In the AI circle, Turing Award winner Yann Lecun is a typical outlier.
While many technical experts firmly believe that along the current technical route, the realization of AGI is only a matter of time, Yann Lecun has repeatedly raised objections.
In heated debates with his peers, he said more than once that the current mainstream technology path cannot lead us to AGI, and even the current level of AI is not as good as a cat.
Turing Award winner, Meta chief AI scientist, New York University professor, etc. These dazzling titles and heavy front-line practical experience make it impossible for any of us to ignore the insights of this AI expert.

So, what does Yann LeCun think about the future of AI? In a recent public speech, he once again elaborated on his point of view: AI can never reach near-human-level intelligence relying solely on text training.
Some views are as follows:
1. In the future, people will generally wear smart glasses or other types of smart devices. These devices will have built-in assistant systems to form personal intelligent virtual teams to improve personal creativity and efficiency.
2. The purpose of intelligent systems is not to replace humans, but to enhance human intelligence so that people can work more efficiently.
3. Even a pet cat has a model in its brain that is more complex than any AI system can build.
4. FAIR basically no longer focuses on language models, but moves towards the long-term goal of next-generation AI systems.
5. AI systems cannot achieve near-human-level intelligence by training on text data alone.
6. Yann Lecun suggested abandoning generative models, probabilistic models, contrastive learning and reinforcement learning, and instead adopting JEPA architecture and energy-based models, believing that these methods are more likely to promote the development of AI.
7. While machines will eventually surpass human intelligence, they will be controlled because they are goal-driven.
Interestingly, there was an episode before the speech started.
When the host introduced LeCun, he called him the chief AI scientist of Facebook AI Research Institute (FAIR) .
In this regard, LeCun clarified before the speech that the "F" in FAIR no longer represents Facebook, but means " Fundamental ".
The original text of the speech below was compiled by APPSO and has been edited. Finally, the original video link is attached: https://www.youtube.com/watch?v=4DsCtgtQlZU
AI doesn’t understand the world as well as your cat does
Okay, so I'm going to talk about human-level AI and how we're going to get there and why we're not going to get there.
First, we really need human-level AI.
Because in the future, one is that most of us will be wearing smart glasses or other types of devices. We're going to be talking to these devices, and these systems are going to host assistants, maybe more than one, maybe a whole suite of assistants.
This will result in each of us essentially having an intelligent virtual team working for us.
Therefore, everyone will become a "boss", but these "employees" are not real humans. We need to build systems like this, basically to augment human intelligence and make people more creative and efficient.

But for that, we need machines that can understand the world, remember things, have intuition and common sense, and reason and plan at the same level as humans.
Although you may have heard some proponents say that current AI systems do not have these capabilities. So we need to take the time to learn how to model the world, to have mental models of how the world works.
Virtually every animal has such a model. Your cat must have a more complex model than any AI system can build or design.

We need a system that has a persistent memory that current language models (LLMs) do not have, a system that can plan complex sequences of actions that today's systems cannot do, and a system that is controllable and safe.
Therefore, I will propose an architecture called goal-driven AI. I wrote a vision paper about this about two years ago and published it. Many people at FAIR are working hard to make this plan a reality.
FAIR has worked on more application projects in the past, but Meta created a product division called Generative AI (Gen AI) a year and a half ago to focus on AI products.
They do applied research and development, so now FAIR has been redirected toward the long-term goal of next-generation AI systems. We basically no longer focus on language models.
The success of AI, including large language models (LLMs) , and especially the success of many other systems over the past 5 or 6 years, relies on a range of techniques, including, of course, self-supervised learning.

The core of self-supervised learning is to train a system not for any specific task, but to try to represent the input data in a good way. One way to achieve this is through damage-and-rebuild recovery.
So you can take a piece of text and corrupt it by removing some words or changing other words. This process can be used for text, DNA sequences, proteins or anything else, and even to some extent images. You then train a massive neural network to reconstruct the complete input, the uncorrupted version.
This is a generative model because it attempts to reconstruct the original signal.
So, the red box is like a cost function, right? It calculates the distance between the input Y and the reconstructed output y, and this is the parameter to be minimized during the learning process. In this process, the system learns an internal representation of the input, which can be used for various subsequent tasks.
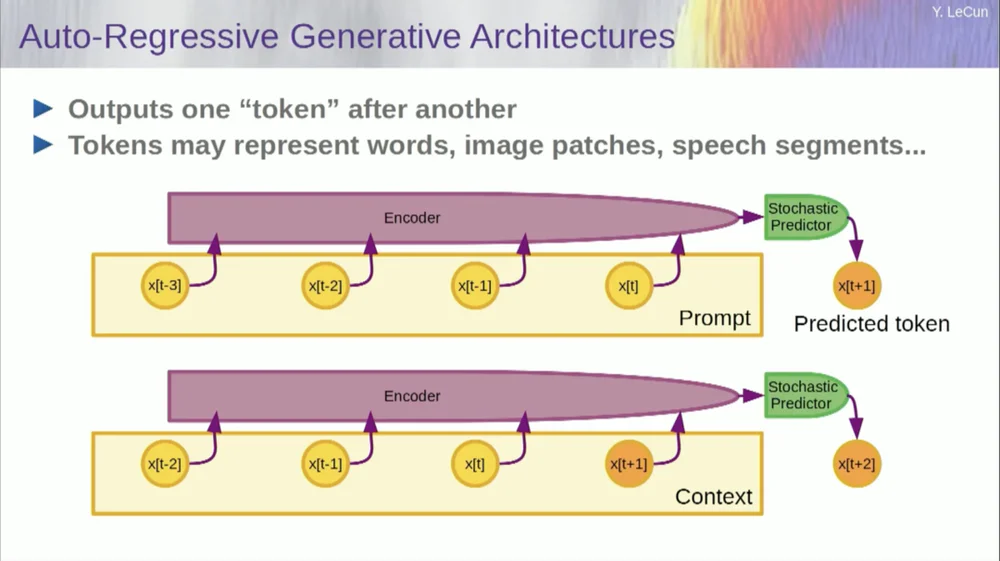
Of course, this can be used to predict words in text, which is what autoregressive prediction does.
