We crawled all the information of the web page in the previous section. Now we have to find the content we need in the html code. Therefore, we need to enter the website according to the problem and parse the information in the web page.
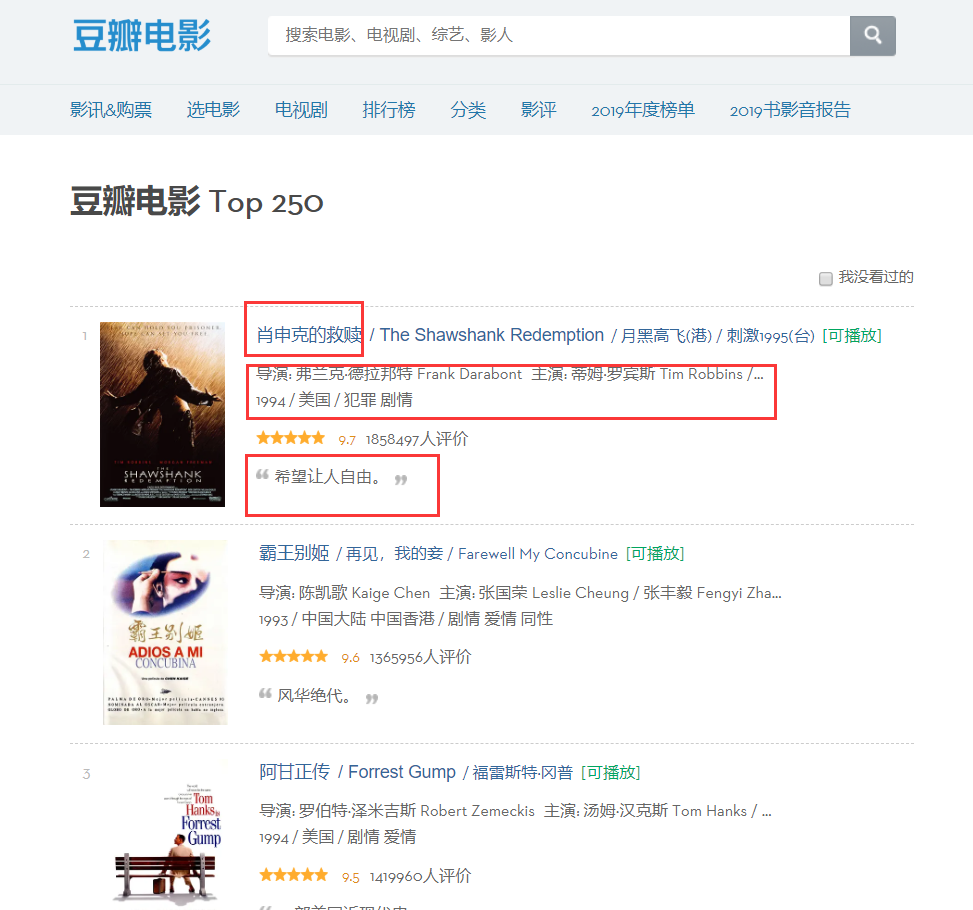
It can be found from the page that the information we need to crawl exists in different partitions, so let's check the elements of the page, right-click the page to check the web page source code or F12.

Before analyzing the web page, we first specify the storage method after parsing. Here we use a list to store all the information, and then each item in the list corresponds to a dictionary, and each dictionary corresponds to multiple types of information.
movies=[]#First define a list to store all information
Through analysis, we can determine that the position of the title is the first 'span' in the first 'a' under the 'div' named 'hd', so we can lock the name of each movie through the following code, and then into a dictionary.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#An item in the dictionaryIn the same way, the source code of the director's name can be found based on positioning, but this source code contains a lot of information, so we need to filter it through regular expressions.
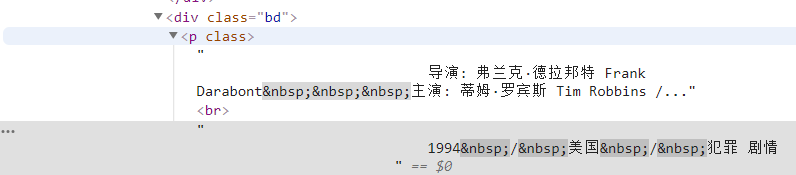
info=each.find('div',class_='bd').p.text.strip()First, we find all the content under this tag, and then filter out irrelevant information through regular expressions.
info=info.replace('n',)#Filter carriage returns info=info.replace(,)#Filter spaces info=info.replace(xa0,)#Filter non-breaking whitespace characters director=re.findall(r '[Director:].+[Starring:]',info)[0]director=director[3:len(director)-6]Then define it as an item in the dictionary.
movie['director']=director#An item in the dictionary
We can find that the movie type is also in this 'p' tag, and we also obtain this information directly through regular expressions.
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Add as an item in the dictionaryFinally, lock the rating information.
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()Then continue to save it in the form of a dictionary.
movie['star']=star
Finally add this dictionary to the list and iterate over the output.
movies.append(movie)#Add the dictionary to the list foriinmovies:#Traverse the output print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Simulate browser to access 'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537.36' ,'Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 times r=requests.get(res,headers =headers,timeout=10)#Set the timeout soup=BeautifulSoup(r.text,html.parser)#Set the parsing method, other methods can also be used. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text.strip()movie['rank']=rankinfo=each.find('div', class_='bd').p.text.strip()info=info.replace('n',)info=info.replace(,)info=info.replace(xa0,)director=re.findall( r'[Director:].+[Starring:]',info)[0]director=director[3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0- 9]{4}',info)[0]movie['release_date']=release_dateplot=re.findall(r'[0-9]*[/].+[/].+',info)[0] plot=plot[1:]plot=plot[plot.index('/')+1:]plot=plot[plot.index('/')+1:]movie['plot']=plotstar=each. find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print (i)Console:

In this example, we mainly learn how to find the corresponding information in the source code of the web page. BeautifulSoup can help us quickly locate it, and then combine it with regular expressions to complete the matching of information. In the next section, we will save this data to the database.