
How to understand and master the essence of virtual DOM? I recommend everyone to learn the Snabbdom project.
Snabbdom is a virtual DOM implementation library. The reasons for recommendation are: first, the code is relatively small, and the core code is only a few hundred lines; second, Vue draws on the ideas of this project to implement virtual DOM; third, the design/implementation and expansion ideas of this project Worth your reference.
snabb /snab/, Swedish, means fast.
Adjust your comfortable sitting posture and cheer up. Let's get started. To learn virtual DOM, we must first know the basic knowledge of DOM and the pain points of directly operating DOM with JS.
DOM (Document Object Model) is a document object model that uses an object tree structure to represent an HTML/XML document. The end of each branch of the tree is a node. Nodes contain objects. The methods of the DOM API allow you to manipulate this tree in specific ways. With these methods, you can change the structure, style, or content of the document.
All nodes in the DOM tree are first Node , Node is a base class. Element , Text and Comment all inherit from it.
In other words, Element , Text and Comment are three special Node , which are called ELEMENT_NODE respectively.
TEXT_NODE and COMMENT_NODE represent element nodes (HTML tags), text nodes and comment nodes. Element also has a subclass called HTMLElement . What is the difference between HTMLElement and Element ? HTMLElement represents elements in HTML, such as: <span> , <img> , etc., and some elements are not HTML standard, such as <svg> . You can use the following method to determine whether this element is HTMLElement :
document.getElementById('myIMG') instanceof HTMLElement; It is "expensive" for the browser to create the DOM. Let's take a classic example. We can create a simple p element through document.createElement('p') and print out all the attributes:

You can see that there are a lot of printed attributes. When updating complex DOM trees frequently, performance problems will occur. Virtual DOM uses a native JS object to describe a DOM node, so creating a JS object is much less expensive than creating a DOM object.
VNode is an object structure describing the virtual DOM in Snabbdom. The content is as follows:
type Key = string | number | symbol;
interface VNode {
// CSS selector, such as: 'p#container'.
sel: string | undefined;
// Manipulate CSS classes, attributes, etc. through modules.
data: VNodeData | undefined;
// Virtual child node array, array elements can also be strings.
children: Array<VNode | string> | undefined;
// Point to the real DOM object created.
elm: Node | undefined;
/**
* There are two situations for the text attribute:
* 1. The sel selector is not set, indicating that the node itself is a text node.
* 2. sel is set, indicating that the content of this node is a text node.
*/
text: string | undefined;
// Used to provide an identifier for the existing DOM, which must be unique among sibling elements to effectively avoid unnecessary reconstruction operations.
key: Key | undefined;
}
// Some settings on vnode.data, class or life cycle function hooks, etc.
interface VNodeData {
props?: Props;
attrs?: Attrs;
class?: Classes;
style?: VNodeStyle;
dataset?: Dataset;
on?: On;
attachData?: AttachData;
hook?: Hooks;
key?: Key;
ns?: string; // for SVGs
fn?: () => VNode; // for thunks
args?: any[]; // for thunks
is?: string; // for custom elements v1
[key: string]: any; // for any other 3rd party module
} For example, define a vnode object like this:
const vnode = h(
'p#container',
{ class: { active: true } },
[
h('span', { style: { fontWeight: 'bold' } }, 'This is bold'),
' and this is just normal text'
]); We create vnode objects through the h(sel, b, c) function. The h() code implementation mainly determines whether the b and c parameters exist, and processes them into data and children. Children will eventually be in the form of an array. Finally, the VNode type format defined above is returned through the vnode() function.
First let’s take a simple example diagram of the running process, and first have a general process concept:

Diff processing is the process used to calculate the difference between new and old nodes.