Language models are a special case of this, where the architecture is designed in such a way that when predicting an item, a token, or a word, it can only look to the other tokens to its left.
It cannot look into the future. If you train a system correctly, show it text, and ask it to predict the next word or the next token in the text, then you can use the system to predict the next word. Then you add that next word to the input, predict the second word, and add that to the input, predict the third word.
This is autoregressive prediction .
This is what LLMs do, it's not a new concept, it's been around since Shannon's time, going back to the '50s, which is a long time ago, but the change is that we now have those massive neural network architectures, You can train on large amounts of data and features will appear to emerge from it.
But this kind of autoregressive prediction has some major limitations, and there is no real reasoning here in the usual sense.
Yet another limitation is that this only works for data in the form of discrete objects, symbols, tokens, words, etc., basically things that can be discretized.
We're still missing something important when it comes to reaching human-level intelligence.
I'm not necessarily talking about human-level intelligence here, but even your cat or dog can accomplish some amazing feats that are beyond the reach of current AI systems.

Any 10-year-old can learn to clear the table and fill the dishwasher in one sitting, right? No need to practice or anything like that, right?
It takes about 20 hours of practice for a 17-year-old to learn to drive.
We still don’t have Level 5 self-driving cars, and we certainly don’t have home robots capable of clearing tables and filling dishwashers.
AI will never reach near human-level intelligence by training on text alone
So we're really missing something important that otherwise we would be able to do these things with AI systems.
We keep encountering something called Moravec 's Paradox , which is that things that seem trivial to us and are not even considered intelligent are actually very difficult to do with machines, and things like manipulation High-level complex abstract thinking such as language seems to be very simple for machines, and the same is true for things like playing chess and Go.
Maybe one of the reasons is this.
A large language model (LLM) is typically trained on 20 trillion tokens.
A token is basically three-quarters of a word, on average. Therefore, there are 1.5×10^13 words in total. Each token is about 3B, usually, this requires 6×1013 bytes.
It would take about a few hundred thousand years for any of us to read this, right? This is basically all public text on the internet combined.

But think about a child. A four-year-old has been awake for a total of 16,000 hours. We have 2 million optic nerve fibers entering our brain. Each nerve fiber transmits data at about 1B per second, maybe half a byte per second. Some estimates say this could be 3B per second.
It doesn't matter, it's an order of magnitude anyway.
This amount of data is approximately 10 to the 14th power bytes, which is almost the same order of magnitude as LLM. So, in four years, a four-year-old has seen as much visual data as the largest language models trained on publicly available text on the entire internet.
Using the data as a starting point, this tells us several things.
First, this tells us that we will never achieve anywhere near human-level intelligence simply by training on text. This is simply not going to happen.
Secondly, visual information is very redundant. Each optic nerve fiber transmits 1B of information per second, which is already compressed 100 to 1 compared to the photoreceptors in your retina.
There are approximately 60 million to 100 million photoreceptors in our retinas. These photoreceptors are compressed into 1 million nerve fibers by neurons in the front of the retina. So there's already 100 to 1 compression. Then by the time it reaches the brain, the information is expanded about 50 times.
So what I'm measuring is compressed information, but it's still very redundant. And redundancy is actually what self-supervised learning requires. Self-supervised learning will only learn useful things from redundant data. If the data is highly compressed, which means the data becomes random noise, then you cannot learn anything.
You need redundancy to learn anything. You need to learn the underlying structure of the data. Therefore, we need to train the system to learn common sense and physics by watching videos or living in the real world.
The order of my words may be a little confusing. I mainly want to tell you what this goal-driven artificial intelligence architecture is. It's very different from LLMs or feedforward neurons in that the inference process isn't just going through a series of layers of a neural network, but is actually running an optimization algorithm.
