Awesome LLM 3D
1.0.0
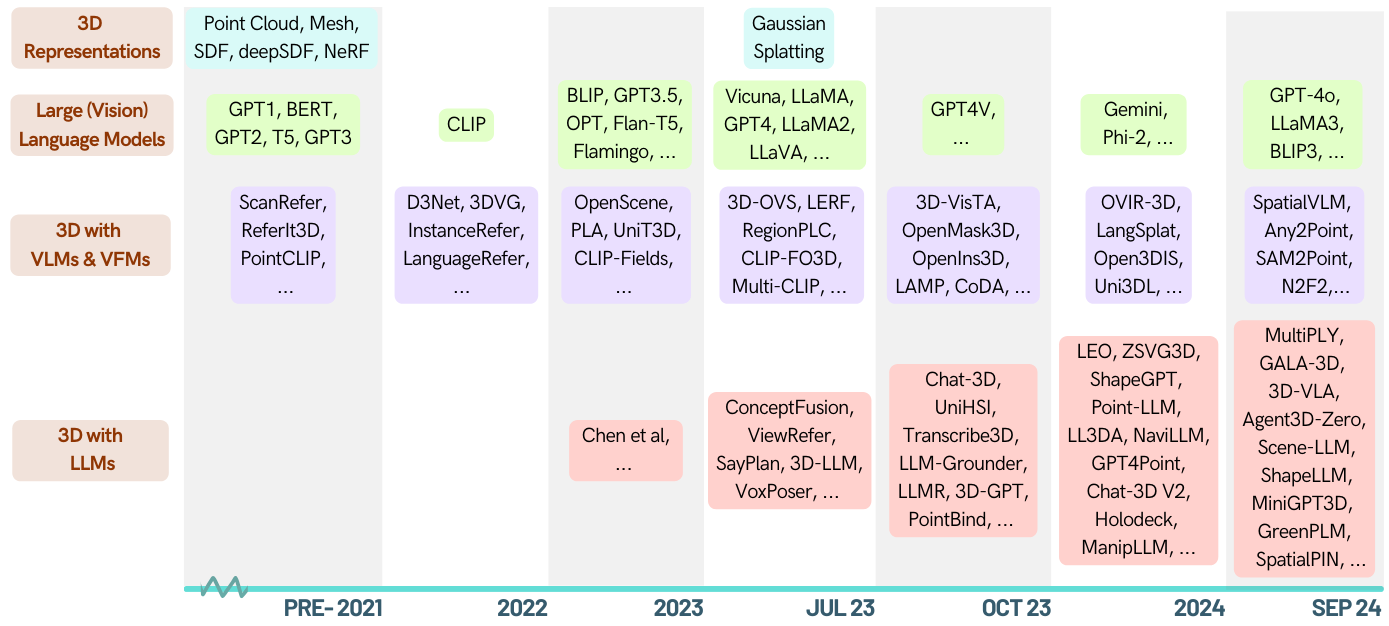
นี่คือรายการเอกสารเกี่ยวกับงานที่เกี่ยวข้องกับ 3D ที่ได้รับการเสริมพลังจากโมเดลภาษาขนาดใหญ่ (LLMS) มันมีงานต่าง ๆ รวมถึงความเข้าใจ 3 มิติการใช้เหตุผลการสร้างและตัวแทนที่เป็นตัวเป็นตน นอกจากนี้เรายังรวมโมเดลพื้นฐานอื่น ๆ (คลิป, SAM) สำหรับภาพรวมของพื้นที่นี้
นี่คือที่เก็บที่ใช้งานอยู่คุณสามารถรับชมการติดตามความก้าวหน้าล่าสุด หากคุณพบว่ามีประโยชน์โปรดแสดงความโปรดปรานของ repo นี้และอ้างอิงกระดาษ
[2024-05-16]? ตรวจสอบรายงานการสำรวจครั้งแรกในโดเมน 3D-LLM: เมื่อ LLMS ก้าวเข้าสู่โลก 3D: การสำรวจและการวิเคราะห์อภิมานของงาน 3D ผ่านแบบจำลองภาษาขนาดใหญ่หลายรูปแบบ
[2024-01-06] Runsen Xu เพิ่มข้อมูลตามลำดับเวลาและ Xianzheng MA จัดระเบียบใหม่ตามลำดับ ZA เพื่อให้ดีขึ้นหลังจากความก้าวหน้าล่าสุด
[2023-12-16] Xianzheng MA และ Yash Bhalgat ดูแลรายการนี้และเผยแพร่เวอร์ชันแรก;
Awesome-llm-3d
ความเข้าใจ 3D (LLM)
ความเข้าใจ 3 มิติ (แบบจำลองพื้นฐานอื่น ๆ )
การใช้เหตุผล 3 มิติ
รุ่น 3 มิติ
เอเจนต์ที่เป็นตัวเป็นตน 3D
มาตรฐาน 3D
การบริจาค
| วันที่ | คำสำคัญ | สถาบัน (ครั้งแรก) | กระดาษ | สิ่งพิมพ์ | คนอื่น |
|---|---|---|---|---|---|
| 2024-10-12 | สถานการณ์ 3d | uiuc | การรับรู้สถานการณ์มีความสำคัญในการใช้เหตุผลภาษา 3D การมองเห็น | cvpr '24 | โครงการ |
| 2024-09-28 | llava-3d | ฮูก | LLAVA-3D: เส้นทางที่เรียบง่าย แต่มีประสิทธิภาพในการเพิ่มขีดความสามารถของ LMMs ด้วยการรับรู้ 3D | arxiv | โครงการ |
| 2024-09-08 | MSR3D | บิ๊ก | การใช้เหตุผลหลายรูปแบบในฉาก 3 มิติ | Neurips '24 | โครงการ |
| 2024-08-28 | สีเขียว | เร่งรีบ | ข้อความมากขึ้นจุดน้อย: ไปสู่ความเข้าใจภาษาจุดที่ประหยัดข้อมูล 3 มิติ | arxiv | คนอื่น ๆ |
| 2024-06-17 | Llana | unibo | Llana: ภาษาใหญ่และผู้ช่วย Nerf | Neurips '24 | โครงการ |
| 2024-06-07 | เชิงพื้นที่ | ฟอร์ดฟอร์ด | SpatialPin: เพิ่มขีดความสามารถในการใช้เหตุผลเชิงพื้นที่ของแบบจำลองภาษาวิสัยทัศน์ผ่านการกระตุ้นและโต้ตอบ 3D Priors | Neurips '24 | โครงการ |
| 2024-06-03 | อวกาศ | UCSD | spatialrgpt: การใช้เหตุผลเชิงพื้นที่ในรูปแบบภาษาวิสัยทัศน์ | Neurips '24 | คนอื่น ๆ |
