บรรณาธิการรายงาน Downcodes: วันนี้ทีมงานด้านเทคนิคของ Zhipu ได้เปิดตัวโมเดลการสร้างวิดีโอโอเพ่นซอร์ส CogVideoX v1.5 ที่สำคัญ ซึ่งถือเป็นการอัพเกรดครั้งใหญ่อีกครั้งหนึ่งของซีรีส์นี้นับตั้งแต่เดือนสิงหาคม เวอร์ชันใหม่ได้สร้างความก้าวหน้าครั้งสำคัญในด้านความสามารถในการสร้างวิดีโอ โดยรองรับวิดีโอที่ยาวขึ้น ความละเอียดที่สูงขึ้น และอัตราเฟรมที่นุ่มนวลขึ้น และเมื่อรวมกับโมเดลเอฟเฟกต์เสียง CogSound ที่เพิ่งเปิดตัวใหม่ เพื่อสร้างแพลตฟอร์ม "วิดีโอใหม่ที่ชัดเจน" เพื่อให้ผู้ใช้ได้รับวิดีโอระดับพรีเมียมที่ดียิ่งขึ้น ประสบการณ์การสร้างสรรค์ การอัปเดตนี้ไม่เพียงปรับปรุงคุณภาพวิดีโอเท่านั้น แต่ยังเพิ่มความสามารถของโมเดลในการเข้าใจความหมายที่ซับซ้อน ทำให้นักพัฒนามีเครื่องมือที่มีประสิทธิภาพมากขึ้น

เป็นที่เข้าใจกันว่าการอัปเดตนี้ได้ปรับปรุงความสามารถในการสร้างวิดีโออย่างมาก รวมถึงการรองรับความยาววิดีโอ 5 วินาทีและ 10 วินาที, ความละเอียด 768P และความสามารถในการสร้าง 16 เฟรม ในเวลาเดียวกัน โมเดล I2V (รูปภาพต่อวิดีโอ) ยังรองรับอัตราส่วนขนาดใดก็ได้ ซึ่งช่วยเพิ่มความสามารถในการเข้าใจความหมายที่ซับซ้อนยิ่งขึ้น
CogVideoX v1.5 มีสองรุ่นหลัก: CogVideoX v1.5-5B และ CogVideoX v1.5-5B-I2V ซึ่งได้รับการออกแบบมาเพื่อให้นักพัฒนามีเครื่องมือสร้างวิดีโอที่ทรงพลังยิ่งขึ้น
สิ่งที่น่าสังเกตยิ่งกว่านั้นคือ CogVideoX v1.5 จะเปิดตัวพร้อมกันบนแพลตฟอร์ม Qingying และรวมกับโมเดลเอฟเฟกต์เสียง CogSound ที่เพิ่งเปิดตัวใหม่จนกลายเป็น "New Qingying" New Qingying จะให้บริการพิเศษมากมาย รวมถึงการปรับปรุงคุณภาพวิดีโอ ประสิทธิภาพด้านสุนทรียภาพ และความสมเหตุสมผลของการเคลื่อนไหว และสนับสนุนการสร้างวิดีโอความละเอียดสูงพิเศษ 10 วินาที 4K 60 เฟรม
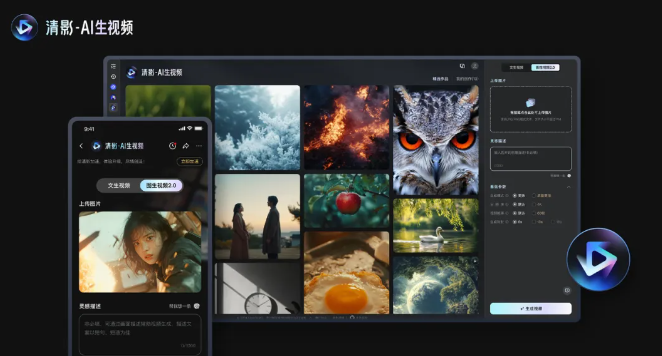
การแนะนำอย่างเป็นทางการมีดังนี้:
การปรับปรุงคุณภาพ: ความสามารถของวิดีโอ Tusheng ในด้านคุณภาพ ประสิทธิภาพด้านสุนทรียภาพ ความสมเหตุสมผลของการเคลื่อนไหว และความเข้าใจความหมายของคำพร้อมท์ที่ซับซ้อนได้รับการปรับปรุงอย่างมีนัยสำคัญ
ความละเอียด Ultra-HD: รองรับการสร้างวิดีโอความละเอียดสูงพิเศษ 10s, 4K และ 60 เฟรม
อัตราส่วนตัวแปร: รองรับอัตราส่วนใดๆ เพื่อปรับให้เข้ากับสถานการณ์การเล่นที่แตกต่างกัน