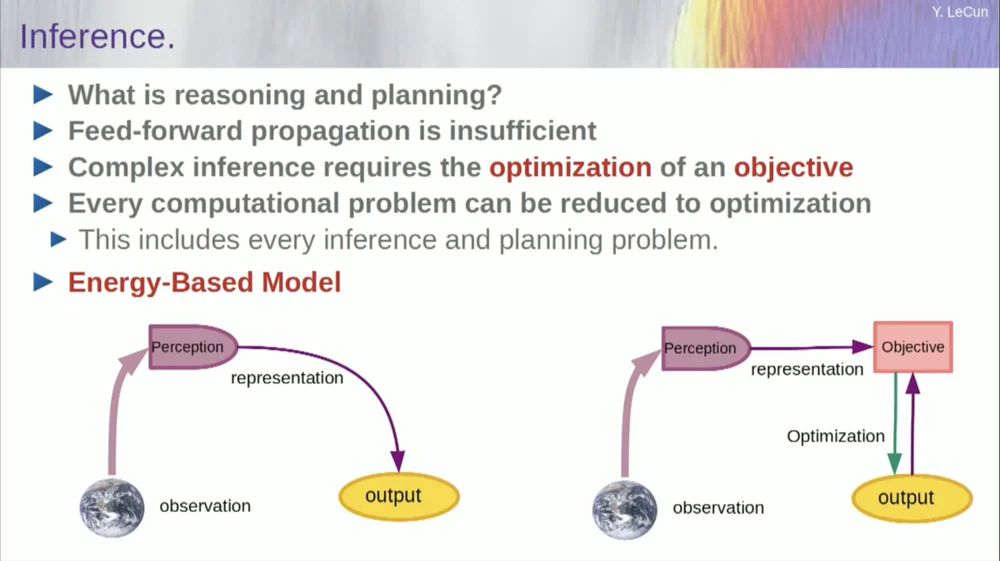
Conceptually, it looks like this.
A feedforward process is one in which observations run through a perceptual system. For example, if you have a series of neural network layers and produce an output, then for any single input, you can only have one output, but in many cases, for a perception, there may be multiple possible output interpretations. You need a mapping process that doesn't just compute functionality, but provides multiple outputs for a single input. The only way to achieve this is through implicit functions.
Basically, the red box on the right side of this goal framework represents a function that basically measures the compatibility between an input and its proposed output, and then calculates the output by finding the output value that is most compatible with the input. You can imagine that this goal is some kind of energy function, and you are minimizing this energy with the output as a variable.
You may have multiple solutions, and you may have some way of handling those multiple solutions. This is true of the human perceptual system. If you have multiple interpretations of a particular perception, your brain will automatically cycle between those interpretations. So there's some evidence that this type of thing does happen.
But let me get back to the architecture. So take advantage of this principle of reasoning by optimization. Here are the assumptions, if you will, about the way the human mind works. You make observations in the world. The perceptual system gives you an idea of the current state of the world. But of course, it only gives you an idea of the state of the world that you can currently perceive.
You may have some remembered ideas about the state of the rest of the world. This may be combined with the contents of the memory and fed into a model of the world.
What is a model? A world model is a mental model of how you behave in the world, so you can imagine a sequence of actions you might take, and your world model will allow you to predict the impact of those sequences of actions on the world.
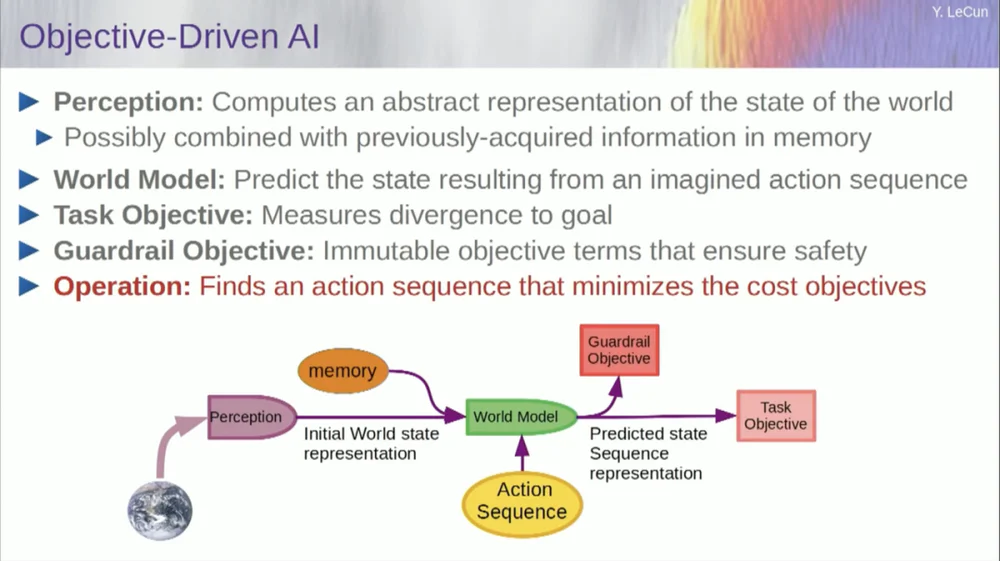
So the green box represents the world model into which you feed a hypothetical sequence of actions that predicts what the end state of the world will be, or the entire trajectory that you predict is going to happen in the world.
You combine that with a set of objective functions. One goal is to measure how well the goal is achieved, whether the task is completed, and maybe a set of other goals that serve as safety margins, basically measuring the extent to which the trajectory followed or the action taken poses no danger to the robot or people around the machine, etc. wait.
So now the reasoning process (I haven't talked about learning yet) is just reasoning and consists of finding sequences of actions that minimize these goals, finding sequences of actions that minimize these goals. This is the reasoning process.
So it's not just a feedforward process. You could do this by searching for discrete options, but that's not efficient. A better approach is to ensure that all these boxes are differentiable, you can backpropagate the gradient through them and then update the sequence of actions via gradient descent.

Now, this idea is actually not new and has been around for over 60 years, maybe even longer. First, let me talk about the advantages of using a world model for this kind of reasoning. The advantage is that you can complete new tasks without any learning required.