| 2024-05-02 | minigpt-3d | เร่งรีบ | MINIGPT-3D: จัดแนวเมฆจุด 3D อย่างมีประสิทธิภาพกับโมเดลภาษาขนาดใหญ่โดยใช้ 2D Priors | ACM MM '24 | โครงการ |
| 2024-02-27 | คนโง่ | xjtu | Shapellm: การทำความเข้าใจวัตถุ 3 มิติสากลสำหรับการโต้ตอบที่เป็นตัวเป็นตน | arxiv | โครงการ |
| 2024-01-22 | spatialvlm | Google DeepMind | spatialvlm: การสิ้นสุดแบบจำลองภาษาวิสัยทัศน์ที่มีความสามารถในการใช้เหตุผลเชิงพื้นที่ | cvpr '24 | โครงการ |
| 2023-12-21 | LIDAR-LLM | PKU | LIDAR-LLM: การสำรวจศักยภาพของแบบจำลองภาษาขนาดใหญ่สำหรับการทำความเข้าใจ LIDAR 3D | arxiv | โครงการ |
| 2023-12-15 | 3Dap | ห้องแล็บเซี่ยงไฮ้ | 3DaxiesPrompts: ปลดปล่อยความสามารถในการทำงานเชิงพื้นที่ 3D ของ GPT-4V | arxiv | โครงการ |
| 2023-12-13 | ฉากแชท | zju | ฉากแชท: เชื่อมโยงฉาก 3 มิติและโมเดลภาษาขนาดใหญ่พร้อมตัวระบุวัตถุ | Neurips '24 | คนอื่น ๆ |
| 2023-12-5 | gpt4point | ฮูก | GPT4Point: เฟรมเวิร์กแบบครบวงจรสำหรับการทำความเข้าใจและสร้างภาษาจุด | arxiv | คนอื่น ๆ |
| 2023-11-30 | ll3da | มหาวิทยาลัย Fudan | LL3DA: การปรับแต่งคำแนะนำแบบอินเทอร์แอคทีฟสำหรับการทำความเข้าใจเกี่ยวกับ Omni-3d การใช้เหตุผลและการวางแผน | arxiv | คนอื่น ๆ |
| 2023-11-26 | ZSVG3D | Cuhk (SZ) | การเขียนโปรแกรมด้วยภาพสำหรับการกราวด์ภาพ 3 มิติแบบเปิด-วูคบูลารี 3 มิติ | arxiv | โครงการ |
| 2023-11-18 | สิงห์ | บิ๊ก | ตัวแทนทั่วไปที่เป็นตัวเป็นตนในโลก 3 มิติ | arxiv | คนอื่น ๆ |
| 2023-10-14 | jm3d-llm | มหาวิทยาลัยเซียะมิน | JM3D & JM3D-LLM: ยกระดับการเป็นตัวแทน 3D ด้วยตัวชี้นำหลายโมดอลร่วม | ACM MM '23 | คนอื่น ๆ |
| 2023-10-10 | uni3d | ชาว Baai | Uni3d: สำรวจการเป็นตัวแทน 3 มิติแบบครบวงจรในระดับ | iclr '24 | โครงการ |
| 2023-9-27 | - | Kaust | การโต้ตอบรูปร่าง 3 มิติ | Siggraph Asia '23 | - |
| 2023-9-21 | llm-grounder | U-Mich | LLM-Grounder: การลงดินภาพ 3 มิติแบบเปิดโล่งด้วยรูปแบบภาษาขนาดใหญ่เป็นตัวแทน | ICRA '24 | คนอื่น ๆ |
| 2023-9-1 | จุดที่มีรอยด่าง | คิว | Point-Bind & Point-LLM: การจัดตำแหน่งคลาวด์จุดที่มีหลายรูปแบบสำหรับความเข้าใจ 3 มิติการสร้างและการเรียนการสอนต่อไปนี้ | arxiv | คนอื่น ๆ |
