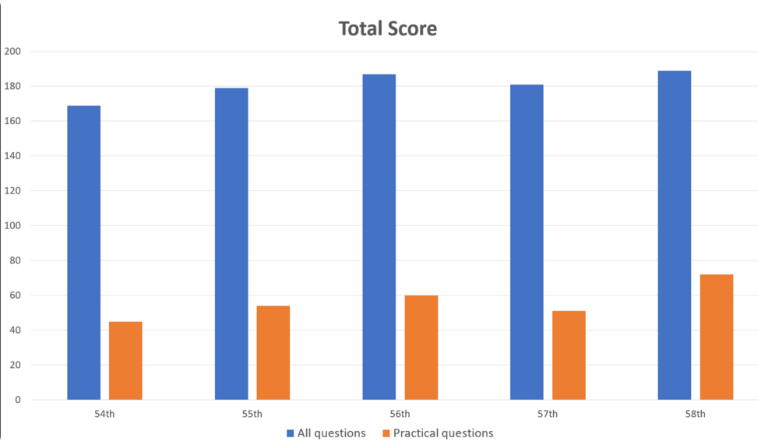
Недавно исследование, опубликованное в журнале Cureus, показало, что модель GPT-4 от OpenAI успешно сдала японский национальный экзамен по физиотерапии без дополнительного обучения. Исследователи протестировали GPT-4, используя 1000 вопросов, охватывающих память, понимание, применение, анализ и оценку. Результаты показали, что он имел точность 73,4% и прошел все пять частей теста. Это исследование вызывает обеспокоенность по поводу потенциала GPT-4 для медицинского применения, а также выявляет его ограничения при решении конкретных типов задач, таких как практические задачи и задачи, содержащие таблицы с картинками.
Недавнее рецензируемое исследование, опубликованное в журнале Cureus, показывает, что языковая модель OpenAI GPT-4 успешно прошла японский национальный экзамен по физиотерапии без какого-либо дополнительного обучения.
Исследователи задали 1000 вопросов в GPT-4, охватывающих такие области, как память, понимание, применение, анализ и оценка. Результаты показали, что GPT-4 в целом правильно ответил на 73,4% вопросов, пройдя все пять частей теста. Однако исследования также выявили ограничения ИИ в некоторых областях.

GPT-4 хорошо показал себя при решении общих задач с точностью 80,1%, но только 46,6% при решении практических задач. Аналогично, он гораздо лучше справляется с текстовыми вопросами (правильно 80,5%), чем с вопросами с картинками и таблицами (правильно 35,4%). Этот вывод согласуется с предыдущими исследованиями ограничений зрительного понимания GPT-4.
Стоит отметить, что сложность вопроса и длина текста мало влияют на производительность GPT-4. Хотя модель в основном обучалась с использованием данных на английском языке, она также хорошо работала при обработке данных на японском языке.
Исследователи отметили, что, хотя это исследование демонстрирует потенциал GPT-4 в клинической реабилитации и медицинском образовании, к нему следует относиться с осторожностью. Они подчеркнули, что GPT-4 не отвечает правильно на все вопросы и что в будущем потребуются оценки новых версий и возможностей модели в письменных и логических тестах.
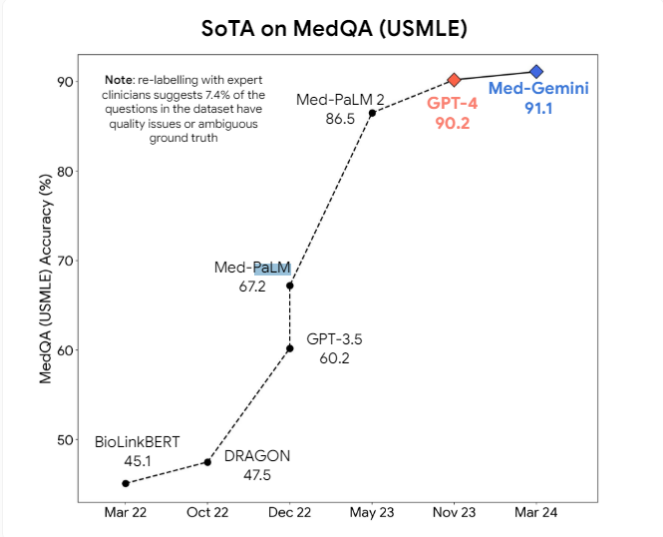
Кроме того, исследователи предположили, что мультимодальные модели, такие как GPT-4v, могут способствовать дальнейшему улучшению визуального понимания. В настоящее время активно разрабатываются профессиональные медицинские модели искусственного интеллекта, такие как Med-PaLM2 и Med-Gemini от Google, а также медицинская модель Meta на основе Llama3 с целью превзойти модели общего назначения в медицинских задачах.
Однако эксперты полагают, что может пройти много времени, прежде чем медицинские модели искусственного интеллекта начнут широко использоваться на практике. Пространство ошибок текущих моделей остается слишком большим в медицинских учреждениях, и необходимы значительные достижения в возможностях вывода для безопасной интеграции этих моделей в повседневную медицинскую практику.
Хотя это исследование демонстрирует потенциал GPT-4 в медицинской сфере, оно также напоминает нам, что технология искусственного интеллекта все еще нуждается в постоянном совершенствовании, прежде чем ее можно будет действительно применять в сложных медицинских сценариях. В будущем мультимодальные модели и более мощные возможности рассуждения станут ключевыми улучшениями для обеспечения безопасности и надежности ИИ в медицинской помощи.