Опыт Meta в обучении крупномасштабной языковой модели Llama 3.1 показал нам беспрецедентные проблемы и возможности в разработке ИИ. В огромном кластере из 16 384 графических процессоров в среднем каждые 3 часа в течение 54-дневного периода обучения происходил сбой. Это не только подчеркнуло быстрый рост масштаба модели ИИ, но и выявило огромные узкие места в стабильности суперкомпьютеров. система. В этой статье мы рассмотрим проблемы, с которыми Meta столкнулась в процессе обучения Llama 3.1, стратегии, которые они приняли для решения этих проблем, и проанализируем их последствия для всей индустрии искусственного интеллекта.
В мире искусственного интеллекта каждый прорыв сопровождается потрясающими данными. Представьте, что одновременно работают 16 384 графических процессора. Это не сцена из научно-фантастического фильма, а реальное изображение Меты во время обучения последней модели Llama3.1. Однако за этим технологическим праздником скрывается сбой, который происходит в среднем каждые 3 часа. Эта поразительная цифра не только демонстрирует скорость развития ИИ, но и обнажает огромные проблемы, с которыми сталкиваются современные технологии.
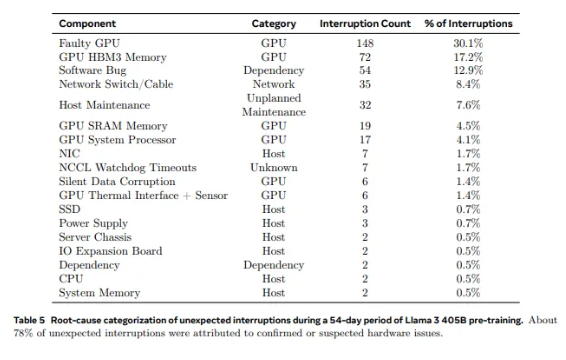
С 2028 графических процессоров, используемых в Llama1, до 16 384 графических процессоров, используемых в Llama3.1, такой скачок роста является не только количественным изменением, но и серьезным вызовом стабильности существующей суперкомпьютерной системы. Данные исследования Meta показывают, что в течение 54-дневного цикла обучения Llama3.1 произошло в общей сложности 419 неожиданных сбоев компонентов, около половины из которых были связаны с графическим процессором H100 и его памятью HBM3. Эти данные заставляют нас задуматься: одновременно с достижением прорыва в производительности ИИ повысилась и надежность системы?
На самом деле, в сфере суперкомпьютеров есть неоспоримый факт: чем больше масштаб, тем сложнее избежать сбоев. Обучающий кластер Llama 3.1 компании Meta состоит из десятков тысяч процессоров, сотен тысяч других чипов и сотен миль кабелей — уровень сложности, сравнимый с уровнем сложности нейронной сети небольшого города. В таком гиганте неисправности кажутся обычным явлением.
Столкнувшись с частыми неудачами, команда «Мета» не оказалась беспомощной. Они приняли ряд стратегий решения проблемы: сократили время запуска заданий и контрольных точек, разработали собственные диагностические инструменты, использовали бортовой самописец PyTorch NCCL и т. д. Эти меры не только повышают отказоустойчивость системы, но и расширяют возможности автоматизированной обработки. Инженеры Meta подобны современным пожарным, готовым потушить любые возгорания, которые могут нарушить тренировочный процесс.
Однако проблемы связаны не только с самим оборудованием. Факторы окружающей среды и колебания энергопотребления также создают неожиданные проблемы для суперкомпьютерных кластеров. Команда Meta обнаружила, что дневные и ночные изменения температуры и резкие колебания энергопотребления графического процессора окажут существенное влияние на производительность тренировок. Это открытие напоминает нам, что, стремясь к технологическим прорывам, мы не можем игнорировать важность управления окружающей средой и энергопотреблением.
Процесс обучения Llama3.1 можно назвать окончательной проверкой стабильности и надежности суперкомпьютерной системы. Стратегии, принятые командой Meta для решения проблем, и разработанные автоматизированные инструменты предоставляют ценный опыт и вдохновение для всей индустрии искусственного интеллекта. Несмотря на трудности, у нас есть основания полагать, что при постоянном развитии технологий будущие суперкомпьютерные системы станут более мощными и стабильными.
В эпоху быстрого развития технологий искусственного интеллекта попытка Меты, несомненно, является смелым приключением. Это не только расширяет границы производительности моделей искусственного интеллекта, но и показывает нам реальные проблемы, с которыми мы сталкиваемся при достижении пределов. Давайте с нетерпением ждем безграничных возможностей, которые открывает технология искусственного интеллекта, и в то же время хвалим тех инженеров, которые неустанно работают на переднем крае технологий. Каждая попытка, каждая неудача и каждый прорыв, который они совершают, прокладывают путь человеческому технологическому прогрессу.
Ссылки:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- один отказ каждые три часа для кластера метас-16384-GPU
Учебный пример Llama 3.1 дал нам ценные уроки и указал на будущее направление развития суперкомпьютерных систем: добиваясь производительности, мы должны придавать большое значение стабильности и надежности системы и активно изучать стратегии борьбы с различными сбоями. Только так мы сможем обеспечить дальнейшее и стабильное развитие технологий искусственного интеллекта и принести пользу человечеству.