Конкуренция в области искусственного интеллекта жесткая, а рост моделей с открытым исходным кодом бросает вызов доминированию технологических гигантов. Недавно стартап по аппаратному обеспечению искусственного интеллекта Groq выпустил две языковые модели с открытым исходным кодом — Llama-3-Groq-70B-Tool-Use и Llama3Groq Tool Use 8B и добился впечатляющих результатов в рейтинге функциональных вызовов Беркли (BFCL). Среди них параметр 70B. версия превзошла фирменные модели OpenAI, Google, Anthropic и других компаний. Успех этих моделей заключается не только в их высокой производительности, но и в использовании этически сгенерированных синтетических данных в процессе обучения, что эффективно решает такие проблемы, как конфиденциальность данных и переобучение, а также предоставляет новые возможности для устойчивого развития области. пример искусственного интеллекта.
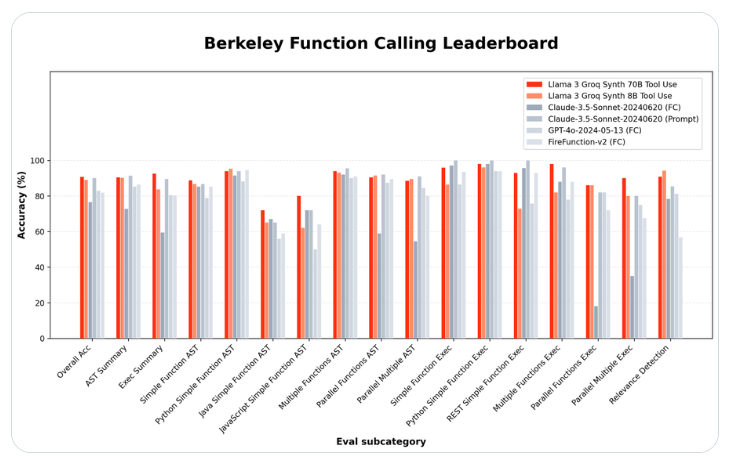
Стартап по аппаратному обеспечению искусственного интеллекта Groq выпустил две языковые модели с открытым исходным кодом, которые превосходят технологических гигантов в способности использовать специализированные инструменты. Новая модель Llama-3-Groq-70B-Tool-Use заняла первое место в рейтинге функциональных вызовов Беркли (BFCL), обогнав патентованные продукты таких компаний, как OpenAI, Google и Anthropic.
Руководитель проекта Groq Рик Ламерс объявил о прорыве в статье на X.com. Он сказал: «Я с гордостью объявляю о модели Llama3Groq Tool Use 8B и 70B. Это полностью доработанная версия инструмента с открытым исходным кодом Llama3, которая достигла позиции №1 в рейтинге BFCL, опередив все другие модели, включая проприетарные модели. Такие как Claude Sonnet3.5, GPT-4Turbo, GPT-4o и Gemini1.5Pro».
Синтетические данные и этический ИИ: новая парадигма в обучении моделей
Версия с более крупными параметрами 70B достигла общей точности 90,76% по BFCL, тогда как меньшая модель 8B набрала 89,06%, заняв третье место в общем зачете. Эти результаты показывают, что модели с открытым исходным кодом могут соответствовать или даже превосходить производительность альтернатив с закрытым исходным кодом при выполнении конкретных задач.
Грок разработал модели в сотрудничестве с исследовательской компанией искусственного интеллекта Glaive, используя полную настройку и оптимизацию прямых предпочтений (DPO) на базовой модели Llama-3 от Meta. Команда подчеркивает, что для обучения они используют только синтетические данные, созданные с соблюдением этических норм, решая общие проблемы, связанные с конфиденциальностью данных и переобучением.
Эти модели теперь доступны через API Groq и платформу Hugging Face. Эта доступность может ускорить инновации в областях, требующих сложного использования инструментов и вызовов функций, таких как автоматическое кодирование, анализ данных и интерактивные помощники искусственного интеллекта.
Groq также запустил публичную демо-версию Hugging Face Spaces, позволяющую пользователям взаимодействовать с моделью и непосредственно проверять возможности ее инструментов. Как и Gradio, который Hugging Face приобрела в декабре 2021 года, многие демо-версии Hugging Face Spaces созданы таким образом. Сообщество ИИ отреагировало с энтузиазмом, и многие исследователи и разработчики стремились изучить возможности этих моделей.
Основные моменты:
⭐ Модель искусственного интеллекта с открытым исходным кодом, выпущенная Groq, превосходит патентованные модели технологического гиганта при решении конкретных задач.
⭐ Используя синтетические данные для обучения, Groq решает общие проблемы конфиденциальности данных и переобучения при разработке моделей ИИ.
⭐ Запуск моделей с открытым исходным кодом может изменить путь развития области ИИ и способствовать более широкой доступности ИИ и развитию инновационных экосистем.
Успех модели Groq с открытым исходным кодом придал новую жизнь развитию области искусственного интеллекта, а также указывает на то, что модели с открытым исходным кодом будут играть все более важную роль в будущем. Применение синтетических данных дает новые идеи в решении таких проблем, как конфиденциальность данных и предвзятость модели, что заслуживает углубленного изучения и ссылки со стороны отрасли. Мы с нетерпением ожидаем появления в будущем более совершенных моделей с открытым исходным кодом, которые будут способствовать дальнейшему развитию технологий искусственного интеллекта.