Недавно компания MLCommons опубликовала результаты теста MLPerf v4.1, в котором приняли участие несколько производителей микросхем искусственного интеллекта, и конкуренция была жесткой. Впервые в этом соревновании участвуют чипы AMD, Google, UntetherAI и других производителей, а также новейшие чипы Blackwell от Nvidia. Помимо сравнения производительности, важным конкурентным аспектом стала также энергоэффективность. Различные производители продемонстрировали свои особые навыки и продемонстрировали свои преимущества в различных тестах производительности, привнося новую жизнь на рынок чипов вывода ИИ.
В области обучения искусственному интеллекту видеокарты Nvidia практически не имеют себе равных, но когда дело доходит до вывода ИИ, конкуренты, похоже, начинают догонять их, особенно с точки зрения энергоэффективности. Несмотря на высокую производительность новейших чипов Blackwell от Nvidia, неясно, сможет ли он сохранить свое лидерство. Сегодня ML Commons объявила результаты последнего конкурса AI-выводов — MLPerf Inference v4.1. Впервые в конкурсе участвуют ускоритель Instinct от AMD, ускоритель Trillium от Google, чипы канадского стартапа UntetherAI и чипы Blackwell от Nvidia. Две другие компании, Cerebras и FuriosaAI, выпустили новые чипы вывода, но не представили MLPerf на тестирование.
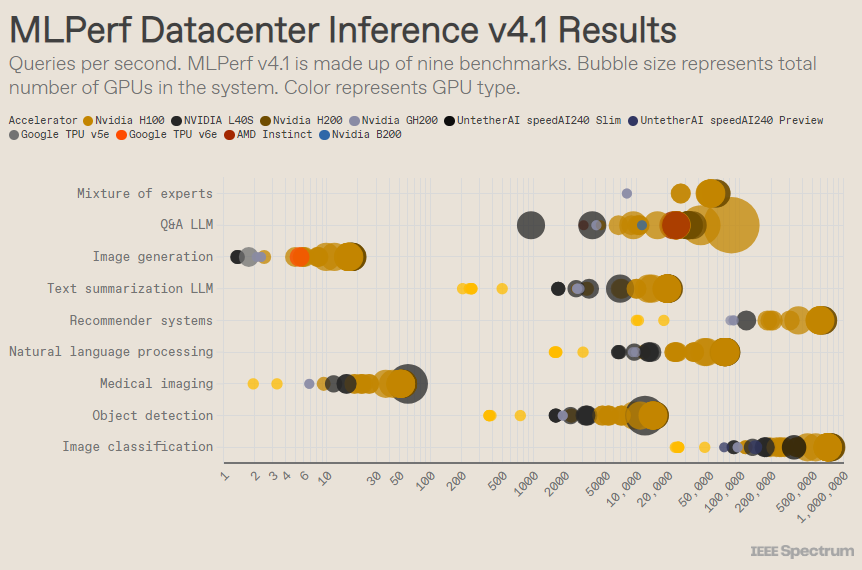
MLPerf структурирован как олимпийское соревнование с множеством соревнований и подсобытий. Больше всего записей было в категории «Корпус дата-центра». В отличие от открытой категории, закрытая категория требует от участников выполнения логических выводов непосредственно на данной модели без существенной модификации программного обеспечения. Категория центров обработки данных в первую очередь проверяет возможность пакетной обработки запросов, а категория периферийных устройств фокусируется на уменьшении задержки.
В каждой категории есть 9 различных тестов, охватывающих различные задачи ИИ, включая генерацию популярных изображений (например, Midjourney) и ответы на вопросы с помощью больших языковых моделей (таких как ChatGPT), а также некоторые важные, но менее известные задачи, такие как классификация изображений, обнаружение объектов и механизмы рекомендаций.
В этом раунде добавляется новый ориентир – «экспертная гибридная модель». Это становится все более популярным методом развертывания языковой модели, при котором языковая модель разбивается на несколько независимых небольших моделей, каждая из которых настроена для конкретной задачи, например ежедневного общения, решения математических задач или помощи в программировании. По словам Мирослава Ходака, старшего технического сотрудника AMD, за счет присвоения каждому запросу соответствующей небольшой модели снижается использование ресурсов, снижаются затраты и увеличивается пропускная способность.

В популярном тесте «закрытый центр обработки данных» по-прежнему побеждают работы на базе графического процессора Nvidia H200 и суперчипа GH200, которые объединяют графический процессор и центральный процессор в одном корпусе. Однако более пристальный взгляд на результаты открывает некоторые интересные детали. Некоторые конкуренты использовали несколько ускорителей, а другие — только один. Результаты станут еще более запутанными, если мы нормализуем количество запросов в секунду по количеству ускорителей и сохраним наиболее эффективные отправки для каждого типа ускорителей. Следует отметить, что этот подход игнорирует роль ЦП и межсоединения.