| 2023-8-31 | Pointllm | คิว | Pointllm: เพิ่มขีดความสามารถของแบบจำลองภาษาขนาดใหญ่เพื่อทำความเข้าใจกับพอยต์คลาวด์ | ECCV '24 | คนอื่น ๆ |
| 2023-8-17 | แชท -3d | zju | แชท -3D: การปรับรูปแบบภาษาขนาดใหญ่อย่างมีประสิทธิภาพสำหรับบทสนทนาสากลของฉาก 3D | arxiv | คนอื่น ๆ |
| 2023-8-8 | 3D-Vista | บิ๊ก | 3D-Vista: หม้อแปลงที่ผ่านการฝึกอบรมมาก่อนสำหรับการมองเห็น 3D และการจัดตำแหน่งข้อความ | ICCV '23 | คนอื่น ๆ |
| 2023-7-24 | 3d-llm | ยูซีแอลเอ | 3D-LLM: การฉีดโลก 3D เป็นแบบจำลองภาษาขนาดใหญ่ | Neurips '23 | คนอื่น ๆ |
| 2023-3-29 | ดู | คิว | ViewRefer: เข้าใจความรู้หลายมุมมองสำหรับกราวด์ภาพ 3 มิติ | ICCV '23 | คนอื่น ๆ |
| 2022-9-12 | - | มิกซ์ | ใช้ประโยชน์จากแบบจำลองภาษาขนาดใหญ่ (ภาพ) สำหรับการทำความเข้าใจฉากหุ่นยนต์ 3 มิติ | arxiv | คนอื่น ๆ |
| รหัสประจำตัว | คำสำคัญ | สถาบัน (ครั้งแรก) | กระดาษ | สิ่งพิมพ์ | คนอื่น |
|---|---|---|---|---|---|
| 2024-10-12 | พจนานุกรม | uiuc | Lexicon3d: การตรวจสอบแบบจำลองพื้นฐานภาพสำหรับการทำความเข้าใจฉาก 3 มิติที่ซับซ้อน | Neurips '24 | โครงการ |
| 2024-10-07 | diff2scene | CMU | การแบ่งส่วนความหมาย 3D แบบเปิด-vocabulary กับโมเดลการแพร่กระจายข้อความไปยังภาพ | ECCV 2024 | โครงการ |
| 2024-04-07 | any2point | ห้องแล็บเซี่ยงไฮ้ | Any2Point: เพิ่มขีดความสามารถของโมเดลขนาดใหญ่ใด ๆ เพื่อความเข้าใจ 3 มิติที่มีประสิทธิภาพ | ECCV 2024 | คนอื่น ๆ |
| 2024-03-16 | N2F2 | Oxford-VGG | N2F2: การทำความเข้าใจฉากลำดับชั้นด้วยฟีเจอร์ฟีเจอร์ประสาทซ้อน | arxiv | - |
| 2023-12-17 | SAI3D | PKU | Sai3d: แบ่งส่วนอินสแตนซ์ใด ๆ ในฉาก 3 มิติ | arxiv | โครงการ |
| 2023-12-17 | open3dis | Vinai | Open3DIS: การแบ่งส่วนอินสแตนซ์ 3D แบบเปิด-vocabulary พร้อมคำแนะนำหน้ากาก 2D | arxiv | โครงการ |
| 2023-11-6 | ovir-3d | มหาวิทยาลัยรัทเกอร์ส | OVIR-3D: การดึงอินสแตนซ์อินสแตนซ์ 3D แบบเปิด-vocabulary โดยไม่มีการฝึกอบรมเกี่ยวกับข้อมูล 3D | Corl '23 | คนอื่น ๆ |
| 2023-10-29 | OpenMask3d | ETH | OpenMask3d: การแบ่งส่วนอินสแตนซ์ 3D แบบเปิด-vocabulary | Neurips '23 | โครงการ |
