Прогресс больших языковых моделей (LLM) впечатляет, но они обнаруживают неожиданные недостатки в решении некоторых простых задач. Андрей Карпатий остро указал на феномен «зазубренного интеллекта», то есть LLM способен решать сложные задачи, но часто допускает ошибки в простых задачах. Это заставило задуматься об основных недостатках LLM и направлениях будущего улучшения. В этой статье мы подробно объясним это и рассмотрим, как лучше использовать LLM и избежать его ограничений.
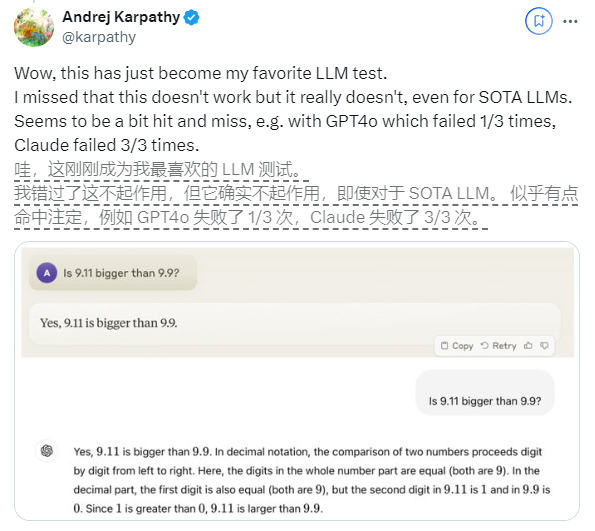
В последнее время, казалось бы, простой вопрос «9.11 больше, чем 9.9?» привлек широкое внимание во всем мире. Почти все большие языковые модели (LLM) допустили ошибки по этому вопросу. Это явление привлекло внимание Андрея Карпати, эксперта в области искусственного интеллекта. Начиная с этого вопроса, он глубоко обсудил существенные недостатки и направления дальнейшего совершенствования современной технологии больших моделей.
Карпати называет это явление «зубчатым интеллектом» или «зубчатым интеллектом», указывая на то, что, хотя современные LLM могут выполнять множество сложных задач, таких как решение сложных математических задач, они терпят неудачу в некоторых, казалось бы, простых задачах. плохо справляется с задачами, и этот дисбаланс интеллекта похож на форму пилы.
Например, исследователь OpenAI Ноам Браун обнаружил, что LLM плохо работает в игре «Крестики-нолики»: модель не может принимать правильные решения, даже когда пользователь был близок к победе. Карпати считает, что это происходит потому, что модель принимает «неоправданные» решения, в то время как Ноам считает, что это может быть связано с отсутствием соответствующего обсуждения стратегий в обучающих данных.
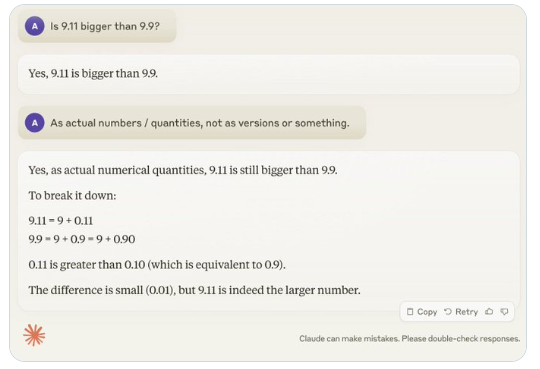
Другой пример — ошибка, которую допускает LLM при подсчете буквенно-цифровых величин. Даже последняя версия Llama 3.1 дает неправильные ответы на простые вопросы. Карпати объяснил, что это связано с отсутствием у LLM «самопознания», то есть модель не может отличить, что она может, а что не может делать, в результате чего модель «уверенно уверена» при решении задач.
Чтобы решить эту проблему, Карпати упомянул решение, предложенное в статье Llama3.1, опубликованной Meta. В документе рекомендуется добиться согласования модели на этапе после обучения, чтобы модель развивала самосознание и знала то, что знает. Проблему иллюзий нельзя устранить, просто добавив фактические знания. Команда Llama предложила метод обучения под названием «обнаружение знаний», который побуждает модель отвечать только на те вопросы, которые она понимает, и отказывается давать неопределенные ответы.
Карпати считает, что, хотя существуют различные проблемы с нынешними возможностями ИИ, они не являются фундаментальными недостатками и существуют реальные решения. Он предположил, что нынешняя идея обучения ИИ заключается в том, чтобы просто «имитировать человеческие ярлыки и расширить масштабы». Чтобы продолжать совершенствовать интеллект ИИ, необходимо проделать дополнительную работу на протяжении всего процесса разработки.
Пока проблема не будет полностью решена, если LLM будут использоваться в производстве, им следует ограничиваться задачами, с которыми они хорошо справляются, учитывать «неровные края» и постоянно привлекать людей. Таким образом, мы сможем лучше использовать потенциал ИИ, избегая при этом рисков, вызванных его ограничениями.
В целом, «неровный интеллект» LLM — это проблема, с которой в настоящее время сталкивается область искусственного интеллекта, но она не является непреодолимой. Совершенствуя методы обучения, повышая самосознание модели и тщательно применяя ее к реальным сценариям, мы можем лучше использовать преимущества LLM и способствовать дальнейшему развитию технологий искусственного интеллекта.