Llama 3.1, эта гигантская языковая модель с открытым исходным кодом и 405 миллиардами параметров, вызвала огромный шок в сфере ИИ из-за утечек без официального релиза. Его производительность настолько высока, что в некоторых тестах производительности он даже превосходит GPT-4o, устанавливая новый стандарт для моделей с открытым исходным кодом. Жаркая дискуссия на Reddit еще раз доказывает ее влияние на сообщество ИИ. В этой статье мы углубимся в производительность, особенности и меры безопасности Llama 3.1 и представим эту загадочную модель.
В сеть попала версия Llama3.1. Вы правильно поняли: эта модель с открытым исходным кодом и 405 миллиардами параметров вызвала бурю негодования на Reddit. Вероятно, это самая близкая на сегодняшний день модель с открытым исходным кодом к GPT-4o и даже превосходит ее в некоторых аспектах.
Llama3.1 — это большая языковая модель, разработанная Meta (ранее Facebook). Хотя официального релиза пока нет, утекшая версия уже вызвала переполох в сообществе. Эта модель включает в себя не только базовую модель, но и результаты тестов 8B, 70B и максимальный параметр 405B.
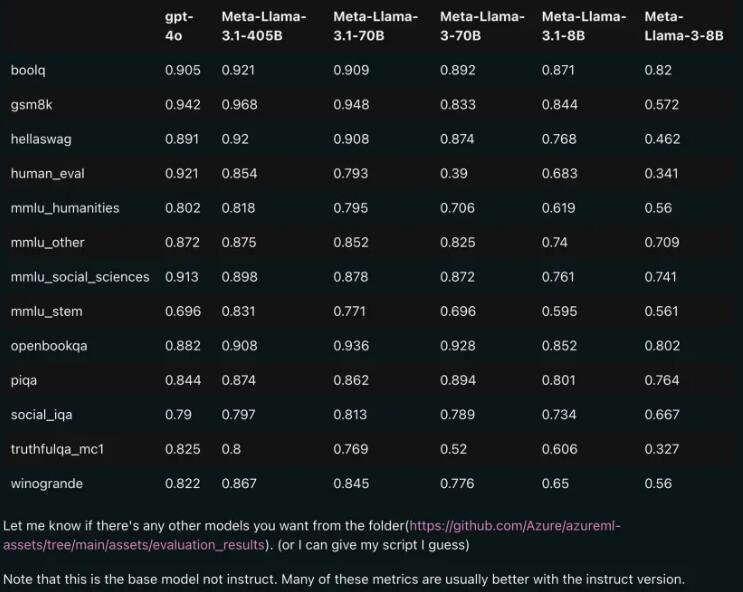
Сравнение производительности: Llama3.1 и GPT-4o
Судя по просочившимся результатам сравнения, даже версия Llama3.1 70B превзошла GPT-4o в нескольких тестах производительности. Впервые модель с открытым исходным кодом достигла уровня SOTA (самая передовая технология) по нескольким критериям. Люди не могут не вздохнуть: сила открытого исходного кода действительно мощная!
Особенности модели: многоязычная поддержка, более обширные данные обучения.
Модель Llama3.1 использует для обучения 15T+ токенов из общедоступных источников, а крайний срок получения данных для предварительного обучения — декабрь 2023 года. Он поддерживает не только английский, но и французский, немецкий, хинди, итальянский, португальский, испанский и тайский языки. Это делает его отличным вариантом для многоязычных разговоров.

Исследовательская группа Llama3.1 придает большое значение безопасности модели. Они использовали многогранный подход к сбору данных, который сочетал в себе созданные человеком и синтетические данные для снижения потенциальных рисков безопасности. Кроме того, в модели также представлены граничные и состязательные подсказки для улучшения контроля качества данных.
Источник карты модели: https://pastebin.com/9jGkYbXY#google_vignette
Утечка Llama 3.1, несомненно, окажет глубокое влияние на сферу искусственного интеллекта. Это не только демонстрирует огромный потенциал моделей с открытым исходным кодом, но и заставляет задуматься о безопасности моделей и этических вопросах. В будущем мы продолжим уделять внимание Llama 3.1 и ее последующему развитию и с нетерпением ждем, когда она принесет еще больше сюрпризов в развитие технологий искусственного интеллекта.