В расчете на каждый ускоритель процессор Nvidia Blackwell преуспел в выполнении задач вопросов и ответов на большой языковой модели, обеспечив ускорение в 2,5 раза по сравнению с предыдущими итерациями чипа, единственным тестом, которому он подвергался. Чип предварительного просмотра SpeedAI240 от Untether AI справился почти так же хорошо, как H200, с единственной задачей распознавания изображений, которую ему пришлось выполнить. Google Trillium работает немного ниже, чем H100 и H200, в задачах создания изображений, тогда как AMD Instinct работает эквивалентно H100 в задачах с вопросами и ответами на большую языковую модель.
Частично успех Blackwell обусловлен его способностью запускать большие языковые модели с использованием 4-битной точности с плавающей запятой. Nvidia и ее конкуренты работают над уменьшением количества битов, представленных в моделях преобразования, таких как ChatGPT, для ускорения вычислений. Nvidia представила 8-битные математические вычисления в H100, и это представление является первой демонстрацией 4-битных математических вычислений в тесте MLPerf.
По словам Дэйва Сальватора, директора по маркетингу продукции Nvidia, самой большой проблемой при работе с такими числами низкой точности является поддержание точности. Чтобы обеспечить высокую точность отправки данных MLPerf, команда Nvidia внесла в программное обеспечение множество нововведений.
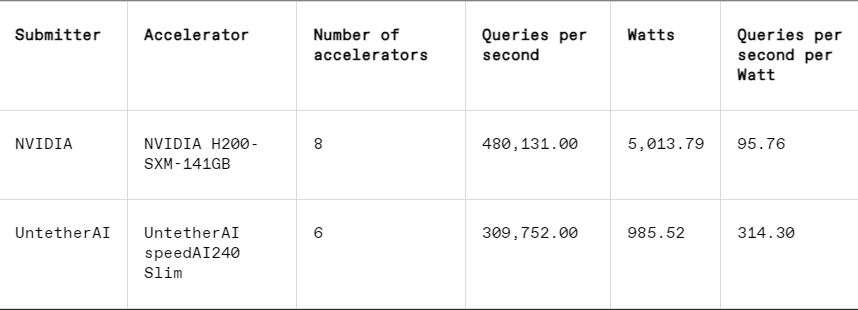
Кроме того, пропускная способность памяти Blackwell почти удваивается до 8 терабайт в секунду по сравнению с 4,8 терабайта у H200.
В предложении Nvidia Blackwell используется один чип, но Сальватор утверждает, что он предназначен для работы в сети и масштабирования и будет работать лучше всего в сочетании с межсетевым соединением NVLink от Nvidia. Графические процессоры Blackwell поддерживают до 18 соединений NVLink со скоростью 100 ГБ в секунду с общей пропускной способностью 1,8 терабайт в секунду, что почти вдвое превышает пропускную способность межсоединений H100.
Сальватор считает, что по мере того, как большие языковые модели продолжают масштабироваться, даже для вывода потребуются платформы с несколькими графическими процессорами, чтобы удовлетворить спрос, и Blackwell создан для этой ситуации. «Хавел — это платформа», — сказал Сальватор.
Nvidia отправила свою систему чипов Blackwell в подкатегорию «Предварительный просмотр», что означает, что она еще не доступна, но ожидается, что она будет доступна до следующего выпуска MLPerf, который состоится примерно через шесть месяцев.
В каждом тесте MLPerf также есть раздел измерения энергии, который систематически проверяет фактическое энергопотребление каждой системы во время выполнения задач. В основном соревновании этого раунда (категория «Закрытая энергетика центров обработки данных») приняли участие только два претендента: Nvidia и Untether AI. Хотя Nvidia участвовала во всех тестах, Untether представила результаты только по задаче распознавания изображений.
Untether AI преуспевает в этом отношении, успешно достигая превосходной энергоэффективности. Их чип использует подход, называемый «вычисления в памяти». Чип Untether AI состоит из банка ячеек памяти и небольшого процессора, расположенного рядом. Каждый процессор работает параллельно, обрабатывая данные одновременно с соседними блоками памяти, что значительно сокращает время и энергию, затрачиваемую на передачу данных модели между памятью и вычислительными ядрами.
«Мы обнаружили, что при выполнении рабочих нагрузок ИИ 90% энергопотребления приходится на перемещение данных из DRAM в блоки кэш-обработки», — сказал Роберт Бичлер, вице-президент по продуктам Untether AI. «Поэтому Untether перемещает вычисления ближе к данным, а не перемещает данные в вычислительный блок».
Этот подход особенно хорошо работает в другой подкатегории MLPerf: закрытии ребер. Эта категория фокусируется на более практических вариантах использования, таких как проверка машин на заводах, роботы с управляемым зрением и автономные транспортные средства — приложения, которые предъявляют строгие требования к энергоэффективности и быстрой обработке, объяснил Бичлер.