Let’s look at a sample code run by Snabbdom:
import {
init,
classModule,
propsModule,
styleModule,
eventListenersModule,
h,
} from 'snabbdom';
const patch = init([
// Initialize the patch function classModule by passing in the module, // Enable the classes function propsModule, // Support passing in props
styleModule, // Supports inline styles and animation eventListenersModule, // Adds event listening]);
// <p id="container"></p>
const container = document.getElementById('container');
const vnode = h(
'p#container.two.classes',
{ on: { click: someFn } },
[
h('span', { style: { fontWeight: 'bold' } }, 'This is bold'),
' and this is just normal text',
h('a', { props: { href: '/foo' } }, "I'll take you places!"),
]
);
// Pass in an empty element node.
patch(container, vnode);
const newVnode = h(
'p#container.two.classes',
{ on: { click: anotherEventHandler } },
[
h(
'span',
{ style: { fontWeight: 'normal', fontStyle: 'italic' } },
'This is now italic type'
),
' and this is still just normal text',
h('a', { props: { href: ''/bar' } }, "I'll take you places!"),
]
);
// Call patch() again to update the old node to the new node.
patch(vnode, newVnode); As can be seen from the process diagram and sample code, the running process of Snabbdom is described as follows:
first call init() for initialization, and the modules to be used need to be configured during initialization. For example, classModule module is used to configure the class attribute of elements in the form of objects; the eventListenersModule module is used to configure event listeners, etc. The patch() function will be returned after init() is called.
Create the initialized vnode object through the h() function, call the patch() function to update it, and finally create the real DOM object through createElm() .
When an update is required, create a new vnode object, call patch() function to update, and complete the differential update of this node and child nodes through patchVnode() and updateChildren() .
Snabbdom uses module design to extend the update of related properties instead of writing it all into the core code. So how is this designed and implemented? Next, let’s first come to the core content of Kangkang’s design, Hooks—life cycle functions.
Snabbdom provides a series of rich life cycle functions, also known as hook functions. These life cycle functions are applicable in modules or can be defined directly on vnode. For example, we can define hook execution on vnode like this:
h('p.row', {
key: 'myRow',
hook: {
insert: (vnode) => {
console.log(vnode.elm.offsetHeight);
},
},
}); All life cycle functions are declared as follows:
| name | trigger node | callback parameters |
|---|---|---|
pre | patch start execution | none |
init | vnode is added | vnode |
create | a DOM element based on vnode is created | emptyVnode, vnode |
insert | element is inserted into the DOM | vnode |
prepatch | element is about to patch | oldVnode, vnode |
update | element has been updated | oldVnode, vnode |
postpatch | element has been patched | oldVnode, vnode |
destroy | element has been removed directly or indirectly | vnode |
remove | element has removed vnode from the DOM | vnode, removeCallback |
post | has completed the patch process | none |
which applies to the module : pre , create , update , destroy , remove , post . Applicable to vnode declarations are: init , create , insert , prepatch , update , postpatch , destroy , remove .
Let's look at how Kangkang is implemented. For example, let's take classModule module as an example. Kangkang's statement:
import { VNode, VNodeData } from "../vnode";
import { Module } from "./module";
export type Classes = Record<string, boolean>;
function updateClass(oldVnode: VNode, vnode: VNode): void {
// Here are the details of updating the class attribute, ignore it for now.
// ...
}
export const classModule: Module = { create: updateClass, update: updateClass }; You can see that the last exported module definition is an object. The key of the object is the name of the hook function. The definition of the module object Module is as follows:
import {
PreHook,
CreateHook,
UpdateHook,
DestroyHook,
RemoveHook,
PostHook,
} from "../hooks";
export type Module = Partial<{
pre: PreHook;
create: CreateHook;
update: UpdateHook;
destroy: DestroyHook;
remove: RemoveHook;
post: PostHook;
}>; Partial in TS means that the attributes of each key in the object can be empty. That is to say, just define which hook you care about in the module definition. Now that the hook is defined, how is it executed in the process? Next let's look at the init() function:
// What are the hooks that may be defined in the module.
const hooks: Array<keyof Module> = [
"create",
"update",
"remove",
"destroy",
"pre",
"post",
];
export function init(
modules: Array<Partial<Module>>,
domApi?: DOMAPI,
options?: Options
) {
//The hook function defined in the module will finally be stored here.
const cbs: ModuleHooks = {
create: [],
update: [],
remove: [],
destroy: [],
pre: [],
post: [],
};
// ...