| 2023-10-5 | ฟิวชั่นแบบเปิด | - | Open-Fusion: การทำแผนที่ 3D แบบเปิดโล่งแบบเรียลไทม์และการเป็นตัวแทนฉากที่สามารถสอบถามได้ | arxiv | คนอื่น ๆ |
| 2023-9-22 | OV-3DDET | Hkust | CODA: การค้นพบกล่องนวนิยายร่วมกันและการจัดตำแหน่งข้ามโมดอลสำหรับการตรวจจับวัตถุ 3 มิติแบบเปิด-vocabulary | Neurips '23 | คนอื่น ๆ |
| 2023-9-19 | โคมไฟ | - | จากภาษาไปสู่ 3D Worlds: การปรับรูปแบบภาษาสำหรับการรับรู้จุดคลาวด์ | OpenReview | - |
| 2023-9-15 | Opennerf | - | Opennerf: การแบ่งเซ็กเมนต์ฉากประสาท 3 มิติด้วยคุณสมบัติพิกเซลที่ชาญฉลาดและมุมมองนวนิยายที่แสดงผล | OpenReview | คนอื่น ๆ |
| 2023-9-1 | openins3d | เคมบริดจ์ | OpenIns3D: Snap and Lookup สำหรับการแบ่งส่วนอินสแตนซ์แบบโอเพนวูคบูลารี 3 มิติ | arxiv | โครงการ |
| 2023-6-7 | ลิฟท์คอนทราสต์ | Oxford-VGG | การยกระดับความคมชัด: การแบ่งส่วนอินสแตนซ์ของวัตถุ 3 มิติโดยฟิวชั่นคอนทราสต์แบบช้าเร็ว | Neurips '23 | คนอื่น ๆ |
| 2023-6-4 | มีคลิปหลายแบบ | ETH | หลายคลิป: การฝึกฝนภาษาวิสัยทัศน์แบบตัดกันสำหรับคำถามตอบคำถามในฉาก 3 มิติ | arxiv | - |
| 2023-5-23 | 3D-OVS | NTU | การแบ่งส่วนโอเพ่น | Neurips '23 | คนอื่น ๆ |
| 2023-5-21 | VL-fields | มหาวิทยาลัยเอดินเบิร์ก | VL-Fields: ไปสู่การเป็นตัวแทนเชิงพื้นที่ของระบบทางภาษา | ICRA '23 | โครงการ |
| 2023-5-8 | คลิป FO3D | มหาวิทยาลัย Tsinghua | Clip-FO3D: การเรียนรู้การเป็นตัวแทนฉาก 3D แบบเปิดฟรีจาก World World จากคลิปหนาแน่น 2D | iccvw '23 | - |
| 2023-4-12 | 3D-VQA | ETH | การฝึกฝนภาษาวิสัยทัศน์แบบคลิปพร้อมการฝึกอบรมสำหรับการตอบคำถามในฉาก 3 มิติ | cvprw '23 | คนอื่น ๆ |
| 2023-4-3 | ภูมิภาค | ฮูก | RegionPLC: การเรียนรู้แบบแตกต่างจากภาษาในระดับภูมิภาคสำหรับการทำความเข้าใจฉาก 3 มิติแบบเปิดโลก | arxiv | โครงการ |
| 2023-3-20 | CG3D | Jhu | Clip Goes 3D: ใช้ประโยชน์จากการปรับแต่งพร้อมสำหรับการรับรู้ภาษา 3 มิติ | arxiv | คนอื่น ๆ |
| 2023-3-16 | lerf | UC Berkeley | LERF: ฟิลด์ Radiance Language Language | ICCV '23 | คนอื่น ๆ |
| 2023-2-14 | แนวคิด | มิกซ์ | ConceptFusion: การทำแผนที่ 3D แบบหลายรูปแบบแบบ open-set | RSS '23 | โครงการ |
