
[Related recommendations: JavaScript video tutorials, web front-end]
No matter what programming language you use, strings are an important data type. Follow me to learn more about JavaScript strings!
A string is a string composed of characters. If you have studied C and Java , you should know that the characters themselves can also become an independent type. However, JavaScript does not have a single character type, only strings of length 1 .
JavaScript strings use fixed UTF-16 encoding. No matter what encoding we use when writing the program, it will not be affected.
strings: single quotes, double quotes, and backticks.
let single = 'abcdefg';//Single quotes let double = "asdfghj";//Double quotes let backti = `zxcvbnm`;//Backticks
single and double quotes have the same status, we do not make a distinction.
String formatting
backticks allow us to elegantly format strings using ${...} instead of using string addition.
let str = `I'm ${Math.round(18.5)} years old.`;console.log(str); Code execution result:

Multi-line string
backticks also allow the string to span lines, which is very useful when we write multi-line strings.
let ques = `Is the author handsome? A. Very handsome; B. So handsome; C. Super handsome;`;console.log(ques);
Code execution results:
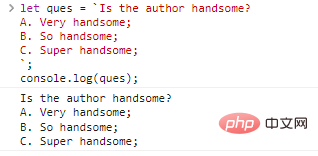
Doesn’t it look like there’s nothing wrong with it? But this cannot be achieved using single and double quotes. If you want to get the same result, you can write like this:
let ques = 'Is the author handsome?nA. Very handsome;nB. So handsome;nC. Super handsome;'; console.log(ques);
The above code contains a special character n , which is the most common special character in our programming process.
character n also known as "newline character", supports single and double quotes to output multi-line strings. When the engine outputs a string, if it encounters n , it will continue to output on another line, thereby realizing a multi-line string.
Although n appears to be two characters, it only occupies one character position. This is because is an escape character in the string, and the characters modified by the escape character become special characters.
Special character list
| Special character | description |
|---|---|
n | character, used to start a new line of output text. |
r | carriage return character moves the cursor to the beginning of the line. In Windows systems, rn is used to represent a line break, which means that the cursor needs to go to the beginning of the line first, and then to the next line before it can change to a new line. Other systems can use n directly. |
' " | Single and double quotation marks, mainly because single and double quotation marks are special characters. If we want to use single and double quotation marks in a string, we must escape them. |
\ | Backslash, also because |
b f v | backspace, page feed, vertical label - it is no longer used. |
xXX | is a hexadecimal Unicode character encoded as XX , for example: x7A means. z (The hexadecimal Unicode encoding of z is 7A ). |
uXXXX | is encoded as the hexadecimal Unicode character of XXXX , for example: u00A9 means © |
( 1-6 hexadecimal characters u{X...X} | |
| base characters) | UTF-32 encoding is the Unicode symbol of X...X . |
For example:
console.log('I'ma student.');// 'console.log(""I love U. "");// "console.log("\n is new line character.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// Code execution results:
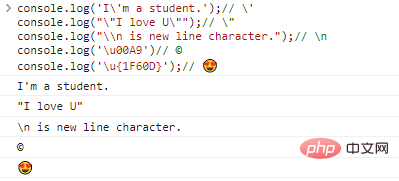
With the existence of the escape character , theoretically we can output any character, as long as we find its corresponding encoding.
Avoid using ' and "
for single and double quotes in strings. We can cleverly use double quotes within single quotes, use single quotes within double quotes, or directly use single and double quotes within backticks. Avoid using escape characters, for example:
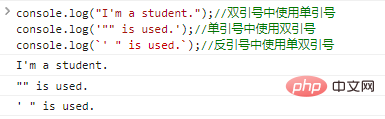
console.log("I'm a student.");
//Use single quotes within double quotes console.log('"" is used.');
//Use double quotes within single quotes console.log(`' " is used.`);
//The code execution results using single and double quotes in backticks are as follows:
Through the .length property of the string, we can get the length of the string:
console.log("HelloWorldn".length);//11 n here only occupies one character.
In the "Methods of Basic Types" chapter, we explored why basic types in
JavaScripthave properties and methods. Do you still remember?
string is a string of characters. We can access a single character through [字符下标] . The character subscript starts from 0 :
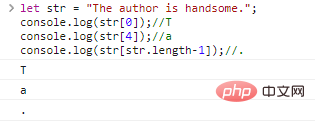
let str = "The author is handsome."; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//.
Code execution results:
We can also use the charAt(post) function to obtain characters:
let str = "The author is handsome.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.The
execution effect of the two is exactly the same, the only difference is when accessing characters out of bounds:
let str = "01234";console.log(str[ 9]);//undefinedconsole.log(str.charAt(9));//"" (empty string)
We can also use for ..of to traverse the string:
for(let c of '01234'){
console.log(c);} A string in JavaScript cannot be changed once it is defined. For example:
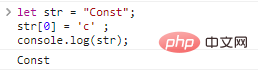
let str = "Const";str[0] = 'c' ;console.log(str);
Code execution results:
If you want to get a different string, you can only create a new one:
let str = "Const";str = str.replace('C','c');console.log(str); It seems that we have changed the characters String, in fact the original string has not been changed, what we get is the new string returned by the replace method.
converts the case of a string, or converts the case of a single character in a string.