// Traverse the hooks defined in the module and store them together.
for (const hook of hooks) {
for (const module of modules) {
const currentHook = module[hook];
if (currentHook !== undefined) {
(cbs[hook] as any[]).push(currentHook);
}
}
}
// ...
} You can see that init() first traverses each module during execution, and then stores the hook function in the cbs object. When executing, you can use patch() function:
export function init(
modules: Array<Partial<Module>>,
domApi?: DOMAPI,
options?: Options
) {
// ...
return function patch(
oldVnode: VNode | Element | DocumentFragment,
vnode: VNode
): VNode {
// ...
// patch starts, execute pre hook.
for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]();
// ...
}
} Here we take the pre hook as an example. The execution time of the pre hook is when the patch starts executing. You can see that patch() function cyclically calls the pre related hooks stored in cbs at the beginning of execution. The calls to other life cycle functions are similar to this. You can see the corresponding life cycle function calls elsewhere in the source code.
The design idea here is the observer pattern . Snabbdom implements non-core functions by distributing them in modules. Combined with the definition of life cycle, the module can define the hooks it is interested in. Then when init() is executed, it is processed into cbs objects to register these hooks; when the execution time comes, call These hooks are used to notify module processing. This separates the core code and module code. From here we can see that the observer pattern is a common pattern for code decoupling.
Next we come to the Kangkang core function patch() . This function is returned after the init() call. Its function is to mount and update the VNode. The signature is as follows:
function patch(oldVnode: VNode | Element | DocumentFragment , vnode: VNode): VNode {
// For the sake of simplicity, don't pay attention to DocumentFragment.
// ...
} The oldVnode parameter is the old VNode or DOM element or document fragment, and the vnode parameter is the updated object. Here I directly post a description of the process:
calling the pre hook registered on the module.
If oldVnode is Element , it is converted into an empty vnode object, and elm is recorded in the attribute.
The judgment here is whether it is Element (oldVnode as any).nodeType === 1 is completed. nodeType === 1 indicates that it is an ELEMENT_NODE, which is defined here.
Then determine whether oldVnode and vnode are the same. sameVnode() will be called here to determine:
function sameVnode(vnode1: VNode, vnode2: VNode): boolean {
//Same key.
const isSameKey = vnode1.key === vnode2.key;
// Web component, custom element tag name, see here:
// https://developer.mozilla.org/zh-CN/docs/Web/API/Document/createElement
const isSameIs = vnode1.data?.is === vnode2.data?.is;
//Same selector.
const isSameSel = vnode1.sel === vnode2.sel;
// All three are the same.
return isSameSel && isSameKey && isSameIs;
} patchVnode() for diff update.createElm() to create a new DOM node; after creation, insert the DOM node and delete the old DOM node.New nodes may be inserted by calling the insert hook queue registered in the vnode object involved in the above operation, patchVnode() createElm() . As for why this is done, it will be mentioned in createElm() .
Finally, the post hook registered on the module is called.
The process is basically to do diff if the vnodes are the same, and if they are different, create new ones and delete the old ones. Next, let's take a look at how createElm() creates DOM nodes.
createElm() creates a DOM node based on the configuration of vnode. The process is as follows:
call the init hook that may exist on the vnode object.
Then we will deal with several situations:
if vnode.sel === '!' , this is the method used by Snabbdom to delete the original node, so that a new comment node will be inserted. Because the old nodes will be deleted after createElm() , this setting can achieve the purpose of uninstallation.
If the vnode.sel selector definition exists:
parse the selector and get id , tag and class .
Call document.createElement() or document.createElementNS to create a DOM node, record it in vnode.elm , and set id , tag , and class based on the results of the previous step.
Call the create hook on the module.
Process the children array:
If children is an array, call createElm() recursively to create the child node, and then call appendChild to mount it under vnode.elm .
