
Before studying the content of this article, we must first understand the concept of asynchronous. The first thing to emphasize is that there is an essential difference between asynchronous and parallel .
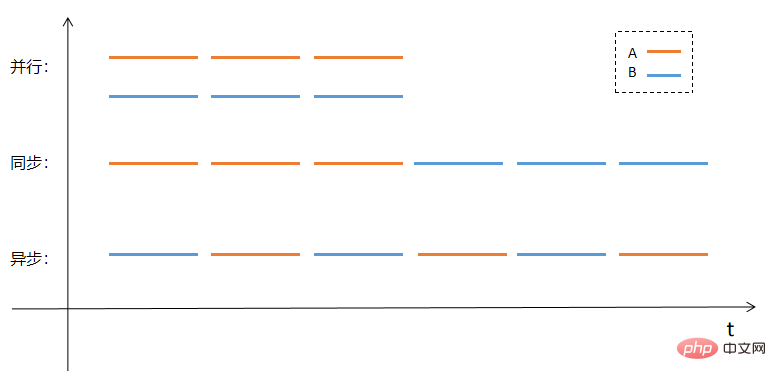
Parallelism generally refers to parallel computing, which means that multiple instructions are executed at the same time. These instructions may be executed on multiple cores of the same CPU , or on multiple CPU , or on multiple physical hosts or even multiple networks.
Synchronization generally refers to executing tasks in a predetermined order. Only when the previous task is completed, the next task will be executed.
Asynchronous, corresponding to synchronization, means that CPU temporarily puts aside the current task, processes the next task first, and then returns to the previous task to continue execution after receiving the callback notification of the previous task. The entire process does not require a second thread. participate .
Perhaps it is more intuitive to explain parallelism, synchronization and asynchronousness in the form of pictures. Assume that there are two tasks A and B that need to be processed. The parallel, synchronous and asynchronous processing methods will adopt the execution methods as shown in the following figure:
JavaScript provides us with many asynchronous functions. These functions allow us to conveniently execute asynchronous tasks. That is to say, we start executing a task (function) now, but the task will be completed later, and the specific completion time is not Not sure.
For example, the setTimeout function is a very typical asynchronous function. In addition, fs.readFile and fs.writeFile are also asynchronous functions.
We can define an asynchronous task case ourselves, such as customizing a file copy function copyFile(from,to) :
const fs = require('fs')function copyFile(from, to) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
})
})} The function copyFile first reads the file data from the parameter from , and then writes the data to the file pointed to by the parameter to .
We can call copyFile like this:
copyFile('./from.txt','./to.txt')//Copy the file If there is other code after copyFile(...) at this time, the program will not wait The execution of copyFile ends, but it executes directly downward. The program does not care when the file copy task ends.
copyFile('./from.txt','./to.txt')//The following code will not wait for the execution of the above code to end... At this point, everything seems to be normal, but if we What happens if you directly access the contents of the file ./to.txt after the copyFile(...) function?
This will not read the copied content, just like this:
copyFile('./from.txt','./to.txt')fs.readFile('./to.txt',(err,data)= >{
...}) If the ./to.txt file has not been created before executing the program, you will get the following error:
PS E:CodeNodedemos�3-callback> node .index.js finished Copy finished PS E:CodeNodedemos�3-callback> node .index.js Error: ENOENT: no such file or directory, open 'E:CodeNodedemos�3-callbackto.txt'Copy finished
Even if ./to.txt exists, the copied content cannot be read.
The reason for this phenomenon is: copyFile(...) is executed asynchronously. After the program executes copyFile(...) function, it does not wait for the copy to be completed, but executes it directly downwards, causing the file to appear. ./to.txt does not exist error, or the file content is empty error (if the file is created in advance).
The specific execution end time of the callback function asynchronous function cannot be determined. For example, the execution end time of readFile(from,to) function most likely depends on the size of the file from .
So, the question is how can we accurately locate the end of copyFile execution and read the contents of the to file?
