В бурно развивающейся области искусственного интеллекта все большее внимание уделяется методам сбора данных. В этой статье исследуются разногласия, вызванные крупномасштабным сбором данных командой Claude из компании Anthropic, занимающейся искусственным интеллектом. Программа-сканер команды Claude ClaudeBot просканировала большой объем данных с нескольких веб-сайтов без авторизации, что не только нарушило правила веб-сайта, но и привело к огромному потреблению ресурсов сервера, что вызвало широкую критику и обеспокоенность. Этот инцидент подчеркивает противоречие между развитием ИИ и защитой авторских прав на данные, заставляя отрасль переосмыслить этические и правовые нормы сбора данных.
Причиной инцидента стало то, что сканер команды Клода посетил сервер компании 1 миллион раз в течение 24 часов, бесплатно сканируя контент веб-сайта. Такое поведение не только явно игнорировало объявление о запрете сканирования веб-сайта, но и принудительно занимало большой объем ресурсов сервера.
Несмотря на все усилия по защите, компания-жертва в конечном итоге не смогла помешать команде Клода получить данные. Руководители компании гневно обратились в социальные сети, чтобы осудить действия команды Клода. Многие пользователи сети также выразили свое недовольство, а некоторые даже предложили использовать слово «воровство» для описания такого поведения.
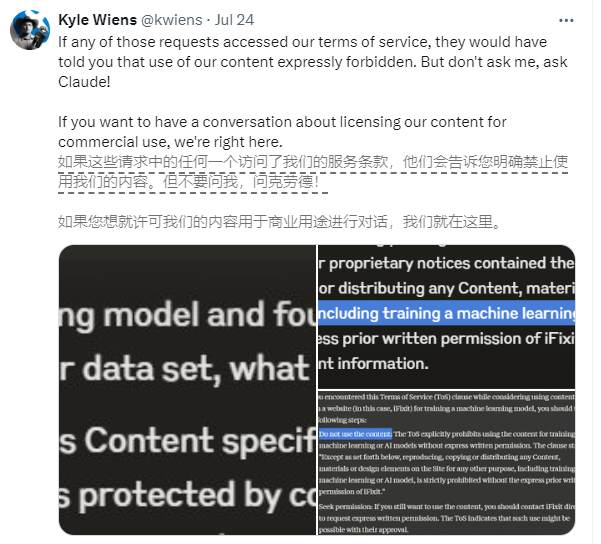
Замешанной компанией является iFixit, американский веб-сайт электронной коммерции и практических рекомендаций. iFixit предлагает миллионы страниц бесплатных онлайн-руководств по ремонту бытовой электроники и гаджетов. Однако iFixit обнаружила, что программа-сканер Клода ClaudeBot инициировала большое количество запросов за короткий период времени, получив доступ к 10 ТБ файлов за один день и в общей сложности к 73 ТБ за весь май.
Генеральный директор iFixit Кайл Винс заявил, что ClaudeBot без разрешения украл все их данные и занял ресурсы сервера. Хотя iFixit прямо заявляет на своем веб-сайте, что несанкционированное извлечение данных запрещено, команда Клода, похоже, закрывает на это глаза.
Поведение команды Клода не уникально. В апреле этого года форум Linux Mint также пострадал от частых посещений ClaudeBot, из-за чего форум работал медленно или даже аварийно завершал свою работу. Кроме того, некоторые отметили, что помимо Клода и GPT OpenAI, существует множество других компаний, занимающихся искусственным интеллектом, которые также игнорируют настройки robots.txt веб-сайта и принудительно собирают данные.
Столкнувшись с этой ситуацией, владельцам веб-сайтов было предложено добавить на страницу поддельный контент с отслеживаемой или уникальной информацией, чтобы определить, были ли данные удалены незаконно. iFixit действительно пошла на этот шаг и обнаружила, что их данные были очищены не только Клодом, но и OpenAI.
Инцидент вызвал широкую дискуссию о методах сбора данных компаниями, занимающимися искусственным интеллектом. С одной стороны, разработка ИИ требует большого объема данных для ее поддержки; с другой стороны, сбор данных также должен осуществляться с соблюдением прав и правил владельца веб-сайта. Как найти баланс между содействием технологическому прогрессу и защитой авторских прав – вопрос, над которым должна задуматься вся индустрия.
Инцидент со сбором данных командой Клода забил тревогу, напомнив компаниям, занимающимся искусственным интеллектом, что, стремясь к технологическому прогрессу, они должны уважать права интеллектуальной собственности, соблюдать законы и правила и активно изучать соответствующие способы получения данных. Только таким образом мы сможем обеспечить здоровое развитие технологий искусственного интеллекта и избежать ущерба репутации отрасли и общественному доверию из-за ненадлежащего поведения.