Быстрое развитие больших языковых моделей (LLM) принесло удивительные возможности обработки естественного языка, но их огромные требования к вычислительной мощности и хранению ограничивают их популярность. Для запуска модели со 176 миллиардами параметров требуются сотни гигабайт дискового пространства и несколько высокопроизводительных графических процессоров, что делает ее дорогой и сложной для масштабирования. Чтобы решить эту проблему, исследователи сосредоточились на методах сжатия моделей, таких как квантование, чтобы уменьшить размер модели и требования к ее работе, но они также сталкиваются с риском потери точности.
Искусственный интеллект (ИИ) становится умнее, особенно большие языковые модели (LLM), которые прекрасно справляются с обработкой естественного языка. Но знаете ли вы, что для их поддержки необходимы огромные вычислительные мощности и пространство для хранения данных?
Многоязычная модель Bloom со 176 миллиардами параметров требует не менее 350 ГБ пространства только для хранения весов модели, а также для ее работы требуется несколько продвинутых графических процессоров. Это не только дорого, но и трудно популяризировать.
Чтобы решить эту проблему, исследователи предложили метод, называемый «количественной оценкой». Количественная оценка похожа на «уменьшение размера» мозга ИИ. Сопоставляя веса и активации модели с форматом данных с меньшим числом цифр, это не только уменьшает размер модели, но и ускоряет скорость ее работы. Но этот процесс также сопряжен с риском, и некоторая точность может быть потеряна.
Столкнувшись с этой проблемой, исследователи из Университета Бэйхан и SenseTime Technology совместно разработали набор инструментов LLMC. LLMC — это личный тренер по снижению веса для ИИ. Он может помочь исследователям и разработчикам найти наиболее подходящий план по снижению веса, который сможет сделать модель ИИ легче, не влияя на уровень ее интеллекта.
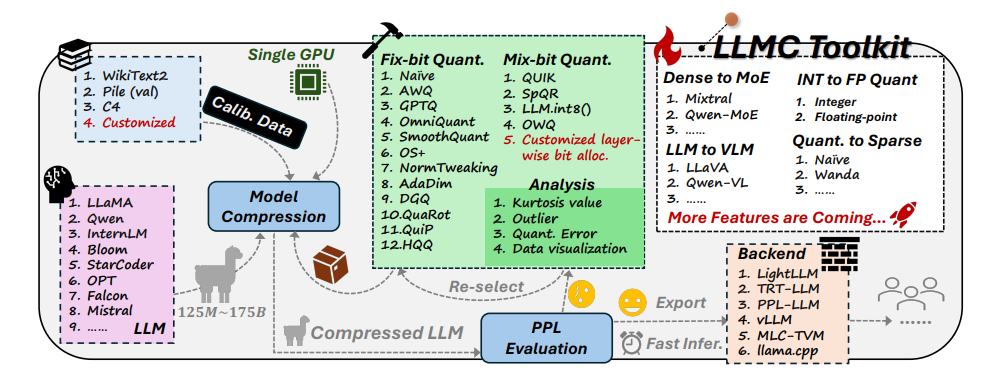
Инструментарий LLMC имеет три основные функции:
Диверсификация: LLMC предлагает 16 различных количественных методов, что похоже на подготовку 16 различных рецептов похудания для ИИ. Независимо от того, хочет ли ваш ИИ похудеть повсеместно или локально, LLMC может удовлетворить ваши потребности.
Низкая стоимость: LLMC очень экономит ресурсы и требует лишь небольшой аппаратной поддержки даже для обработки очень больших моделей. Например, используя только графический процессор A100 емкостью 40 ГБ, можно настроить и оценить модель OPT-175B со 175 миллиардами параметров. Это так же эффективно, как тренировать олимпийского чемпиона на домашней беговой дорожке!
Высокая совместимость: LLMC поддерживает различные настройки квантования и форматы моделей, а также совместим с различными серверными модулями и аппаратными платформами. Это как универсальный тренажер, который поможет вам разработать подходящий план тренировок независимо от того, какое оборудование вы используете.
Практическое применение LLMC: делаем ИИ умнее и энергоэффективнее
Появление инструментария LLMC обеспечивает комплексный и справедливый эталонный тест для количественной оценки больших языковых моделей. Он учитывает три ключевых фактора: данные обучения, алгоритм и формат данных, чтобы помочь пользователям найти лучшее решение для оптимизации производительности.
В практических приложениях LLMC может помочь исследователям и разработчикам более эффективно интегрировать соответствующие алгоритмы и низкобитные форматы, способствуя популяризации сжатия больших языковых моделей. Это означает, что в будущем мы можем увидеть более легкие, но столь же мощные приложения искусственного интеллекта.
Авторы статьи также поделились некоторыми интересными выводами и предложениями:
При выборе обучающих данных вам следует выбрать набор данных, который больше похож на тестовые данные с точки зрения распределения словарного запаса, точно так же, как когда люди худеют, им необходимо выбирать подходящие рецепты, исходя из их собственных обстоятельств.
Что касается алгоритмов количественной оценки, они исследовали влияние трех основных методов трансформации, обрезки и реконструкции, а также сравнивали влияние различных методов упражнений на потерю веса.
Выбирая между целочисленным квантованием и квантованием с плавающей запятой, они обнаружили, что квантование с плавающей запятой имеет больше преимуществ при обработке сложных ситуаций, в то время как целочисленное квантование может быть лучше в некоторых особых случаях. Это похоже на то, что на разных этапах похудения необходима разная интенсивность упражнений.
Появление инструментария LLMC привнесло новую тенденцию в сферу искусственного интеллекта. Он не только является мощным помощником для исследователей и разработчиков, но и указывает направление будущего развития ИИ. Благодаря LLMC мы можем ожидать появления более легких и высокопроизводительных приложений ИИ, которые позволят ИИ по-настоящему войти в нашу повседневную жизнь.
Адрес проекта: https://github.com/ModelTC/llmc
Адрес статьи: https://arxiv.org/pdf/2405.06001.
В целом, набор инструментов LLMC обеспечивает эффективное решение проблемы потребления ресурсов больших языковых моделей. Он не только снижает стоимость и порог работы модели, но также повышает эффективность и удобство использования модели, внедряя ее в модель. популяризация и развитие ИИ новой жизненной силы. В будущем мы можем рассчитывать на появление более легких приложений искусственного интеллекта на базе LLMC, которые принесут больше удобства в нашу жизнь.