We do this from time to time. When we are faced with a new situation, we think about it, imagine the consequences of our actions, and then take a sequence of actions that will achieve our goal (whatever it is) . We don't need to learn to accomplish that task, we can plan. So that's basically planning.
You can boil most forms of reasoning down to optimization. Therefore, the process of inference through optimization is inherently more powerful than simply running through multiple layers of a neural network. As I said, this idea of reasoning through optimization has been around for over 60 years.
In the field of optimal control theory, this is called model predictive control.
You have a model of a system that you want to control, such as a rocket, airplane, or robot. You can imagine using your world model to calculate the effects of a series of control commands.
Then you optimize this sequence so that the movement achieves your desired results. All motion planning in classical robotics is done this way, and it's nothing new. The novelty here is that we will learn a model of the world and the perceptual system will extract an appropriate abstract representation.
Now, before I get into an example of how to run this system, you can build an overall AI system with all these components: a world model, a cost function that can be configured for the task at hand, an optimization module (i.e., truly optimizing, finding the given module that determines the optimal sequence of actions for the world model) , short-term memory, perceptual system, etc.
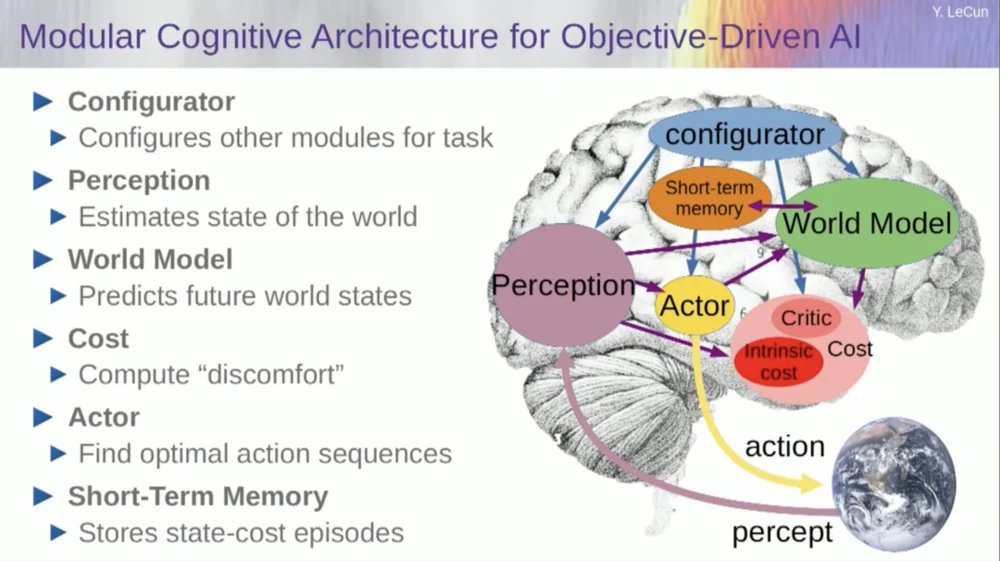
So, how does this work? If your action is not a single action, but a sequence of actions, and your world model is actually a system that tells you, given the world state at time T and possible actions, predict the world state at time T+1 .
You want to predict what effect a sequence of two actions will have in this situation. You can run your world model multiple times to achieve this.
Obtain the initial world state representation, input the assumption of zero for the action, use the model to predict the next state, then perform action one, calculate the next state, calculate the cost, and then use backpropagation and gradient-based optimization methods to find out what will minimize Cost of two actions. This is model predictive control.
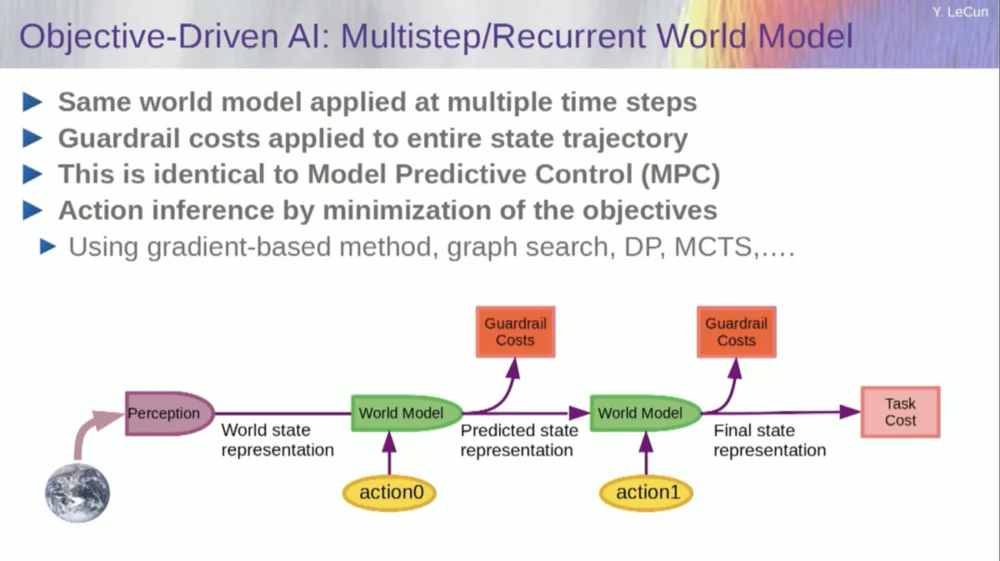
Now, the world is not completely deterministic, so you have to use latent variables to fit your model of the world. Latent variables are basically variables that can be switched within a set of data or drawn from a distribution, and they represent the switching of a model of the world between multiple predictions that are compatible with observations.
