Появление архитектуры Transformer произвело революцию в области обработки естественного языка, но ее высокая вычислительная стоимость стала узким местом при обработке длинных текстов. В ответ на эту проблему в этой статье представлен новый метод под названием Tree Attention, который эффективно снижает вычислительную сложность модели Transformer с длинным контекстом за счет сокращения дерева и в полной мере использует возможности современных кластеров графических процессоров. Топология сети. значительно повышает эффективность вычислений.
В эпоху информационного взрыва искусственный интеллект подобен ярким звездам, освещающим ночное небо человеческой мудрости. Среди этих звезд архитектура Transformer, несомненно, является самой выдающейся. Ее ядром является механизм самообслуживания, и она открывает новую эру обработки естественного языка. Однако даже у самых ярких звезд есть труднодоступные уголки. Для моделей Трансформера с длинным контекстом высокое потребление ресурсов при расчете самообслуживания становится проблемой. Представьте, что вы пытаетесь заставить ИИ понять статью длиной в десятки тысяч слов. Каждое слово нужно сравнить с каждым другим словом в статье. Объем вычислений, несомненно, огромен.
Чтобы решить эту проблему, группа ученых из Zyphra и EleutherAI предложила новый метод под названием Tree Attention.
Самовнимание, являющееся ядром модели Трансформера, его вычислительная сложность увеличивается квадратично по мере увеличения длины последовательности. Это становится непреодолимым препятствием при работе с длинными текстами, особенно для больших языковых моделей (LLM).
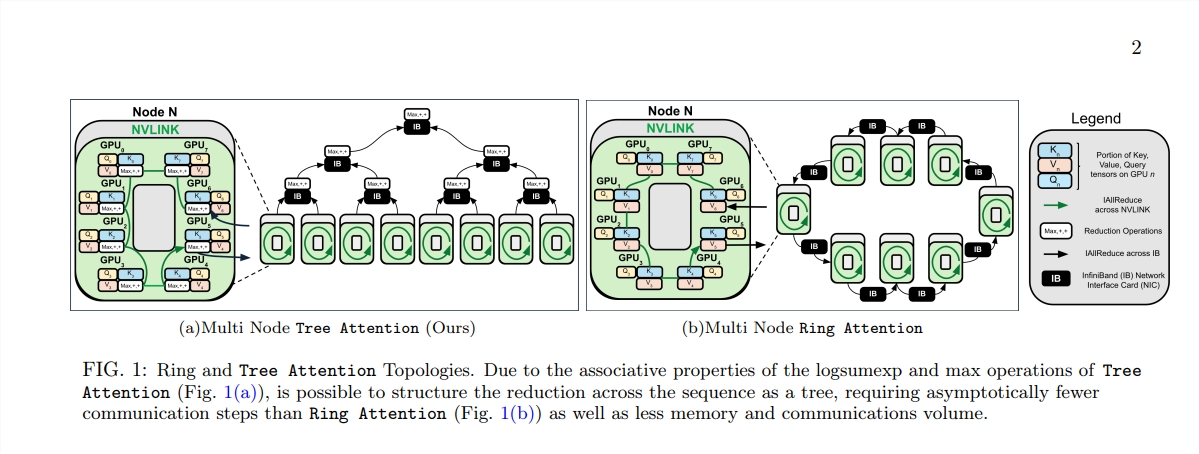
Рождение Tree Attention похоже на посадку деревьев, способных выполнять эффективные вычисления в этом вычислительном лесу. Он разбивает расчет самообслуживания на несколько параллельных задач посредством сокращения дерева. Каждая задача подобна листу на дереве, которые вместе образуют полное дерево.
Еще более удивительно то, что авторы «Дерева внимания» также вывели энергетическую функцию самовнимания, которая не только дает байесовское объяснение самовнимания, но и тесно связывает ее с такими энергетическими моделями, как сеть Хопфилда.
Tree Attention также уделяет особое внимание сетевой топологии современных кластеров графических процессоров и снижает требования к межузловой связи за счет разумного использования соединений с высокой пропускной способностью внутри кластера, тем самым повышая эффективность вычислений.
С помощью серии экспериментов ученые проверили производительность Tree Attention при различной длине последовательности и количестве графических процессоров. Результаты показывают, что Tree Attention работает до 8 раз быстрее, чем существующие методы Ring Attention при декодировании на нескольких графических процессорах, при этом значительно сокращая объем связи и пиковое использование памяти.
Предложение Tree Attention не только обеспечивает эффективное решение для расчета моделей внимания с длинным контекстом, но также открывает нам новую перспективу для понимания внутреннего механизма модели Transformer. Поскольку технология искусственного интеллекта продолжает развиваться, у нас есть основания полагать, что Tree Attention будет играть важную роль в будущих исследованиях и приложениях искусственного интеллекта.
Адрес бумаги: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ.
Появление Tree Attention обеспечивает эффективное и инновационное решение для устранения вычислительных проблем при обработке длинного текста. Оно имеет далеко идущее значение для понимания и будущего развития модели Transformer. Этот метод не только позволяет добиться значительного улучшения производительности, но, что более важно, дает новые идеи и направления для последующих исследований, которые достойны углубленного изучения и обсуждения.