BLIP-3-Video รุ่นภาษาหลายภาษาล่าสุดที่ออกโดยทีมวิจัย Salesforce AI มอบโซลูชันสำหรับการประมวลผลข้อมูลวิดีโอที่กำลังเติบโตอย่างมีประสิทธิภาพ โมเดลนี้มีจุดมุ่งหมายเพื่อปรับปรุงประสิทธิภาพและผลของการทำความเข้าใจวิดีโอ และมีการใช้กันอย่างแพร่หลายในด้านต่างๆ เช่น การขับขี่อัตโนมัติและความบันเทิง โดยนำนวัตกรรมมาสู่ทุกสาขาอาชีพ บรรณาธิการของ Downcodes จะอธิบายรายละเอียดเกี่ยวกับเทคโนโลยีหลักและประสิทธิภาพที่ยอดเยี่ยมของ BLIP-3-Video
เมื่อเร็วๆ นี้ ทีมวิจัย Salesforce AI ได้เปิดตัวโมเดลภาษาหลายรูปแบบใหม่ BLIP-3-Video ด้วยจำนวนเนื้อหาวิดีโอที่เพิ่มขึ้นอย่างรวดเร็ว วิธีการประมวลผลข้อมูลวิดีโออย่างมีประสิทธิภาพจึงกลายเป็นปัญหาเร่งด่วนที่ต้องแก้ไข การเกิดขึ้นของโมเดลนี้มีจุดมุ่งหมายเพื่อปรับปรุงประสิทธิภาพและประสิทธิผลของการทำความเข้าใจวิดีโอ และเหมาะสำหรับอุตสาหกรรมต่างๆ ตั้งแต่การขับขี่แบบอัตโนมัติไปจนถึงความบันเทิง
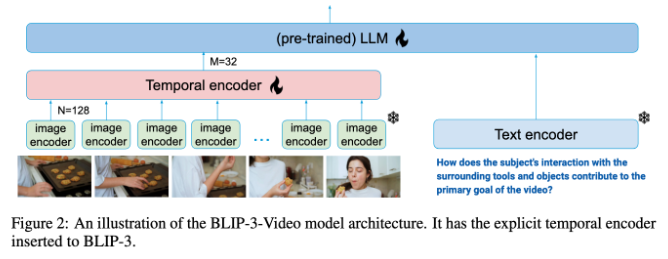
โมเดลการทำความเข้าใจวิดีโอแบบดั้งเดิมมักจะประมวลผลวิดีโอแบบเฟรมต่อเฟรมและสร้างข้อมูลภาพจำนวนมาก กระบวนการนี้ไม่เพียงแต่ใช้ทรัพยากรการประมวลผลจำนวนมากเท่านั้น แต่ยังจำกัดความสามารถในการประมวลผลวิดีโอขนาดยาวอีกด้วย เนื่องจากปริมาณข้อมูลวิดีโอยังคงเพิ่มขึ้น วิธีการนี้จึงไร้ประสิทธิภาพมากขึ้น ดังนั้นจึงจำเป็นอย่างยิ่งที่จะต้องค้นหาโซลูชันที่รวบรวมข้อมูลสำคัญของวิดีโอไปพร้อมๆ กับการช่วยลดภาระในการคำนวณ
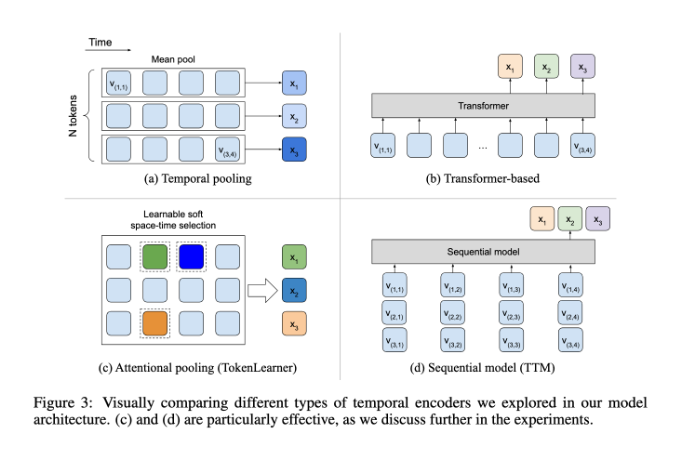
ในเรื่องนี้ BLIP-3-Video ทำงานได้ค่อนข้างดี โมเดลนี้สามารถลดปริมาณข้อมูลภาพที่ต้องการในวิดีโอลงเหลือ 16 ถึง 32 เครื่องหมายภาพได้สำเร็จโดยการแนะนำ "ตัวเข้ารหัสชั่วคราว" การออกแบบที่เป็นนวัตกรรมใหม่นี้ช่วยเพิ่มประสิทธิภาพในการคำนวณได้อย่างมาก ช่วยให้โมเดลสามารถทำงานวิดีโอที่ซับซ้อนได้สำเร็จด้วยต้นทุนที่ต่ำลง ตัวเข้ารหัสชั่วคราวนี้ใช้กลไกการรวมความสนใจ Spatiotemporal ที่เรียนรู้ได้ ซึ่งจะดึงข้อมูลที่สำคัญที่สุดจากแต่ละเฟรมและรวมเข้ากับชุดมาร์กเกอร์แบบมองเห็นขนาดกะทัดรัด