What’s even more interesting is that intelligent systems are currently unable to do something that humans and even animals can do, which is hierarchical planning.
For example, if you were planning a trip from New York to Paris, you could use your understanding of the world, your body, and perhaps your idea of the entire configuration of getting from here to Paris to plan your entire trip with your low-level muscle control. travel.
Right? If you add up the number of muscle control steps per ten milliseconds of all the things you have to do before going to Paris, it's a huge number. So what you do is you plan in a hierarchical planning way, where you start at a very high level and say, okay, to get to Paris, I first need to go to the airport, get on a plane.
How do I get to the airport? Let's say I'm in New York City and I have to go downstairs and get a cab. How do I get downstairs? I have to get up from the chair, open the door, walk to the elevator, press the button, etc. How do I get up from a chair?
At some point you're going to have to express things as low-level muscle control actions, but we're not planning the whole thing in a low-level way, we're doing hierarchical planning.

How to do this using AI systems is still completely unsolved and we have no clue.
This seems to be an important requirement for intelligent behavior.
So, how do we learn world models that are capable of hierarchical planning, capable of working at different levels of abstraction? No one has shown anything close to this. This is a major challenge. The image shows the example I just mentioned.
So, how do we train this world model now? Because this is indeed a big problem.
I try to figure out at what age babies learn basic concepts about the world. How do they learn intuitive physics, physical intuition, and all that stuff? This happens long before they start learning things like language and interaction.
So capabilities like face tracking actually happen very early. Biological motion, the distinction between animate and inanimate objects, also appears early. The same goes for object constancy, which refers to the fact that an object persists when it is occluded by another object.
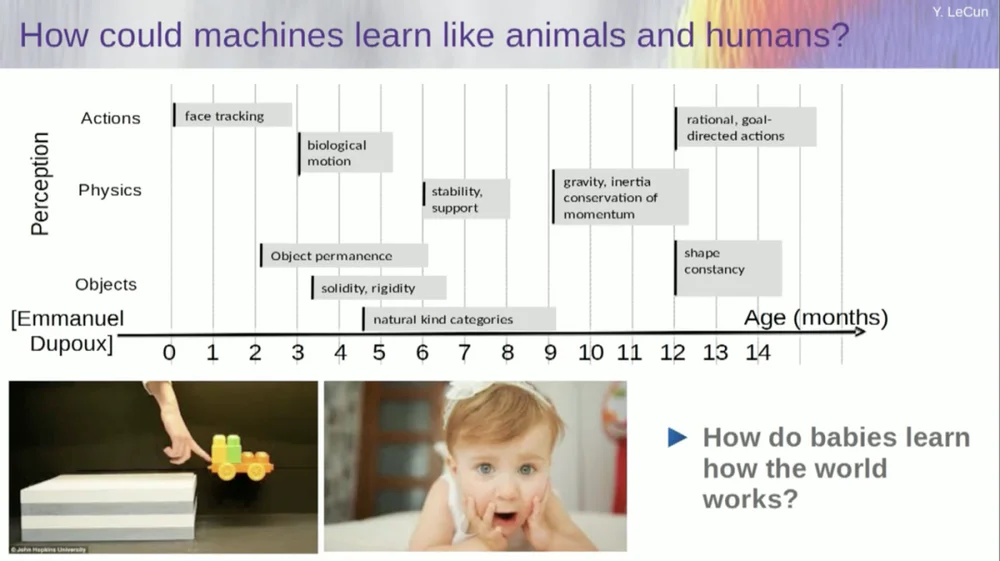
And babies learn naturally, you don't need to give them names for things. They will know that chairs, tables and cats are different. As for concepts such as stability and support, such as gravity, inertia, conservation, and momentum, they actually do not appear until about nine months of age.
This takes a long time. So if you show a six-month-old baby the scenario on the left, where the cart is on a platform, and you push it off the platform, it appears to float in the air. A six-month-old baby will notice this, while a ten-month-old baby will feel that this shouldn't happen and that the object should fall.
When something unexpected happens, it means your "model of the world" is wrong. So you pay attention because it could kill you.
So the type of learning that needs to happen here is very similar to the type of learning we discussed earlier.
Take the input, corrupt it in some way, and train a large neural network to predict the missing parts. If you train a system to predict what is going to happen in a video, just like we train neural networks to predict what is going to happen in text, maybe those systems will be able to learn common sense.
Unfortunately, we've been trying this for ten years and it's been a complete failure. We've never come close to a system that can actually learn any general knowledge by just trying to predict pixels in a video.