| 2023-1-12 | Clip2scene | ฮูก | Clip2scene: ไปสู่การทำความเข้าใจฉาก 3 มิติที่มีประสิทธิภาพฉลากโดยคลิป | cvpr '23 | คนอื่น ๆ |
| 2022-12-1 | หน่วย 3D | ทู | UNIT3D: หม้อแปลงแบบครบวงจรสำหรับคำบรรยายภาพหนาแน่น 3 มิติและการลงดิน | ICCV '23 | คนอื่น ๆ |
| 2022-11-29 | พลา | ฮูก | PLA: การทำความเข้าใจฉากแบบเปิดโล่งแบบเปิดโล่ง | cvpr '23 | คนอื่น ๆ |
| 2022-11-28 | การเปิดเครื่อง | ethz | OpenScene: การทำความเข้าใจฉาก 3 มิติด้วยคำศัพท์แบบเปิด | cvpr '23 | คนอื่น ๆ |
| 2022-10-11 | คลิปฟิลด์ | NYU | คลิปฟิลด์: สนามความหมายที่มีการดูแลอย่างอ่อนระบบสำหรับหน่วยความจำหุ่นยนต์ | arxiv | โครงการ |
| 2022-7-23 | นามธรรม | โคลัมเบีย | Semantic Abstraction: การทำความเข้าใจฉาก 3 มิติแบบเปิดโลกจากแบบจำลองภาษา 2D Vision-Language | Corl '22 | โครงการ |
| 2022-4-26 | Scannet200 | ทู | การแบ่งส่วนความหมาย 3D ในร่มที่มีพื้นดินในป่าในป่า | ECCV '22 | โครงการ |
| วันที่ | คำสำคัญ | สถาบัน (ครั้งแรก) | กระดาษ | สิ่งพิมพ์ | คนอื่น |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-CLR | ยูซีแอลเอ | การเรียนรู้แนวคิด 3 มิติและการใช้เหตุผลจากภาพหลายมุมมอง | cvpr '23 | คนอื่น ๆ |
| - | transcribe3d | TTI, ชิคาโก | transcribe3d: การลงดิน LLMS โดยใช้ข้อมูลที่ถอดความสำหรับการให้เหตุผลอ้างอิง 3 มิติด้วยการแก้ไขตัวเองที่แก้ไขด้วยตนเอง | Corl '23 | คนอื่น ๆ |
| วันที่ | คำสำคัญ | สถาบัน | กระดาษ | สิ่งพิมพ์ | คนอื่น |
|---|---|---|---|---|---|
| 2023-11-29 | ฉาบฉวย | มหาวิทยาลัย Fudan | shapegpt: การสร้างรูปร่าง 3 มิติที่มีรูปแบบภาษาแบบหลายโมดอลแบบครบวงจร | arxiv | คนอื่น ๆ |
| 2023-11-27 | meshgpt | ทู | MESHGPT: สร้างตาข่ายสามเหลี่ยมด้วยหม้อแปลงตัวถอดรหัสเท่านั้น | arxiv | โครงการ |
| 2023-10-19 | 3D-GPT | Anu | 3D-GPT: การสร้างแบบจำลอง 3D ขั้นตอนด้วยรูปแบบภาษาขนาดใหญ่ | arxiv | คนอื่น ๆ |
| 2023-9-21 | llmr | มิกซ์ | LLMR: การแจ้งเตือนแบบเรียลไทม์ของโลกแบบอินเทอร์แอคทีฟโดยใช้แบบจำลองภาษาขนาดใหญ่ | arxiv | - |
| 2023-9-20 | Dreamllm | megvii | Dreamllm: ความเข้าใจและการสร้างสรรค์หลายอย่างเสริมฤทธิ์กัน | arxiv | คนอื่น ๆ |
