NVIDIA недавно выпустила серию небольших языковых моделей Minitron, включая версии 4B и 8B. Этот шаг направлен на снижение затрат на обучение и развертывание больших языковых моделей и позволит большему количеству разработчиков легко использовать эту передовую технологию. За счет технологий «обрезки» и «дистилляции знаний» модель Minitron существенно уменьшает размеры модели, сохраняя при этом производительность, сравнимую с крупными моделями, а по некоторым показателям даже превосходит другие известные модели. Это имеет большое значение для содействия популяризации технологий искусственного интеллекта.
Недавно NVIDIA предприняла новые шаги в области искусственного интеллекта. Они выпустили серию небольших языковых моделей Minitron, включая версии 4B и 8B. Эти модели не только увеличивают скорость обучения в 40 раз, но и упрощают разработчикам использование их для различных приложений, таких как перевод, анализ настроений и разговорный искусственный интеллект.
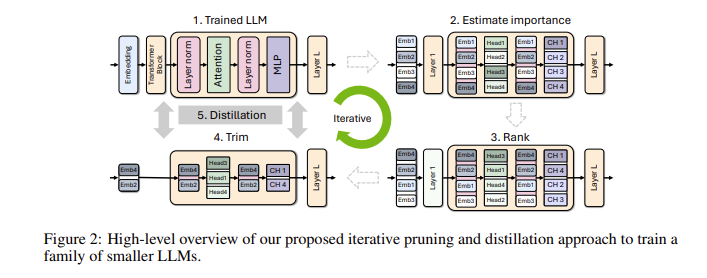
Вы можете спросить, почему так важны небольшие языковые модели? На самом деле, хотя традиционные большие языковые модели обладают высокой производительностью, затраты на их обучение и развертывание очень высоки, и они часто требуют большого количества вычислительных ресурсов и данных. Чтобы сделать эти передовые технологии доступными для большего числа людей, исследовательская группа NVIDIA придумала блестящий способ: объединить две технологии: «сокращение» и «дистилляцию знаний» для эффективного уменьшения размера модели.
В частности, исследователи сначала начнут с существующей большой модели и обрежут ее. Они оценивают важность каждого нейрона, слоя или центра внимания в модели и удаляют менее важные. Таким образом, модель становится намного меньше, а ресурсы и время, необходимые для обучения, также значительно сокращаются. Затем они также будут использовать небольшой набор данных для проведения обучения по дистилляции знаний на сокращенной модели, чтобы восстановить точность модели. Удивительно, но этот процесс не только экономит деньги, но и улучшает характеристики модели!
В реальных испытаниях исследовательская группа NVIDIA добилась хороших результатов на семействе моделей Nemotron-4. Они успешно уменьшили размер модели в 2–4 раза, сохранив при этом аналогичные характеристики. Что еще более интересно, так это то, что модель 8B превосходит другие известные модели, такие как Mistral7B и LLaMa-38B, по множеству показателей и требует в процессе обучения в 40 раз меньше обучающих данных, экономя вычислительные затраты в 1,8 раза. Представьте себе, что это значит? Больше разработчиков смогут испытать мощные возможности искусственного интеллекта с меньшими ресурсами и затратами!
NVIDIA делает эти оптимизированные модели Minitron открытыми на Huggingface, чтобы каждый мог свободно ими пользоваться.
Вход в демо-версию: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Основные моменты:
** Повышенная скорость обучения **: Скорость обучения модели Minitron в 40 раз выше, чем у традиционных моделей, что позволяет разработчикам экономить время и силы.
**Экономия**. Благодаря технологии сокращения и дистилляции знаний значительно сокращаются вычислительные ресурсы и объем данных, необходимые для обучения.
? **Обмен открытым исходным кодом**: исходный код модели Minitron размещен на Huggingface, поэтому больше людей могут легко получить к ней доступ и использовать ее, что способствует популяризации технологии искусственного интеллекта.
Открытый исходный код модели Minitron знаменует собой важный прорыв в практическом применении малых языковых моделей. Это также указывает на то, что технология искусственного интеллекта станет более популярной и простой в использовании, расширяя возможности разработчиков и сценариев применения. В будущем мы можем ожидать появления новых подобных инноваций, которые будут способствовать непрерывному развитию технологий искусственного интеллекта.