เอาต์พุตหลายช่องสัญญาณ: คำสั่ง/รูปภาพเดียวกันสามารถสร้างวิดีโอได้ 4 รายการในคราวเดียว
วิดีโอ AI พร้อมเอฟเฟกต์เสียง: Xinqingying สามารถสร้างเอฟเฟกต์เสียงที่เข้ากับภาพได้
ในแง่ของการประมวลผลข้อมูล ทีม CogVideoX มุ่งเน้นไปที่การปรับปรุงคุณภาพข้อมูล การพัฒนาเฟรมเวิร์กการกรองอัตโนมัติเพื่อกรองข้อมูลวิดีโอที่ไม่ดี และการเปิดตัวโมเดลการทำความเข้าใจวิดีโอแบบ end-to-end CogVLM2-caption เพื่อสร้างคำอธิบายเนื้อหาที่ถูกต้อง โมเดลนี้สามารถจัดการกับคำสั่งที่ซับซ้อนได้อย่างมีประสิทธิภาพ และรับประกันว่าวิดีโอที่สร้างขึ้นตรงกับความต้องการของผู้ใช้
เพื่อปรับปรุงการเชื่อมโยงเนื้อหา CogVideoX ใช้เทคโนโลยีการเข้ารหัสอัตโนมัติแบบแปรผันสามมิติ (3D VAE) ที่มีประสิทธิภาพ ซึ่งช่วยลดต้นทุนและความยากลำบากในการฝึกอบรมได้อย่างมาก นอกจากนี้ ทีมงานยังได้พัฒนาสถาปัตยกรรม Transformer ที่รวมข้อความ เวลา และพื้นที่สามมิติเข้าด้วยกัน ด้วยการลบโมดูลการสนใจข้ามแบบเดิมออกไป เอฟเฟกต์เชิงโต้ตอบของข้อความและวิดีโอก็ได้รับการปรับปรุง และคุณภาพของการสร้างวิดีโอก็ได้รับการปรับปรุงให้ดีขึ้น
ในอนาคต ทีมเทคนิคของ Zhipu จะยังคงขยายปริมาณข้อมูลและขนาดของโมเดลต่อไป และสำรวจสถาปัตยกรรมโมเดลที่มีประสิทธิภาพมากขึ้นเพื่อมอบประสบการณ์การสร้างวิดีโอที่ดียิ่งขึ้น โอเพ่นซอร์สของ CogVideoX v1.5 ไม่เพียงแต่มอบเครื่องมืออันทรงพลังให้กับนักพัฒนาเท่านั้น แต่ยังเพิ่มพลังใหม่ให้กับการสร้างสรรค์วิดีโออีกด้วย
รหัส: https://github.com/thudm/cogvideo
รุ่น : https://huggingface.co/THUDM/CogVideoX1.5-5B-SAT
ไฮไลท์:
CogVideoX v1.5 เวอร์ชันใหม่เป็นโอเพ่นซอร์สและรองรับวิดีโอ 5/10 วินาที ความละเอียด 768P และความสามารถในการสร้างเฟรม 16 เฟรม
เปิดตัวแพลตฟอร์ม Qingying ใหม่ ผสมผสานกับโมเดลเอฟเฟกต์เสียง CogSound เพื่อมอบการสร้างวิดีโอ 4K ที่มีความละเอียดสูงเป็นพิเศษ
การประมวลผลข้อมูลและนวัตกรรมอัลกอริทึมช่วยให้มั่นใจในคุณภาพและความสม่ำเสมอของวิดีโอที่สร้างขึ้น
โดยรวมแล้ว โอเพ่นซอร์สของ CogVideoX v1.5 และการเปิดตัวแพลตฟอร์ม Qingying ใหม่ ถือเป็นก้าวสำคัญในเทคโนโลยีการสร้างวิดีโอ AI โดยนำเครื่องมือที่ทรงพลังมากขึ้น และพื้นที่สร้างสรรค์ที่กว้างขึ้นมาสู่นักพัฒนาและนักสร้างสรรค์ เราหวังว่าจะได้เห็นแอปพลิเคชั่นที่น่าตื่นเต้นมากขึ้นซึ่งใช้ CogVideoX ในอนาคต