| 2023-4-1 | chatavatar | Deemos Tech | Dreamface: รุ่น 3 มิติที่มีความเคลื่อนไหวแบบก้าวหน้าภายใต้คำแนะนำข้อความ | ACM TOG | เว็บไซต์ |
| วันที่ | คำสำคัญ | สถาบัน | กระดาษ | สิ่งพิมพ์ | คนอื่น |
|---|---|---|---|---|---|
| 2024-01-22 | spatialvlm | ใจลึก | spatialvlm: การสิ้นสุดแบบจำลองภาษาวิสัยทัศน์ที่มีความสามารถในการใช้เหตุผลเชิงพื้นที่ | cvpr '24 | โครงการ |
| 2023-11-27 | dobb-e | NYU | เมื่อนำหุ่นยนต์กลับบ้าน | arxiv | คนอื่น ๆ |
| 2023-11-26 | สตีฟ | zju | ดูและคิด: ตัวแทนที่เป็นตัวเป็นตนในสภาพแวดล้อมเสมือนจริง | arxiv | คนอื่น ๆ |
| 2023-11-18 | สิงห์ | บิ๊ก | ตัวแทนทั่วไปที่เป็นตัวเป็นตนในโลก 3 มิติ | arxiv | คนอื่น ๆ |
| 2023-9-14 | unihsi | ห้องแล็บเซี่ยงไฮ้ | ปฏิสัมพันธ์ของมนุษย์แบบครบวงจรผ่านการติดต่อกับโซ่ของการติดต่อ | arxiv | คนอื่น ๆ |
| 2023-7-28 | RT-2 | Google-Deepmind | RT-2: โมเดลแอ็คชั่น Vision-Language ถ่ายโอนความรู้เว็บไปยังการควบคุมหุ่นยนต์ | arxiv | คนอื่น ๆ |
| 2023-7-12 | Sayplan | ศูนย์หุ่นยนต์ Qut | Sayplan: กราวด์แบบจำลองภาษาขนาดใหญ่โดยใช้กราฟฉาก 3 มิติสำหรับการวางแผนงานหุ่นยนต์ที่ปรับขนาดได้ | Corl '23 | คนอื่น ๆ |
| 2023-7-12 | Voxposer | สแตนฟอร์ด | VoxPoser: แผนที่ค่า 3 มิติแบบคอมโพสิตสำหรับการจัดการหุ่นยนต์ด้วยแบบจำลองภาษา | arxiv | คนอื่น ๆ |
| 2022-12-13 | RT-1 | RT-1: หม้อแปลงหุ่นยนต์สำหรับการควบคุมในโลกแห่งความเป็นจริงในระดับ | arxiv | คนอื่น ๆ | |
| 2022-12-8 | llm-planner | มหาวิทยาลัยรัฐโอไฮโอ | LLM-Planner: การวางแผนที่มีการยิงแบบไม่กี่ครั้งสำหรับตัวแทนที่เป็นตัวเป็นตนด้วยรูปแบบภาษาขนาดใหญ่ | ICCV '23 | คนอื่น ๆ |
| 2022-10-11 | คลิปฟิลด์ | NYU, META | คลิปฟิลด์: สนามความหมายที่มีการดูแลอย่างอ่อนระบบสำหรับหน่วยความจำหุ่นยนต์ | RSS '23 | คนอื่น ๆ |
| 2022-09-20 | nlmap-saycan | การเป็นตัวแทนฉากที่สามารถสอบถามได้สำหรับการวางแผนโลกแห่งความเป็นจริง | ICRA '23 | คนอื่น ๆ |
| วันที่ | คำสำคัญ | สถาบัน | กระดาษ | สิ่งพิมพ์ | คนอื่น |
|---|---|---|---|---|---|
| 2024-09-08 | msqa / msnn | บิ๊ก | การใช้เหตุผลหลายรูปแบบในฉาก 3 มิติ | Neurips '24 | โครงการ |
