ทีม Emu3 ของ Zhiyuan Research Institute ได้เปิดตัวโมเดล Emu3 แบบหลายโมดัลที่ปฏิวัติวงการ ซึ่งล้มล้างสถาปัตยกรรมโมเดลหลายโมดัลแบบดั้งเดิม ฝึกฝนตามการคาดการณ์โทเค็นถัดไปเท่านั้น และบรรลุประสิทธิภาพของ SOTA ในงานสร้างและการรับรู้ ทีม Emu3 สร้างโทเค็นรูปภาพ ข้อความ และวิดีโอลงในพื้นที่แยกกันอย่างชาญฉลาด และฝึกฝนโมเดล Transformer เดี่ยวบนลำดับหลายโมดัลแบบผสม บรรลุการรวมงานหลายโมดัลเข้าด้วยกันโดยไม่ต้องอาศัยสถาปัตยกรรมการแพร่กระจายหรือการผสมผสาน ซึ่งให้ฟิลด์โมดัลที่หลากหลาย ความก้าวหน้าใหม่
ทีม Emu3 จากสถาบันวิจัย Zhiyuan ได้เปิดตัวโมเดล Emu3 หลายรูปแบบใหม่ โดยโมเดลนี้ได้รับการฝึกฝนโดยอิงตามการคาดการณ์โทเค็นถัดไปเท่านั้น โดยจะล้มล้างโมเดลการแพร่กระจายแบบดั้งเดิมและสถาปัตยกรรมโมเดลแบบผสมผสาน และบรรลุผลสำเร็จในทั้งสถานะการสร้างและการรับรู้ - ประสิทธิภาพแห่งศิลปะ
การทำนายโทเค็นครั้งต่อไปถือเป็นเส้นทางที่มีแนวโน้มไปสู่ปัญญาประดิษฐ์ทั่วไป (AGI) มานานแล้ว แต่ทำงานได้ไม่ดีในงานหลายรูปแบบ ในปัจจุบัน ฟิลด์มัลติโมดัลยังคงถูกครอบงำโดยแบบจำลองการแพร่กระจาย (เช่น การแพร่กระจายที่เสถียร) และแบบจำลองแบบผสมผสาน (เช่น การรวมกันของ CLIP และ LLM) ทีม Emu3 สร้างโทเค็นรูปภาพ ข้อความ และวิดีโอลงในพื้นที่แยกกัน และฝึกฝนโมเดล Transformer เดี่ยวตั้งแต่เริ่มต้นบนลำดับหลายโมดัลแบบผสม ดังนั้นจึงรวมงานหลายโมดัลเป็นหนึ่งเดียวโดยไม่ต้องอาศัยสถาปัตยกรรมการแพร่กระจายหรือการผสมผสาน
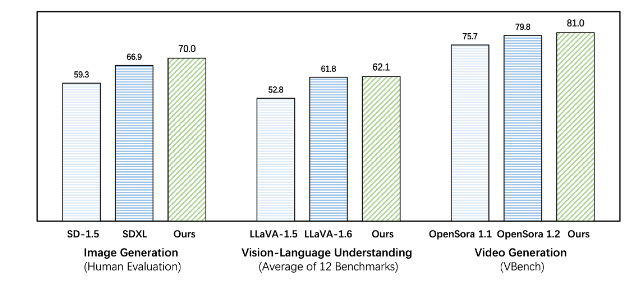
Emu3 มีประสิทธิภาพเหนือกว่าโมเดลเฉพาะงานที่มีอยู่ทั้งในด้านการสร้างและการรับรู้ แม้จะเหนือกว่ารุ่นเรือธงเช่น SDXL และ LLaVA-1.6 ก็ตาม Emu3 ยังสามารถสร้างวิดีโอที่มีความเที่ยงตรงสูงได้ด้วยการทำนายโทเค็นถัดไปในลำดับวิดีโอ ต่างจาก Sora ซึ่งใช้โมเดลการแพร่กระจายวิดีโอเพื่อสร้างวิดีโอจากสัญญาณรบกวน Emu3 สร้างวิดีโอในลักษณะเชิงสาเหตุโดยการทำนายโทเค็นถัดไปในลำดับวิดีโอ โมเดลนี้สามารถจำลองบางแง่มุมของสภาพแวดล้อม ผู้คน และสัตว์ในโลกแห่งความเป็นจริง และคาดการณ์ว่าจะเกิดอะไรขึ้นต่อไปตามบริบทของวิดีโอ
Emu3 ทำให้การออกแบบโมเดลหลายรูปแบบที่ซับซ้อนง่ายขึ้น และมุ่งเน้นไปที่โทเค็น ซึ่งปลดล็อกศักยภาพในการปรับขนาดขนาดใหญ่ในระหว่างการฝึกอบรมและการอนุมาน ผลการวิจัยแสดงให้เห็นว่าการทำนายโทเค็นถัดไปเป็นวิธีที่มีประสิทธิภาพในการสร้างความฉลาดหลายรูปแบบทั่วไปนอกเหนือจากภาษา เพื่อสนับสนุนการวิจัยเพิ่มเติมในด้านนี้ ทีมงาน Emu3 ได้ใช้เทคโนโลยีและโมเดลที่สำคัญแบบโอเพ่นซอร์ส รวมถึง tokenizer ภาพอันทรงพลังที่สามารถแปลงวิดีโอและรูปภาพให้เป็นโทเค็นแยกซึ่งไม่เคยเปิดเผยต่อสาธารณะมาก่อน
ความสำเร็จของ Emu3 ชี้ให้เห็นทิศทางสำหรับการพัฒนาโมเดลหลายรูปแบบในอนาคต และนำความหวังใหม่มาสู่การทำให้ AGI เป็นจริง
ที่อยู่โครงการ: https://github.com/baaivision/Emu3
โปรแกรมแก้ไข Downcodes สรุป: การเกิดขึ้นของโมเดล Emu3 ถือเป็นก้าวใหม่ในด้านมัลติโมดอล สถาปัตยกรรมที่เรียบง่ายและประสิทธิภาพอันทรงพลังให้แนวคิดและทิศทางใหม่สำหรับการวิจัย AGI ในอนาคต กลยุทธ์โอเพ่นซอร์สยังส่งเสริมการพัฒนาร่วมกันของภาควิชาการและอุตสาหกรรม เป็นสิ่งที่ควรค่าแก่การรอคอยที่จะค้นพบความก้าวหน้าเพิ่มเติมในอนาคต!