If children is not an array but vnode.text exists, it means that the content of this element is text. At this time, createTextNode is called to create a text node and mounted under vnode.elm .
Call the create hook on the vnode. And add the insert hook on vnode to the insert hook queue.
The remaining situation is that vnode.sel does not exist, indicating that the node itself is text, then call createTextNode to create a text node and record it to vnode.elm .
Finally return vnode.elm .
It can be seen from the whole process that createElm() chooses how to create DOM nodes based on different settings of sel selector. There is a detail to add here: the insert hook queue mentioned in patch() . The reason why this insert hook queue is needed is that it needs to wait until the DOM is actually inserted before executing it, and it also needs to wait until all descendant nodes are inserted, so that we can calculate the size and position information of the element in insert to be accurate. Combined with the process of creating child nodes above, createElm() is a recursive call to create child nodes, so the queue will first record the child nodes and then itself. This way the order can be guaranteed when executing the queue at the end of patch() .
Next let's look at how Snabbdom uses patchVnode() to do diff, which is the core of virtual DOM. The processing flow of patchVnode() is as follows:
first execute the prepatch hook on vnode.
If oldVnode and vnode are the same object reference, they will be returned directly without processing.
Call update hooks on modules and vnodes.
If vnode.text is not defined, several cases of children are handled:
if oldVnode.children and vnode.children both exist and are not the same. Then call updateChildren to update.
vnode.children exists but oldVnode.children does not exist. If oldVnode.text exists, clear it first, and then call addVnodes to add new vnode.children .
vnode.children does not exist but oldVnode.children does. Call removeVnodes to remove oldVnode.children .
If neither oldVnode.children nor vnode.children exist. Clear oldVnode.text if it exists.
If vnode.text is defined and is different from oldVnode.text . If oldVnode.children exists, call removeVnodes to clear it. Then set the text content through textContent .
Finally execute the postpatch hook on the vnode.
It can be seen from the process that the changes to the related attributes of its own nodes in diff, such as class , style , etc., are updated by the module. However, we will not expand too much here. If necessary, you can take a look at the module-related code. The main core processing of diff is focused on children . Next, Kangkang diff processes several related functions of children .
is very simple. First call createElm() to create it, and then insert it into the corresponding parent.
destory remove
destory , this hook is called first. The logic is to first call the hook on the vnode object, and then call the hook on the module. Then this hook is called recursively on vnode.children in this order.remove , this hook will only be triggered when the current element is deleted from its parent. The child elements in the removed element will not be triggered, and this hook will be called on both the module and the vnode object. The order is to call the module first. on and then call on vnode. What's more special is that the element will not be actually removed until all remove are called. This can achieve some delayed deletion requirements.It can be seen from the above that the calling logic of these two hooks is different. In particular, remove will only be called on elements that are directly separated from the parent.
updateChildren() is used to process child node diff, and it is also a relatively complex function in Snabbdom. The general idea is to set a total of four head and tail pointers for oldCh and newCh . These four pointers are oldStartIdx , oldEndIdx , newStartIdx and newEndIdx respectively. Then compare the two arrays in while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) loop to find the same parts for reuse and update, and move up to one pair of pointers for each comparison. The detailed traversal process is processed in the following order:
If any of the four pointers points to vnode == null, then the pointer moves to the middle, such as: start++ or end--, the occurrence of null will be explained later.
If the old and new start nodes are the same, that is, sameVnode(oldStartVnode, newStartVnode) returns true, use patchVnode() to perform diff, and both start nodes will move one step toward the middle.
If the old and new end nodes are the same, patchVnode() is also used, and the two end nodes move one step back to the middle.