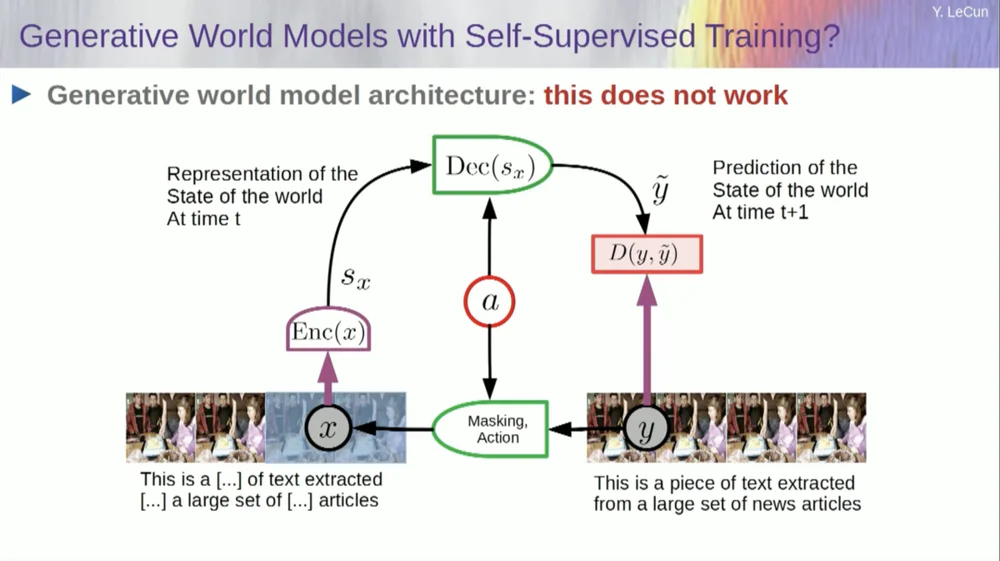
You can train a system to predict videos that look good. There are many examples of video generation systems, but internally they are not good models of the physical world. We can't do this with them.
Okay, so the idea that we're going to use generative models to predict what's going to happen to individuals, and the system will magically understand the structure of the world, is a complete failure.
Over the past decade we have tried many approaches.
It fails because there are many possible futures. In a discrete space like text, where you can predict which word will follow a string of words, you can generate a probability distribution over the possible words in a dictionary. But when it comes to video frames, we don't have a good way to represent the probability distribution of video frames. In fact, this task is completely impossible.

Like, I took a video of this room, right? I took the camera and filmed that part and then stopped the video. I asked the system what would happen next. It might predict the remaining rooms. There will be a wall, there will be people sitting on it, and the density will probably be similar to the one on the left, but it's absolutely impossible to accurately predict at the pixel level all the details of what each of you will look like, the texture of the world, and the exact size of the room.
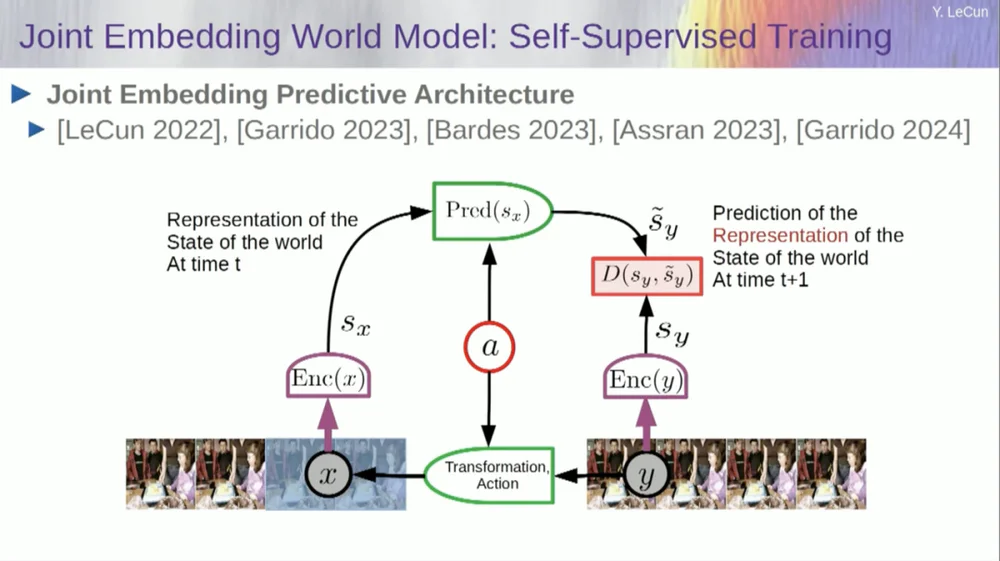
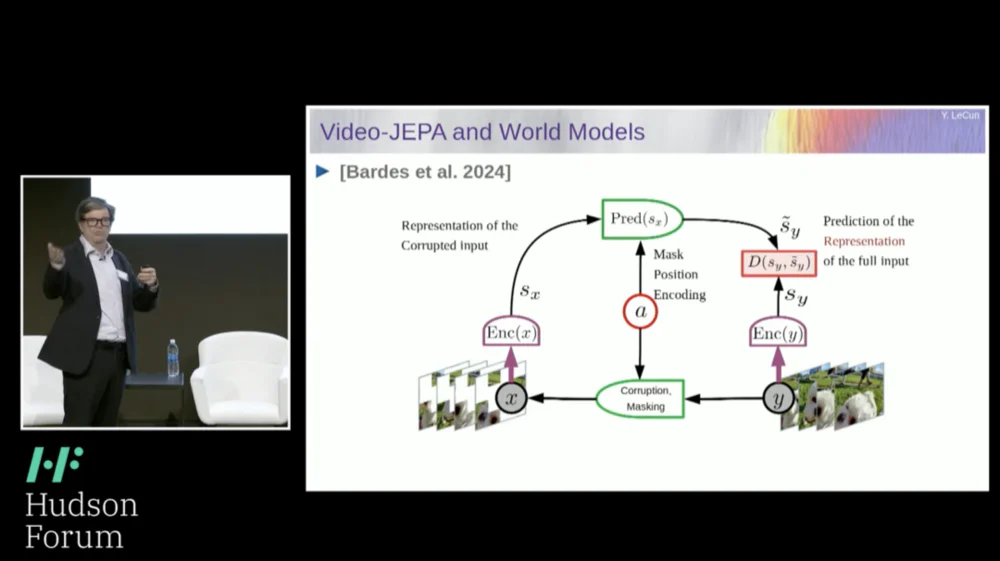
So, my proposed solution is the Joint Embedding Prediction Architecture (JEPA) .
