Последняя модель ChatQA2, выпущенная Nvidia AI, достигла значительных прорывов в области понимания длинного текстового контекста и расширенной генерации поиска (RAG). Он основан на мощной модели Llama3, которая значительно улучшает возможности следования инструкциям, производительность RAG и возможности понимания длинного текста за счет расширения контекстного окна до 128 000 токенов и применения трехэтапной точной настройки инструкций. ChatQA2 способен поддерживать контекстную согласованность и высокую запоминаемость при обработке больших текстовых данных, а также продемонстрировал производительность, сравнимую с GPT-4-Turbo в нескольких тестах производительности, и даже превзошел ее в некоторых аспектах. Это знаменует собой значительный прогресс в способности больших языковых моделей обрабатывать длинные тексты.
Прорыв в производительности: ChatQA2 значительно улучшает возможности следования инструкциям, производительность RAG и понимание длинного текста за счет расширения контекстного окна до 128 000 токенов и применения трехэтапного процесса настройки инструкций. Этот технологический прорыв позволяет модели поддерживать контекстную согласованность и высокую запоминаемость при обработке наборов данных объемом до 1 миллиарда токенов.
Технические подробности: ChatQA2 был разработан с использованием подробных и воспроизводимых технических решений. Модель сначала расширяет контекстное окно Llama3-70B с 8 000 до 128 000 токенов посредством непрерывного предварительного обучения. Затем был применен трехэтапный процесс настройки инструкций, чтобы гарантировать, что модель сможет эффективно справляться с различными задачами.
Результаты оценки: В оценке InfiniteBench ChatQA2 достиг точности, сравнимой с GPT-4-Turbo-2024-0409, в таких задачах, как длинное текстовое резюме, вопросы и ответы, множественный выбор и диалог, и превзошел ее в тесте RAG. Это достижение подчеркивает широкие возможности ChatQA2 в контексте различной длины и функций.
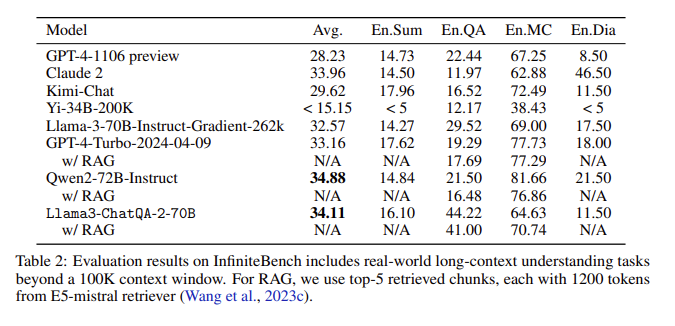
Решение ключевых проблем: ChatQA2 решает ключевые проблемы в процессе RAG, такие как фрагментация контекста и низкий уровень отзыва, с помощью современного средства извлечения длинного текста для повышения точности и эффективности поиска.
Расширяя контекстное окно и реализуя трехэтапный процесс настройки инструкций, ChatQA2 достигает понимания длинного текста и производительности RAG, сравнимой с GPT-4-Turbo. Эта модель обеспечивает гибкие решения для множества последующих задач, балансируя между точностью и эффективностью благодаря передовым методам генерации длинных текстов и расширенному поиску.
Бумажный вход: https://arxiv.org/abs/2407.14482.
Появление ChatQA2 открывает новые возможности для обработки длинных текстов и приложений RAG. Его эффективность и точность обеспечивают важную справочную ценность для будущего развития искусственного интеллекта. Открытые исследования этой модели также способствуют сотрудничеству между научными кругами и промышленностью, способствуя дальнейшему прогрессу в этой области. Надеемся увидеть в будущем еще больше инновационных приложений на основе этой модели.