If the old start node is the same as the new end node, use patchVnode() to process the update first. Then the DOM node corresponding to oldStart needs to be moved. The moving strategy is to move before the next sibling node of the DOM node corresponding to oldEndVnode . Why does it move like this? First of all, oldStart is the same as newEnd, which means that in the current loop processing, the starting node of the old array is moved to the right; because each processing moves the head and tail pointers to the middle, we are updating the old array to the new one. At this time oldEnd may not have been processed yet, but at this time oldStart has been determined to be the last one in the current processing of the new array, so it is reasonable to move to the next sibling node of oldEnd. After the move is completed, oldStart++ and newEnd-- move one step to the middle of their respective arrays.
If the old end node is the same as the new start node, patchVnode() is used to process the update first, and then the DOM node corresponding to oldEnd is moved to the DOM node corresponding to oldStartVnode . The reason for the move is the same as the previous step. After the move is completed, oldEnd--, newStart++.
If none of the above is the case, use the key of newStartVnode to find the subscript idx in oldChildren . There are two different processing logics depending on whether the subscript exists:
If the subscript does not exist, it means that newStartVnode is newly created. Create a new DOM through createElm() and insert it before the DOM corresponding to oldStartVnode .
If the subscript exists, it will be handled in two cases:
if the sel of the two vnodes is different, it will still be regarded as newly created, create a new DOM through createElm() , and insert it before the DOM corresponding to oldStartVnode .
If sel is the same, the update is processed through patchVnode() , and the vnode corresponding to the subscript of oldChildren is set to undefined. This is why == null appears in the previous double pointer traversal. Then insert the updated node into the DOM corresponding to oldStartVnode .
After the above operations are completed, newStart++.
After the traversal is completed, there are still two situations to deal with. One is that oldCh has been completely processed, but there are still new nodes in newCh , and a new DOM needs to be created for each remaining newCh ; the other is that newCh has been completely processed, and there are still old nodes in oldCh . Redundant nodes need to be removed. The two situations are handled as follows:
function updateChildren(
parentElm: Node,
oldCh: VNode[],
newCh: VNode[],
insertedVnodeQueue: VNodeQueue
) {
// Double pointer traversal process.
// ...
// There are new nodes in newCh that need to be created.
if (newStartIdx <= newEndIdx) {
//Needs to be inserted before the last processed newEndIdx.
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
before,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
}
// There are still old nodes in oldCh that need to be removed.
if (oldStartIdx <= oldEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
} Let’s use a practical example to look at the processing process of updateChildren() :
the initial state is as follows, the old child node array is [A, B, C], and the new node array is [B, A, C, D]:

In the first round of comparison, the start and end nodes are different, so we check whether newStartVnode exists in the old node and find the position of oldCh[1]. Then execute patchVnode() to update first, and then set oldCh[1] = undefined , and insert the DOM before oldStartVnode , newStartIdx moves one step backward, and the status after processing is as follows:
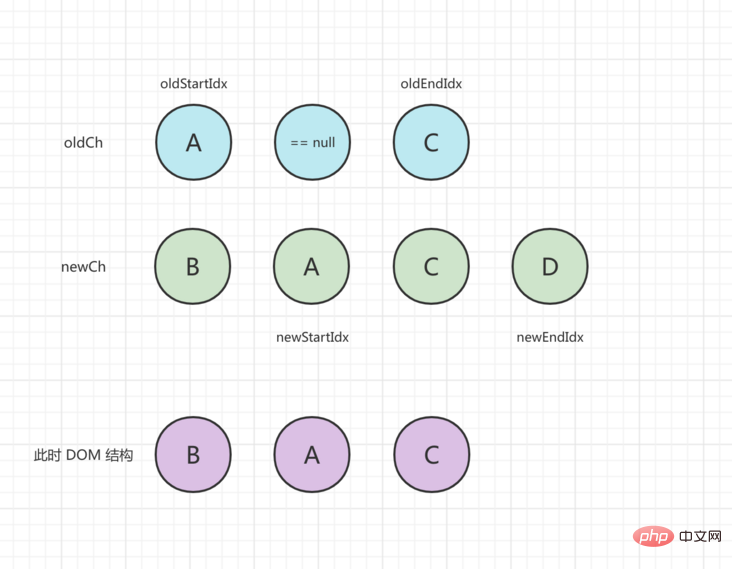
In the second round of comparison, oldStartVnode and newStartVnode are the same. When patchVnode() is executed to update, oldStartIdx and newStartIdx move to the middle. After processing, the status is as follows:
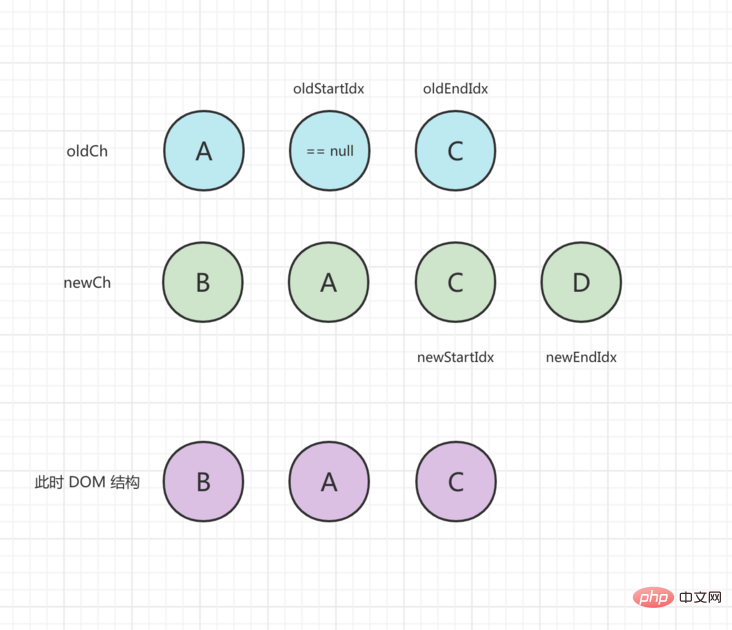
In the third round of comparison, oldStartVnode == null , oldStartIdx moves to the middle, and the status is updated as follows:
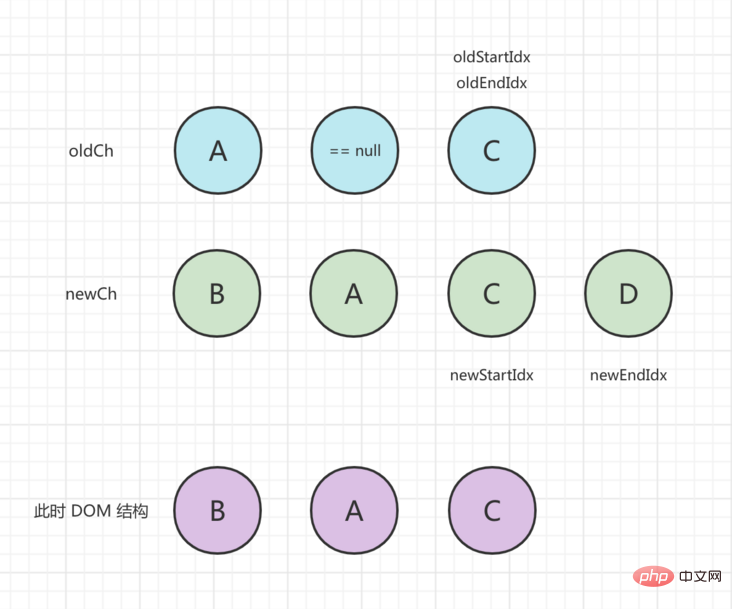
In the fourth round of comparison, oldStartVnode and newStartVnode are the same. When patchVnode() is executed to update, oldStartIdx and newStartIdx move to the middle. After processing, the status is as follows:

At this time, oldStartIdx is greater than oldEndIdx , and the loop ends. At this time, there are still new nodes that have not been processed in newCh , and you need to call addVnodes() to insert them. The final status is as follows:

, the core content of virtual DOM has been sorted out here. I think the design and implementation principles of Snabbdom are very good. If you have time, you can go to the details of Kangkang source code to take a closer look. The ideas are worth learning.