The idea is to give up predicting pixels and instead learn an abstract representation of how the world works and then make predictions within this representation space. That's the architecture, the joint embedding prediction architecture. These two embeddings take X (the corrupted version) and Y respectively, are processed by the encoder, and then the system is trained to predict the representation of Y based on the representation of X.
Now the problem is that if you train such a system just using gradient descent, backpropagation to minimize the prediction error, it will collapse. It might learn a constant representation so that predictions become very simple, but uninformative.
So what I want you to remember is the difference between autoencoders, generative architectures, masked autoencoders, etc., which try to reconstruct predictions, versus joint embedding architectures that make predictions in representation space.
I think the future lies in these joint embedding architectures, and we have a lot of empirical evidence that the best way to learn good image representations is to use joint editing architectures.
All attempts to learn image representations through reconstruction have been poor and don't work well, and although there are many large projects claiming they work, they don't, and the best performance is obtained with the architecture on the right.
Now, if you think about it, this is really what our intelligence is all about: finding a good representation of a phenomenon so that we can make predictions, that's really what science is about.
real. Think about it, if you want to predict the trajectory of a planet, a planet is a very complex object, it's huge, it has all kinds of characteristics like weather, temperature and density.
Although it is a complex object, to predict the trajectory of a planet, you only need to know 6 numbers: 3 position coordinates and 3 velocity vectors, that's it, you don't need to do anything else. This is a very important example that really shows that the essence of predictive power lies in finding a good representation of the things we observe.

So, how do we train such a system?
So you want to prevent the system from crashing. One way to do this is to use some kind of cost function that measures the information content of the representation output by the encoder and tries to maximize the information content and minimize negative information. Your training system should simultaneously extract as much information as possible from the input while minimizing the prediction error in that representation space.
The system will find some trade-off between extracting as much information as possible and not extracting unpredictable information. You will get a good representation space in which predictions can be made.
Now, how do you measure information? This is where things get a little weird. I'll skip this.
Machines will surpass human intelligence and be safe and controllable
There is actually a way to understand this mathematically through training, energy-based models and energy functions, but I don't have time to go into it.
Basically, I'm telling you a few different things here: abandon generative models in favor of those JEPA architectures, abandon probabilistic models in favor of those energy-based models, abandon contrastive learning methods, and reinforcement learning. I've been saying this for 10 years.
And these are the four most popular pillars of machine learning today. So I'm probably not very popular at the moment.
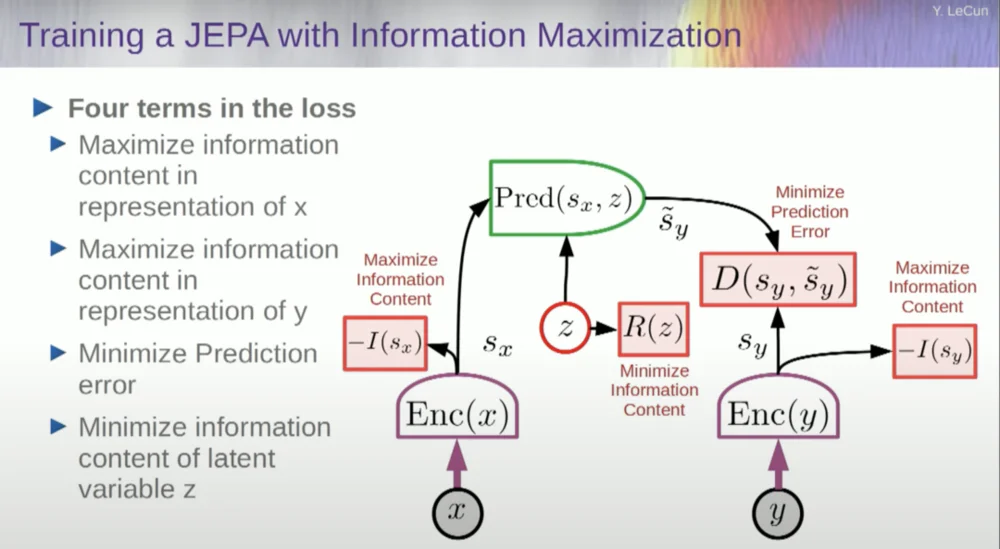
One approach is to estimate information content, measuring the information content coming from the encoder.
There are currently six different ways to achieve this. Actually, there's a method here called MCR, from my colleagues at NYU, which is to prevent the system from crashing and producing constants.
Take the variables from the encoder and make sure these variables have non-zero standard deviation. You could put this into a cost function and make sure the weights are searched and the variables don't collapse and become constants. This is relatively simple.
