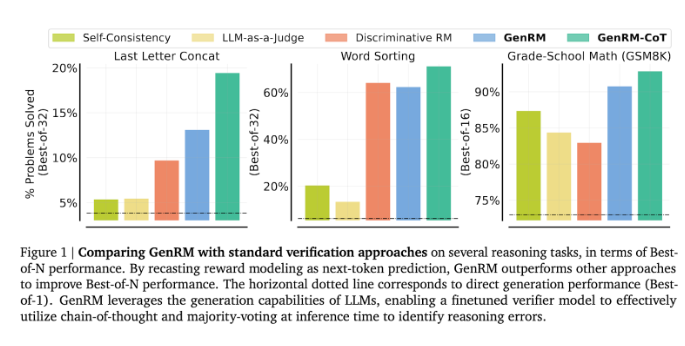
Инновация GenRM заключается в том, чтобы переопределить процесс проверки как задачу предсказания следующего слова. Это означает, что, в отличие от традиционных моделей дискриминационного вознаграждения, GenRM включает возможности LLM по генерации текста в процесс проверки, позволяя модели одновременно генерировать и оценивать потенциальные решения. Кроме того, GenRM также поддерживает цепное рассуждение (CoT), то есть модель может генерировать промежуточные этапы рассуждения, прежде чем прийти к окончательному выводу, что делает процесс проверки более комплексным и систематическим.
Объединив генерацию и проверку, подход GenRM использует унифицированную стратегию обучения, которая позволяет модели одновременно улучшать возможности генерации и проверки во время обучения. В реальных приложениях модель генерирует промежуточные шаги вывода, которые используются для проверки окончательного ответа.
Исследователи обнаружили, что модель GenRM хорошо показала себя в нескольких строгих тестах, например, значительно повысила точность выполнения математических задач для дошкольников и алгоритмических задач по решению задач. По сравнению с моделью дискриминационного вознаграждения и методом LLM в качестве судьи уровень успеха решения проблем GenRM увеличился на 16–64%.
Например, при проверке результатов модели Gemini1.0Pro GenRM увеличила вероятность успешного решения проблем с 73% до 92,8%.
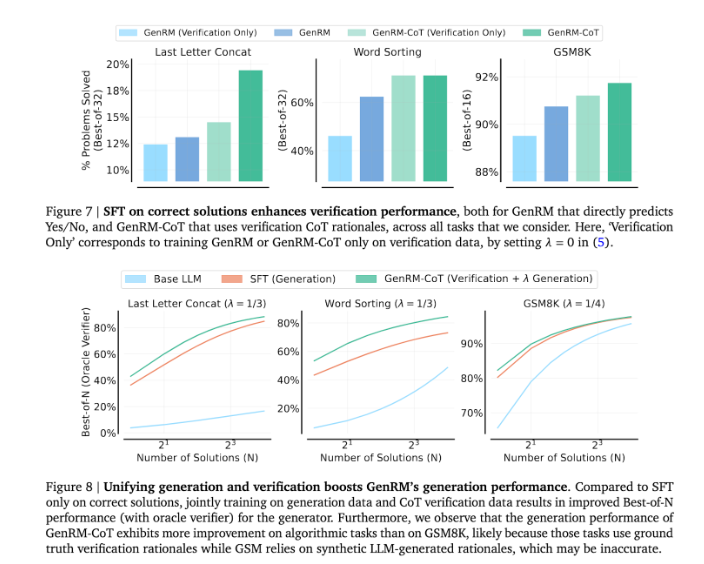
Внедрение метода GenRM знаменует собой крупный прогресс в области генеративного ИИ, значительно повышая точность и надежность решений, генерируемых ИИ, за счет объединения генерации и проверки решений в один процесс.
В целом, появление GenRM дает новые идеи для повышения надежности генеративного ИИ. Его значительное улучшение в решении сложных задач рассуждения указывает на возможность применения генеративного ИИ в большем количестве областей, что заслуживает дальнейших исследований и исследований.