บรรณาธิการของ Downcodes จะอธิบายให้คุณทราบถึงผลการวิจัยล่าสุดจาก Princeton University และ Yale University! งานวิจัยนี้สำรวจความสามารถในการให้เหตุผลของ "Chain of Thought (CoT)" อย่างลึกซึ้งของโมเดลภาษาขนาดใหญ่ (LLM) โดยเผยให้เห็นว่าการให้เหตุผลของ CoT ไม่ใช่การประยุกต์ใช้กฎเชิงตรรกะอย่างง่าย แต่เป็นการผสมผสานที่ซับซ้อนของปัจจัยหลายประการ เช่น หน่วยความจำ ความน่าจะเป็น และ การใช้เหตุผลทางเสียง นักวิจัยเลือกงานถอดรหัส shift cipher และดำเนินการวิเคราะห์เชิงลึกของ LLM สามตัว ได้แก่ GPT-4, Claude3 และ Llama3.1 ในที่สุด พวกเขาค้นพบปัจจัยสำคัญสามประการที่ส่งผลต่อผลการอนุมาน CoT และเสนอกลไกการอนุมานของ LLM ข้อมูลเชิงลึกใหม่
เมื่อเร็ว ๆ นี้ นักวิจัยจากมหาวิทยาลัยพรินซ์ตันและมหาวิทยาลัยเยลได้เผยแพร่รายงานเกี่ยวกับความสามารถในการให้เหตุผลแบบ "Chain of Thought (CoT)" ของโมเดลภาษาขนาดใหญ่ (LLM) ซึ่งเผยให้เห็นความลับของการให้เหตุผลแบบ CoT ซึ่งไม่ใช่การให้เหตุผลเชิงสัญลักษณ์โดยแท้ตามกฎเชิงตรรกะ แต่ โดยผสมผสานปัจจัยหลายประการ เช่น หน่วยความจำ ความน่าจะเป็น และการใช้เหตุผลทางเสียง
นักวิจัยใช้การแคร็กรหัสกะเป็นงานทดสอบและวิเคราะห์ประสิทธิภาพของ LLM สามตัว ได้แก่ GPT-4, Claude3 และ Llama3.1 Shift Cipher คือการเข้ารหัสอย่างง่าย โดยแต่ละตัวอักษรจะถูกแทนที่ด้วยตัวอักษรที่เลื่อนไปข้างหน้าตามจำนวนตำแหน่งคงที่ในตัวอักษร เช่น เลื่อนตัวอักษรไปข้างหน้า 3 ตำแหน่ง แล้ว CAT จะกลายเป็น FDW
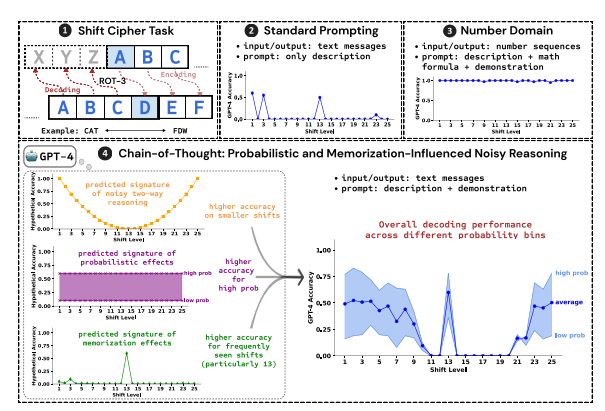
ผลการวิจัยแสดงให้เห็นว่าปัจจัยหลักสามประการที่ส่งผลต่อผลการใช้เหตุผลของ CoT คือ:
ความน่าจะเป็น: LLM ชอบที่จะสร้างผลลัพธ์ของความน่าจะเป็นที่สูงกว่า แม้ว่าขั้นตอนการอนุมานจะนำไปสู่คำตอบของความน่าจะเป็นที่ต่ำกว่าก็ตาม ตัวอย่างเช่น หากขั้นตอนการอนุมานชี้ไปที่ STAZ แต่ STAY เป็นคำทั่วไป LLM อาจ "แก้ไขตัวเอง" และส่งออก STAY