| 2024-06-10 | 3D-Grand / 3D-POPE | umich | 3D-Grand: ชุดข้อมูลล้านขนาดสำหรับ 3D-llms ที่มีสายดินที่ดีขึ้นและภาพหลอนน้อยลง | arxiv | โครงการ |
| 2024-06-03 | อวกาศ | UCSD | spatialrgpt: การใช้เหตุผลเชิงพื้นที่ในรูปแบบภาษาวิสัยทัศน์ | Neurips '24 | คนอื่น ๆ |
| 2024-1-18 | ฉาก | บิ๊ก | ScenEverse: การปรับขนาดการเรียนรู้ภาษาวิสัยทัศน์ 3 มิติสำหรับการทำความเข้าใจฉากที่มีพื้นฐาน | arxiv | คนอื่น ๆ |
| 2023-12-26 | embodiedscan | ห้องแล็บเซี่ยงไฮ้ | embodiedscan: ชุดรับรู้ 3 มิติแบบแบบองค์รวมแบบองค์รวมที่มีต่อ AI embodied AI | arxiv | คนอื่น ๆ |
| 2023-12-17 | M3dbench | มหาวิทยาลัย Fudan | M3DBENCH: ขอแนะนำรุ่นใหญ่ที่มีพรอมต์ 3D แบบหลายโมดอล | arxiv | คนอื่น ๆ |
| 2023-11-29 | - | ใจลึก | การประเมิน VLMS สำหรับคำอธิบายประกอบแบบอิงคะแนนหลายรายการของวัตถุ 3D | arxiv | คนอื่น ๆ |
| 2023-09-14 | การเชื่อมโยงกัน | unibo | ดูคำและจุดที่มีความสนใจ: มาตรฐานสำหรับการเชื่อมโยงแบบข้อความถึงรูปร่าง | ICCV '23 | คนอื่น ๆ |
| 2022-10-14 | SQA3D | บิ๊ก | SQA3D: การตอบคำถามที่ตั้งอยู่ในฉาก 3 มิติ | iclr '23 | คนอื่น ๆ |
| 2021-12-20 | Scanqa | riken aip | Scanqa: คำถาม 3 มิติตอบคำถามสำหรับการทำความเข้าใจฉากเชิงพื้นที่ | cvpr '23 | คนอื่น ๆ |
| 2020-12-3 | scan2cap | ทู | SCAN2CAP: คำบรรยายภาพหนาแน่นบริบทในการสแกน RGB-D | cvpr '21 | คนอื่น ๆ |
| 2020-8-23 | referit3d | สแตนฟอร์ด | referit3d: ผู้ฟังประสาทสำหรับการระบุวัตถุ 3 มิติที่ละเอียดในฉากจริง | ECCV '20 | คนอื่น ๆ |
| 2019-12-18 | การดูหมิ่น | ทู | Scanrefer: การแปลวัตถุ 3 มิติในการสแกน RGB-D โดยใช้ภาษาธรรมชาติ | ECCV '20 | คนอื่น ๆ |
การมีส่วนร่วมของคุณยินดีต้อนรับเสมอ!
ฉันจะเปิดคำขอดึงบางอย่างหากฉันไม่แน่ใจว่าพวกเขายอดเยี่ยมสำหรับ 3D LLMS คุณสามารถลงคะแนนให้พวกเขาได้โดยการเพิ่ม? กับพวกเขา
หากคุณมีคำถามใด ๆ เกี่ยวกับรายการที่มีความคิดเห็นนี้โปรดติดต่อได้ที่ [email protected] หรือ WeChat ID: MXZ1997112
หากคุณพบว่าที่เก็บนี้มีประโยชน์โปรดพิจารณาอ้างถึงบทความนี้:
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}repo นี้ได้รับแรงบันดาลใจจาก Awesome-llm