This requires the use of a callback function. We can modify the copyFile function as follows:
function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
callback()//Callback function is called when the copy operation is completed})
})} In this way, if we need to perform some operations immediately after the file copy is completed, we can write these operations into the callback function:
function copyFile(from, to, callback) {
fs.readFile(from, (err, data) => {
if (err) {
console.log(err.message)
return
}
fs.writeFile(to, data, (err) => {
if (err) {
console.log(err.message)
return
}
console.log('Copy finished')
callback()//Callback function is called when the copy operation is completed})
})}copyFile('./from.txt', './to.txt', function () {
//Pass in a callback function, read the contents of the "to.txt" file and output fs.readFile('./to.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log(data.toString())
})}) If you have prepared the ./from.txt file, then the above code can be run directly:
PS E:CodeNodedemos�3-callback> node .index.js Copy finished Join the community "Xianzong" and cultivate immortality with me. Community address: http://t.csdn.cn/EKf1h
This programming method is called a "callback-based" asynchronous programming style. Asynchronously executed functions should provide a callback Parameters are used to call after the task ends.
This style is common in JavaScript programming. For example, the file reading functions fs.readFile and fs.writeFile are all asynchronous functions.
The callback function can accurately handle subsequent matters after the asynchronous work is completed. If we need to perform multiple asynchronous operations in sequence, we need to nest the callback function.
Case scenario:
Code implementation for reading file A and file B in sequence:
fs.readFile('./A.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log('Read file A: ' + data.toString())
fs.readFile('./B.txt', (err, data) => {
if (err) {
console.log(err.message)
return
}
console.log("Read file B: " + data.toString())
})}) Execution effect:
PS E:CodeNodedemos�3-callback> node .index.js Reading file A: Immortal Sect is infinitely good, but it’s missing someone. Reading file B: If you want to join Immortal Sect, you must have the link http://t.csdn.cn/H1faI.
Through callback, you can read the file. After A, file B is read immediately.
What if we want to continue reading file C after file B? This requires continuing to nest callbacks:
fs.readFile('./A.txt', (err, data) => {//First callback if (err) {
console.log(err.message)
return
}
console.log('Read file A: ' + data.toString())
fs.readFile('./B.txt', (err, data) => {//Second callback if (err) {
console.log(err.message)
return
}
console.log("Read file B: " + data.toString())
fs.readFile('./C.txt',(err,data)=>{//The third callback...
})
})}) In other words, if we want to perform multiple asynchronous operations in sequence, we need multiple levels of nested callbacks. This is effective when the number of levels is small, but when there are too many nesting times, some problems will occur. question.
Callback Conventions
In fact, the style of callback functions in fs.readFile is not an exception, but a common convention in JavaScript . We will customize a large number of callback functions in the future, and we need to abide by this convention and form good coding habits.
The convention is:
callback is reserved for error. Once an error occurs, callback(err) will be called.callback(null, result1, result2,...) will be called.Based on the above convention, a callback function has two functions: error handling and result reception. For example, the callback function of fs.readFile('...',(err,data)=>{}) follows this convention.
If we don’t delve deeper, asynchronous method processing based on callbacks seems to be a pretty perfect way to handle it. The problem is that if we have one asynchronous behavior after another, the code will look like this:
fs.readFile('./a.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//Read result operation fs.readFile('./b.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//Read result operation fs.readFile('./c.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
//Read result operation fs.readFile('./d.txt',(err,data)=>{
if(err){
console.log(err.message)
return
}
...
})
})
})}) The execution content of the above code is:
As the number of calls increases, the code nesting level becomes deeper and deeper, including more and more conditional statements, resulting in confusing code that is constantly indented to the right, making it difficult to read and maintain.
We call this phenomenon of continuous growth to the right (indentation to the right) " callback hell " or " pyramid of doom "!
fs.readFile('a.txt',(err,data)=>{
fs.readFile('b.txt',(err,data)=>{
fs.readFile('c.txt',(err,data)=>{
fs.readFile('d.txt',(err,data)=>{
fs.readFile('e.txt',(err,data)=>{
fs.readFile('f.txt',(err,data)=>{
fs.readFile('g.txt',(err,data)=>{
fs.readFile('h.txt',(err,data)=>{
...
/*
Gate to Hell ===>
*/
})
})
})
})
})
})
})}) Although the above code looks quite regular, it is just an ideal situation for example. Usually there are a large number of conditional statements, data processing operations and other codes in the business logic, which disrupts the current beautiful order and makes the code change. difficult to maintain.
Fortunately, JavaScript provides us with multiple solutions, and Promise is the best solution.