หน่วยความจำ: LLM จดจำข้อมูลข้อความจำนวนมากระหว่างการฝึกล่วงหน้า ซึ่งส่งผลต่อความแม่นยำของการอนุมาน CoT ตัวอย่างเช่น rot-13 เป็นรหัสกะที่ใช้บ่อยที่สุด และความแม่นยำของ LLM บน rot-13 นั้นสูงกว่ารหัสกะประเภทอื่นอย่างมาก
การอนุมานสัญญาณรบกวน: กระบวนการอนุมานของ LLM นั้นไม่ถูกต้องอย่างสมบูรณ์ แต่มีสัญญาณรบกวนในระดับหนึ่ง เมื่อจำนวนกะของรหัสกะเพิ่มขึ้น ขั้นตอนกลางที่จำเป็นสำหรับการถอดรหัสก็เพิ่มขึ้นเช่นกัน และผลกระทบของการอนุมานสัญญาณรบกวนจะชัดเจนมากขึ้น ทำให้ความแม่นยำของ LLM ลดลง
นักวิจัยยังพบว่าการใช้เหตุผล CoT ของ LLM ขึ้นอยู่กับการปรับสภาพตนเอง กล่าวคือ LLM จำเป็นต้องสร้างข้อความอย่างชัดเจนเป็นบริบทสำหรับขั้นตอนการให้เหตุผลในภายหลัง หาก LLM ได้รับคำสั่งให้ "คิดอย่างเงียบๆ" โดยไม่ต้องแสดงข้อความใดๆ ความสามารถในการให้เหตุผลจะลดลงอย่างมาก นอกจากนี้ ประสิทธิผลของขั้นตอนการสาธิตมีผลกระทบเพียงเล็กน้อยต่อการใช้เหตุผลของ CoT แม้ว่าจะมีข้อผิดพลาดในขั้นตอนการสาธิต แต่ผลการใช้เหตุผลของ CoT ของ LLM ยังคงมีเสถียรภาพ
การศึกษานี้แสดงให้เห็นว่าการใช้เหตุผล CoT ของ LLM ไม่ใช่การใช้เหตุผลเชิงสัญลักษณ์ที่สมบูรณ์แบบ แต่รวมเอาปัจจัยหลายประการ เช่น ความจำ ความน่าจะเป็น และการใช้เหตุผลทางเสียง LLM แสดงลักษณะของทั้งต้นแบบหน่วยความจำและต้นแบบความน่าจะเป็นในระหว่างกระบวนการให้เหตุผล CoT การวิจัยนี้ช่วยให้เราเข้าใจความสามารถในการให้เหตุผลของ LLM อย่างลึกซึ้งยิ่งขึ้น และให้ข้อมูลเชิงลึกที่มีคุณค่าสำหรับการพัฒนาระบบ AI ที่มีประสิทธิภาพมากขึ้นในอนาคต
ที่อยู่กระดาษ: https://arxiv.org/pdf/2407.01687
รายงานการวิจัยนี้ให้ข้อมูลอ้างอิงอันมีค่าสำหรับเราในการทำความเข้าใจกลไกการให้เหตุผล "ห่วงโซ่การคิด" ของแบบจำลองภาษาขนาดใหญ่ และยังให้ทิศทางใหม่สำหรับการออกแบบและการเพิ่มประสิทธิภาพระบบ AI ในอนาคต บรรณาธิการของ Downcodes จะยังคงให้ความสนใจกับการพัฒนาที่ล้ำหน้าในด้านปัญญาประดิษฐ์และนำเสนอเนื้อหาที่น่าตื่นเต้นมากขึ้นให้กับคุณ!