BLIP-3-Video 的表现也非常出色。 เมื่อเปรียบเทียบกับโมเดลขนาดใหญ่อื่นๆ การศึกษาพบว่าความแม่นยำของโมเดลนี้ในงานตอบคำถามผ่านวิดีโอนั้นเทียบได้กับโมเดลชั้นนำ ตัวอย่างเช่น รุ่น Tarsier-34B ต้องใช้มาร์กเกอร์ 4608 ตัวในการประมวลผลวิดีโอ 8 เฟรม ในขณะที่ BLIP-3-Video ต้องการเพียง 32 ตัวมาร์กเกอร์เพื่อให้ได้คะแนนเกณฑ์มาตรฐาน MSVD-QA ที่ 77.7% นี่แสดงให้เห็นว่า BLIP-3-Video ลดการใช้ทรัพยากรลงอย่างมากในขณะที่ยังคงรักษาประสิทธิภาพสูงไว้
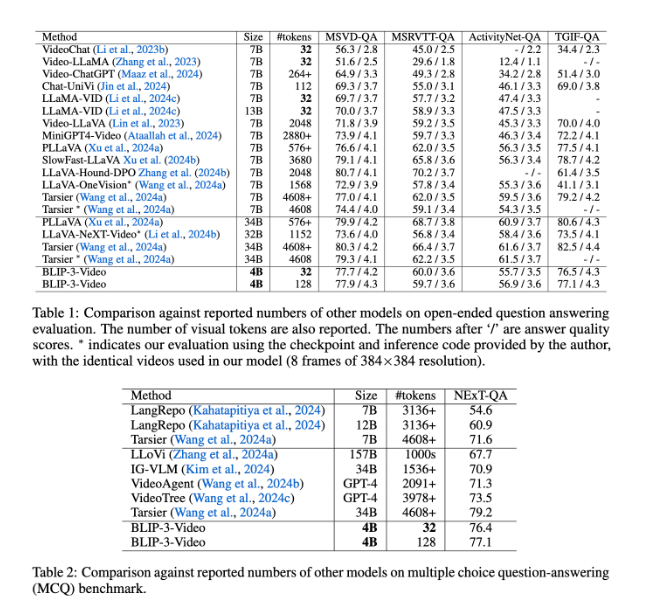
นอกจากนี้ ประสิทธิภาพของ BLIP-3-Video ในงานคำถามและคำตอบแบบปรนัยไม่สามารถประมาทได้ ในชุดข้อมูล NExT-QA แบบจำลองได้รับคะแนนสูงถึง 77.1% และในชุดข้อมูล TGIF-QA แบบจำลองยังได้คะแนนความแม่นยำถึง 77.1% อีกด้วย ข้อมูลเหล่านี้แสดงให้เห็นถึงประสิทธิภาพของ BLIP-3-Video ในการจัดการปัญหาวิดีโอที่ซับซ้อน

BLIP-3-Video เปิดโอกาสใหม่ในการประมวลผลวิดีโอด้วยตัวเข้ารหัสเวลาที่เป็นนวัตกรรมใหม่ การเปิดตัวโมเดลนี้ไม่เพียงแต่ปรับปรุงประสิทธิภาพของการทำความเข้าใจวิดีโอเท่านั้น แต่ยังช่วยเพิ่มความเป็นไปได้สำหรับแอปพลิเคชันวิดีโอในอนาคตอีกด้วย
ทางเข้าโครงการ: https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
BLIP-3-Video มอบทิศทางใหม่สำหรับการพัฒนาเทคโนโลยีวิดีโอในอนาคตด้วยความสามารถในการประมวลผลวิดีโอที่มีประสิทธิภาพ ประสิทธิภาพที่ยอดเยี่ยมในคำถามและคำตอบแบบวิดีโอและงานคำถามและคำตอบแบบปรนัย แสดงให้เห็นถึงศักยภาพอย่างมากในการประหยัดทรัพยากรและการปรับปรุงประสิทธิภาพ เราหวังเป็นอย่างยิ่งว่า BLIP-3-Video จะมีบทบาทในสาขาอื่น ๆ และส่งเสริมความก้าวหน้าของเทคโนโลยีวิดีโอ