Андрей Карпати, авторитет в области искусственного интеллекта, недавно поставил под сомнение обучение с подкреплением, основанное на обратной связи с человеком (RLHF), полагая, что это не единственный способ достичь истинного искусственного интеллекта человеческого уровня, что вызвало широкое беспокойство и горячие дискуссии в отрасли. . Он считает, что RLHF — это скорее временная мера, чем окончательное решение, и взял AlphaGo в качестве примера, чтобы сравнить различия в решении задач между реальным обучением с подкреплением и RLHF. Взгляды Карпати, несомненно, открывают новый взгляд на текущие направления исследований в области ИИ, а также ставят новые задачи перед будущим развитием ИИ.
Недавно Андрей Карпати, известный исследователь в области искусственного интеллекта, выдвинул противоречивую точку зрения. Он считает, что широко хвалимая в настоящее время технология обучения с подкреплением на основе обратной связи с человеком (RLHF) может быть не единственным способом достижения этой цели. истинные возможности решения проблем на человеческом уровне. Это заявление, несомненно, сбросило тяжелую бомбу на нынешнюю область исследований ИИ.
RLHF когда-то считался ключевым фактором успеха крупномасштабных языковых моделей (LLM), таких как ChatGPT, и провозглашался секретным оружием, которое дает ИИ понимание, послушание и естественные возможности взаимодействия. В традиционном процессе обучения ИИ RLHF обычно используется в качестве последнего звена после предварительного обучения и контролируемой тонкой настройки (SFT). Однако Карпати сравнил RLHF с узким местом и временной мерой, полагая, что это далеко не окончательное решение для эволюции ИИ.
Карпати умело сравнил RLHF с AlphaGo от DeepMind. AlphaGo использовала то, что он называет настоящей технологией RL (обучение с подкреплением), и, постоянно играя против себя и максимизируя свой процент выигрышей, в конечном итоге без вмешательства человека превзошла лучших шахматистов среди людей. Этот подход достигает сверхчеловеческого уровня производительности за счет оптимизации нейронных сетей для обучения непосредственно на результатах игр.
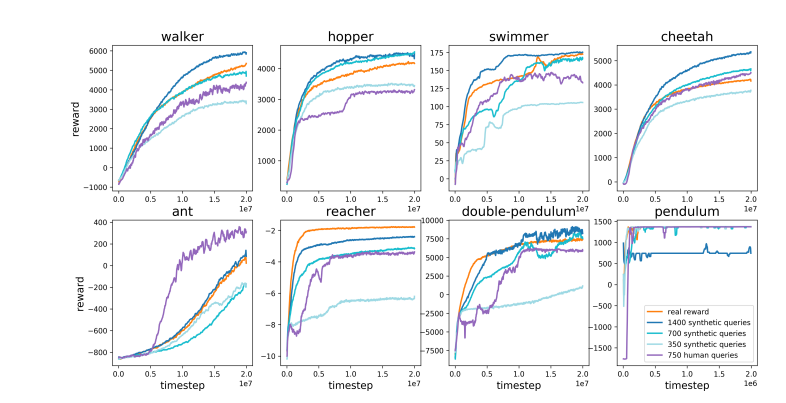
Напротив, Карпати считает, что RLHF больше занимается имитацией человеческих предпочтений, чем реальным решением проблем. Он предположил, что если AlphaGo примет метод RLHF, людям-оценщикам придется сравнивать большое количество состояний игры и выбирать предпочтения. Этот процесс может потребовать до 100 000 сравнений для обучения модели вознаграждения, имитирующей проверку человеческой атмосферы. Однако такие суждения, основанные на атмосфере, могут привести к ошибочным результатам в такой строгой игре, как го.
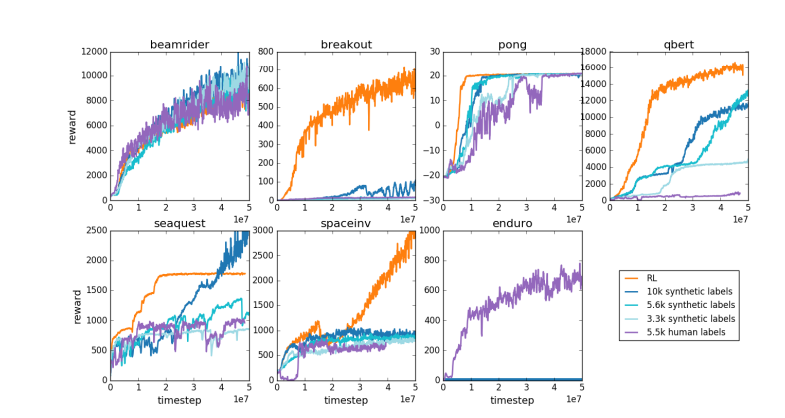
По той же причине текущая модель вознаграждения LLM работает аналогичным образом — она имеет тенденцию давать высокие ответы, которые, по статистике, предпочитают люди-оценщики. Это скорее агент, обслуживающий поверхностные человеческие предпочтения, чем отражение истинной способности решать проблемы. Еще более тревожно то, что модели могут быстро научиться использовать эту функцию вознаграждения, вместо того чтобы реально улучшить свои возможности.
Карпати отмечает, что, хотя обучение с подкреплением хорошо работает в закрытых средах, таких как Go, настоящее обучение с подкреплением остается невозможным для задач открытого языка. Это происходит главным образом потому, что в открытых задачах сложно определить четкие цели и механизмы вознаграждения. Как дать объективное вознаграждение за такие задачи, как резюмирование статьи, ответ на расплывчатый вопрос об установке пипа, рассказ анекдота или переписывание Java-кода на Python, задает этот проницательный вопрос, и идти в этом направлении не принципиально. Это невозможно, но это тоже непросто и требует творческого мышления.

Тем не менее, Карпати считает, что если эту сложную проблему удастся решить, языковые модели смогут действительно соответствовать человеческим способностям решения проблем или даже превосходить их. Эта точка зрения совпадает с недавней статьей, опубликованной Google DeepMind, в которой указывается, что открытость является основой общего искусственного интеллекта (AGI).
Будучи одним из нескольких старших экспертов в области искусственного интеллекта, покинувших OpenAI в этом году, Карпати в настоящее время работает над собственным образовательным стартапом в области искусственного интеллекта. Его замечания, несомненно, открыли новое измерение мышления в области исследований ИИ и предоставили ценную информацию о будущем направлении развития ИИ.
Взгляды Карпати вызвали широкую дискуссию в отрасли. Сторонники полагают, что он раскрывает ключевую проблему в текущих исследованиях ИИ, а именно: как сделать ИИ действительно способным решать сложные проблемы, а не просто имитировать человеческое поведение. Оппоненты опасаются, что преждевременный отказ от RLHF может привести к отклонению в направлении развития ИИ.
Адрес статьи: https://arxiv.org/pdf/1706.03741.
Взгляды Карпати вызвали углубленные дискуссии о будущем направлении развития ИИ. Его сомнения по поводу RLHF побудили исследователей пересмотреть текущие методы обучения ИИ и изучить более эффективные пути с конечной целью создания настоящего искусственного интеллекта.