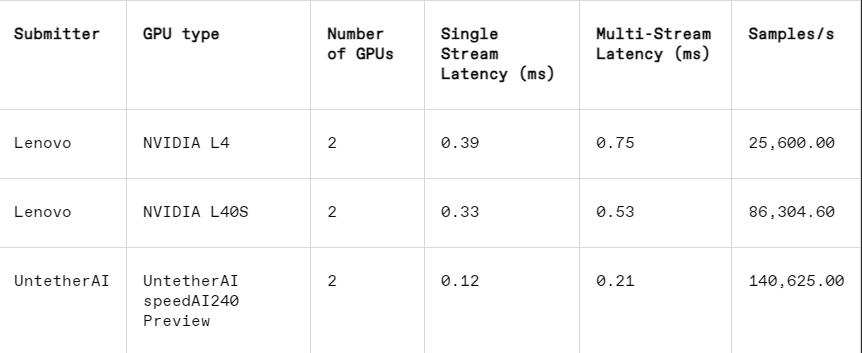
В задаче распознавания изображений задержка чипа предварительного просмотра SpeedAI240 от Untether AI в 2,8 раза выше, чем у Nvidia L40S, а пропускная способность (количество выборок в секунду) также увеличена в 1,6 раза. Стартап также представил результаты энергопотребления в этой категории, но конкуренты Nvidia этого не сделали, что затрудняет прямое сравнение. Однако чип предварительного просмотра SpeedAI240 от Untether AI имеет номинальное энергопотребление 150 Вт, а L40S от Nvidia — 350 Вт, что демонстрирует 2,3-кратное преимущество в энергопотреблении и лучшую задержку.
Хотя Cerebras и Furiosa не участвовали в MLPerf, они также выпустили новые чипы соответственно. Cerebras представила свой сервис вывода на конференции IEEE Hot Chips в Стэнфордском университете. Компания Cerebras, расположенная в Санни-Вэлли, штат Калифорния, производит гигантские чипы, размер которых настолько велик, насколько позволяют кремниевые пластины, что позволяет избежать взаимосвязей между чипами и значительно увеличить пропускную способность памяти устройства. Они в основном используются для обучения гигантских нейронных сетей. Теперь они обновили свой последний компьютер CS3, чтобы он поддерживал логический вывод.
Хотя Cerebras не представила MLPerf, компания утверждает, что ее платформа превосходит H100 в 7 раз, а конкурирующий чип Groq — в 2 раза по количеству токенов LLM, генерируемых в секунду. «Сегодня мы живем в эпоху коммутируемого доступа к генеративному искусственному интеллекту», — сказал Эндрю Фельдман, генеральный директор и соучредитель Cerebras. «Это все потому, что существует узкое место в пропускной способности памяти. Будь то Nvidia H100, AMD MI300 или TPU, все они используют одну и ту же внешнюю память, что приводит к одним и тем же ограничениям. Мы преодолеваем этот барьер, потому что делаем это на уровне платы». "
На конференции Hot Chips компания Furiosa из Сеула также продемонстрировала свой чип второго поколения RNGD (произносится как «бунтарь»). Новый чип Furiosa имеет архитектуру тензорного процессора сжатия (TCP). В рабочих нагрузках ИИ основной математической функцией является умножение матриц, часто реализуемое аппаратно в виде примитива. Однако размер и форма матрицы, то есть более широкого тензора, могут существенно различаться. RNGD реализует это более общее тензорное умножение как примитив. «Во время вывода размеры пакетов сильно различаются, поэтому крайне важно в полной мере воспользоваться преимуществами параллелизма и повторного использования данных заданной формы тензора», — сказала Джун Пайк, основатель и генеральный директор Furiosa, в Hot Chips.
Хотя у Furiosa нет MLPerf, они сравнили чип RNGD с итоговым тестом LLM MLPerf во время внутреннего тестирования, и результаты были сопоставимы с чипом Nvidia L40S, но потребляли всего 185 Вт по сравнению с 320 Вт у L40S. Пайк сказал, что производительность улучшится при дальнейшей оптимизации программного обеспечения.
IBM также объявила о выпуске своего нового чипа Spyre, который предназначен для предприятий для создания рабочих нагрузок искусственного интеллекта и, как ожидается, будет доступен в первом квартале 2025 года.
Очевидно, что в обозримом будущем рынок чипов вывода ИИ будет оживленным.
Ссылка: https://spectrum.ieee.org/new-inference-chips.
В целом, результаты MLPerf v4.1 показывают, что конкуренция на рынке чипов вывода AI становится все более жесткой. Хотя Nvidia по-прежнему удерживает лидерство, нельзя игнорировать рост таких производителей, как AMD, Google и Untether AI. В будущем энергоэффективность станет ключевым фактором конкуренции, и новые технологии, такие как вычисления в памяти, также будут играть важную роль. Технологические инновации различных производителей будут и дальше способствовать совершенствованию способностей ИИ-рассуждения и давать мощный стимул для популяризации и развития приложений ИИ.