Команда UCSC-VLAA выпустила огромный мультимодальный набор медицинских данных MedTrinity-25M, который содержит 25 миллионов медицинских изображений и подробных аннотаций, что знаменует собой большой скачок в ресурсах данных в области медицины. Многогранная аннотация этого набора данных позволяет исследователям более глубоко понимать и применять медицинские данные и обеспечивает прочную основу для обучения передовых медицинских мультимодальных больших моделей. Процесс создания MedTrinity-25M включает в себя множество технологий, включая сложную обработку данных, интеграцию метаданных, генерацию описаний с помощью крупномасштабной языковой модели (MLLM) и т. д., что значительно повышает удобство использования и исследовательскую ценность данных.
Официально выпущен крупномасштабный мультимодальный набор данных «MedTrinity-25M» от команды UCSC-VLAA. Этот набор данных содержит 25 миллионов медицинских изображений и подробных аннотаций. Его можно охарактеризовать как важное нововведение в области медицины. Он содержит многограничные аннотации, которые могут помочь исследователям лучше понимать и применять медицинские данные, а также использоваться для обучения медицинских мультимодальных больших моделей.
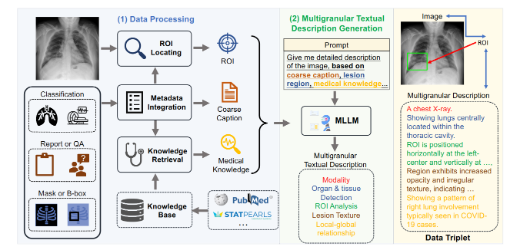
Процесс создания MedTrinity-25M довольно сложен. После тщательной обработки данных команда извлекла ключевую информацию, полученную из различных типов данных, объединила метаданные, сгенерировала приблизительные названия, определила области интереса и собрала соответствующую медицинскую информацию. Что еще интереснее, они использовали эту информацию для создания подробных описаний с использованием крупномасштабных языковых моделей (MLLM). Такой подход не только повышает доступность данных, но и открывает новые направления для медицинских исследований.
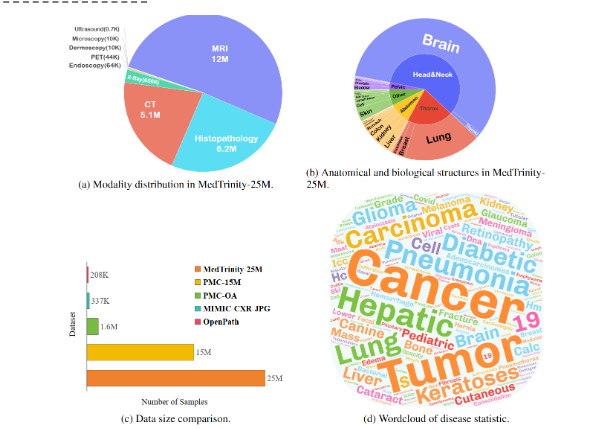
Говоря о процессе выпуска, стоит отметить, что демонстрационный набор данных MedTrinity-25M был доступен онлайн еще в июне 2024 года, тогда как полный набор данных был официально опубликован 21 июля, а совсем недавно, 7 августа, они также опубликовали сопутствующие бумаги.
В дополнение к самому набору данных команда также предоставляет ряд предварительно обученных моделей, таких как LLaVA-Med++, которые хорошо справляются с множеством медицинских задач. Исследователи могут использовать эти инструменты для более эффективного выполнения своих проектов, что значительно повышает эффективность медицинских исследований.
MedTrinity-25M представляет собой ценный ресурс для медицинского сообщества. Я надеюсь, что каждый сможет в полной мере использовать этот набор данных для содействия развитию медицинских исследований.
Вход в проект: https://top.aibase.com/tool/medtrinity-25m
Выпуск набора данных MedTrinity-25M и поддерживающих его моделей обеспечивает мощный импульс исследованиям в области медицинского искусственного интеллекта. Мы ожидаем, что этот набор данных будет способствовать прорывам в анализе медицинских изображений, диагностике заболеваний и других областях и в конечном итоге принесет пользу большему количеству пациентов. Исследователи могут посетить портал проекта, чтобы узнать больше об этом ценном ресурсе и использовать его.