The methods for these two strings are relatively simple, as shown in the example:
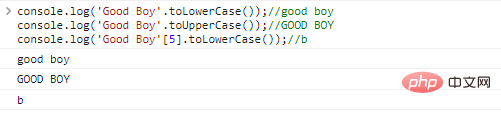
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Good Boy'.toUpperCase());//GOOD
BOYconsole.log('Good Boy'[5].toLowerCase());//b code execution results:
The .indexOf(substr,idx) function starts from the idx position of the string, searches for the position of the substring substr , and returns the subscript of the first character of the substring if successful, or -1 if failed.
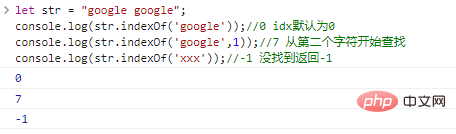
let str = "google google";console.log(str.indexOf('google'));
//0 idx defaults to 0console.log(str.indexOf('google',1));
//7 Search console.log(str.indexOf('xxx')); starting from the second character.
//-1 not found returns -1 code execution result:
If we want to query the positions of all substrings in the string, we can use a loop:
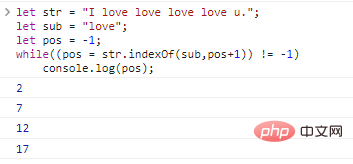
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf (sub,pos+1)) != -1)
console.log(pos); The code execution results are as follows:
.lastIndexOf(substr,idx) searches for substrings backwards, first finding the last matching string:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx defaults to 0 because indexOf() and lastIndexOf() methods will return -1 when the query is unsuccessful, and ~-1 === 0 . That is to say, using ~ is only true when the query result is not -1 , so we can:
let str = "google google";if(~indexOf('google',str)){
...} Normally, we do not recommend using a syntax where the syntax characteristics cannot be clearly reflected, as this will have an impact on readability. Fortunately, the above code only appears in the old version of the code. It is mentioned here so that everyone will not be confused when reading the old code.
Supplement:
~is the bitwise negation operator. For example: the binary form of the decimal number2is0010, and the binary form of~2is1101(complement), which is-3.A simple way of understanding,
~nis equivalent to-(n+1), for example:~2 === -(2+1) === -3
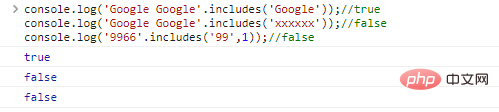
.includes(substr,idx) is used to determine whether substr is in the string. idx is the starting position of the query
console.log('Google Google'.includes('Google'));//trueconsole.log('Google Google'. includes('xxxxxx'));//falseconsole.log('9966'.includes('99',1));//false code execution results:
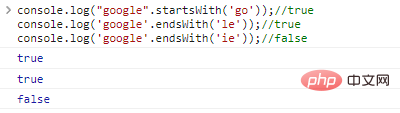
.startsWith('substr') and .endsWith('substr') respectively determine whether the string starts or ends with substr
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));//false code execution result:
.substr() , .substring() , .slice() are all used to get substrings of strings, but their usage is different.
.substr(start,len)
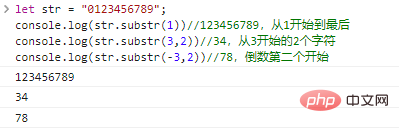
returns a string consisting of len characters starting from start . If len is omitted, it will be intercepted to the end of the original string. start can be a negative number, indicating the start character from the back to the front.
let str = "0123456789";console.log(str.substr(1))//123456789, starting from 1 to the end console.log(str.substr(3,2))//34, 2 starting from 3 Character console.log(str.substr(-3,2))//78, the penultimate start
code execution result:
.slice(start,end)
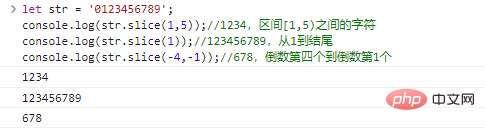
returns the string starting from start and ending at end (exclusive). start and end can be negative numbers, indicating the penultimate start/end characters.
let str = '0123456789';console.log(str.slice(1,5));//1234, characters between the interval [1,5) console.log(str.slice(1));//123456789 , from 1 to the end console.log(str.slice(-4,-1));//678, the fourth to last
code execution results:
.substring(start,end)
is almost the same as .slice() . The difference is in two places:
end > start is allowed;0 ;for example:
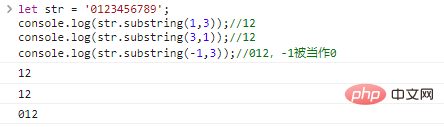
let str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1,3));//012, -1 is treated as Make 0
code execution result:
Compare the differences between the three:
| method | description | parameters.slice |
|---|---|---|
.slice(start,end) | [start,end) | can be negative.substring |
.substring(start,end) | [start,end) | The negative value 0 |
.substr(start,len) | starts from start |
| negative | len |
methods for len, so it is naturally difficult to choose. It is recommended to remember
.slice(), which is more flexible than the other two.
We have already mentioned the comparison of strings in the previous article. Strings are sorted in dictionary order. Behind each character is a code, and ASCII code is an important reference.
For example:
console.log('a'>'Z');// Comparison between true characters is essentially a comparison between encodings representing characters. JavaScript uses UTF-16 to encode strings. Each character is a 16 bit code. If you want to know the nature of the comparison, you need to use .codePointAt(idx) to get the character encoding:
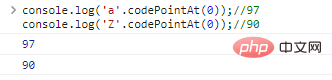
console.log('a'.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 code execution results:
Use String.fromCodePoint(code) to convert the encoding into characters:
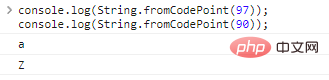
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
The code execution results are as follows:
This process can be achieved using the escape character u , as follows:
console.log('u005a');//Z, 005a is the hexadecimal notation of 90 console.log('u0061');//a, 0061 It is the hexadecimal notation of 97. Let’s explore the characters encoded in the range [65,220] :
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); The results of the code execution part are as follows:

The picture above does not show all the results, so go and try it.
is based on the international standard ECMA-402 . JavaScript has implemented a special method ( .localeCompare() ) to compare various strings, using str1.localeCompare(str2) :
str1 < str2 , return a negative number;str1 > str2 , return a positive number;str1 == str2 , return 0;for example:
console.log("abc".localeCompare('def'));//-1 Why not use comparison operators directly? ?
This is because English characters have some special ways of writing. For example, á is a variant of a :
console.log('á' < 'z');// Although false is also a , it is larger than z ! !
At this time, you need to use .localeCompare() method:
console.log('á'.localeCompare('z'));//-1 str.trim() removes whitespace characters before and after the string, str.trimStart() , str.trimEnd() deletes the spaces at the beginning and end;
let str = " 999 "; console.log(str.trim()); //999
str.repeat(n) repeats the string n times;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) replaces the first substring, str.replaceAll() is used to replace all substrings;
let str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6'));//6+6is still There are many other methods and we can visit the manual for more knowledge.
JavaScript uses UTF-16 to encode strings, that is, two bytes ( 16 bits) are used to represent one character. However, 16 bit data can only represent 65536 characters, so common characters are naturally not included. It's easy to understand, but it's not enough for rare characters (Chinese), emoji , rare mathematical symbols, etc.
In this case, you need to expand and use longer digits ( 32 bits) to represent special characters, for example:
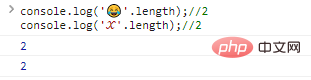
console.log(''.length);//2console.log('?'.length);//2 code Execution result:
The result of this is that we can't process them using conventional methods. What happens if we output each byte individually?
console.log(''[0]);console.log(''[1]); Code execution results:
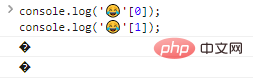
As you can see, individual output bytes are not recognized.
Fortunately, String.fromCodePoint() and .codePointAt() methods can handle this situation because they were added recently. In older versions of JavaScript , you can only use String.fromCharCode() and .charCodeAt() methods to convert encodings and characters, but they are not suitable for special characters.
We can deal with special characters by judging the encoding range of a character to determine whether it is a special character. If the code of a character is between 0xd800~0xdbff , then it is the first part of the 32 bit character, and its second part should be between 0xdc00~0xdfff .
For example:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02 code execution result:

In English, there are many letter-based variants, for example: the letter a can be the basic character of àáâäãåā . Not all of these variant symbols are stored in UTF-16 encoding because there are too many combinations of variations.
In order to support all variant combinations, multiple Unicode characters are also used to represent a single variant character. During the programming process, we can use basic characters plus "decorative symbols" to express special characters:
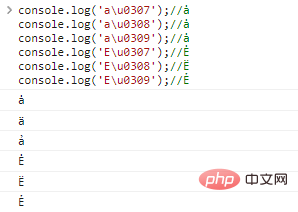
console.log('au0307 ');//ȧ
console.log('au0308');//ȧ
console.log('au0309');//ȧ
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');//ẺCode execution results:
A basic letter can also have multiple decorations, for example:
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');//Ẹ̇Code execution results:
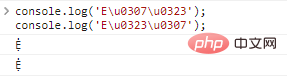
There is a problem here. In the case of multiple decorations, the decorations are ordered differently, but the characters actually displayed are the same.
If we compare these two representations directly, we get the wrong result:
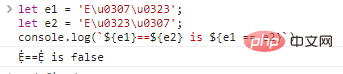
let e1 = 'Eu0307u0323';
let e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`) code execution results:
In order to solve this situation, there is a ** Unicode normalization algorithm that can convert the string into a universal ** format, implemented by str.normalize() :
let e1 = 'Eu0307u0323';
let e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} is ${e1.normalize() == e2.normalize()}`)
Code execution results:

[Related recommendations: JavaScript video tutorials, web front-end]
The above is the detailed content of the common basic methods of JavaScript strings. For more information, please pay attention to other related articles on the PHP Chinese website!