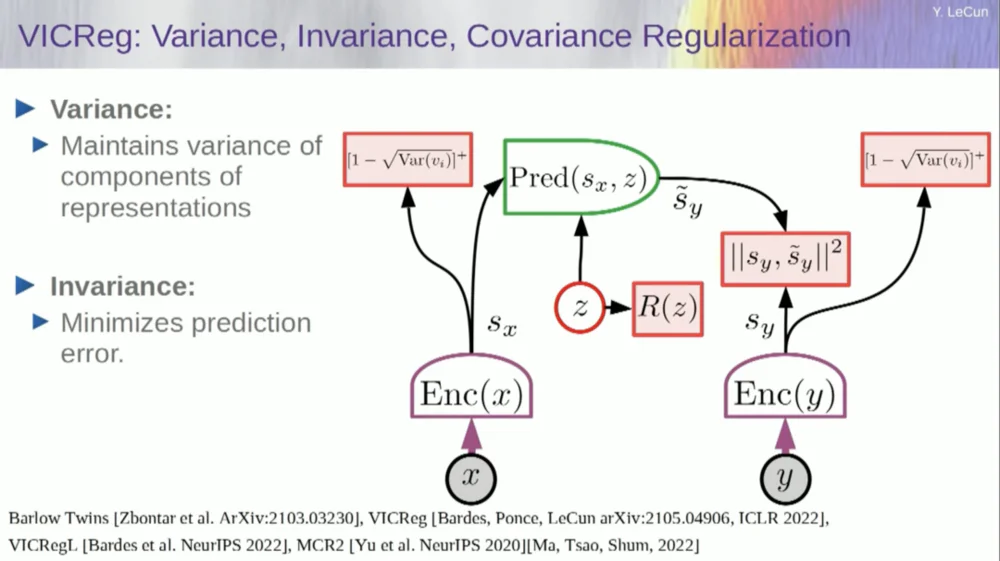
The problem now is that the system can "cheat" and make all variables equal or highly correlated. Therefore, you need to add another term, the off-diagonal term required to minimize the covariance matrix of these variables, to ensure that they are related.
Of course, this is not enough, since the variables may still be dependent, but not related. Therefore, we adopt another method to extend the dimensions of SX to a higher dimensional space VX and apply variance-covariance regularization in this space to ensure that the requirements are met.
There's another trick here, because what I'm maximizing is the upper limit of information content. I want the actual information content to follow my maximization of the upper limit. What I need is a lower limit so that it pushes the lower limit and the information increases. Unfortunately, we don't have information about lower bounds, or at least we don't know how to compute them.
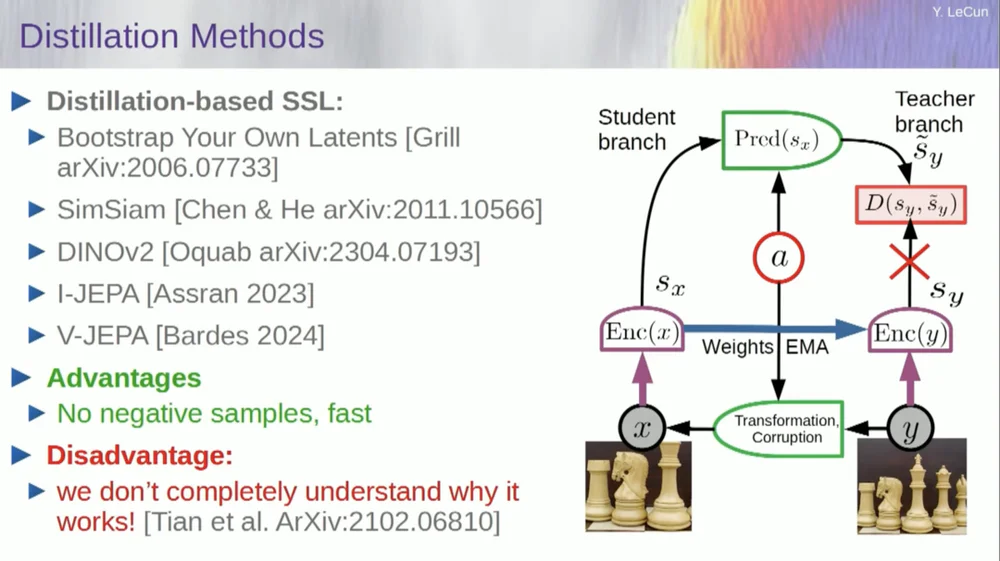
There is a second set of methods called the "distillation style method."
This method works in mysterious ways. If you want to know exactly who is doing what, you should ask the guy sitting here at the Grill.
He has a personal essay on this that defines it very well. Its core idea is to update only one part of the model without backpropagating gradients in the other part and share the weights in an interesting way. There are also many papers on this aspect.
This approach works well if you want to train a fully self-supervised system to generate good image representations. Destruction of images is done through masking, and some recent work we have done for videos allows us to train a system to extract good video representations for use in downstream tasks such as action recognition videos, etc. You can see that masking out a large chunk of a video and making predictions through this process uses this distillation trick in the representation space to prevent collapse. This works great.
So if we succeed in this project and end up with systems that can reason, plan, and understand the physical world, this is what all of our interactions will look like in the future.
It's going to take years, maybe even a decade, to get everything working properly. Mark Zuckerberg keeps asking me how long it will take. If we succeed in doing that, okay, we'll have systems that mediate all of our interactions with the digital world. They will answer all our questions.
They will be with us for a lot of time and will essentially form a repository of all human knowledge. This feels like an infrastructure thing, like the Internet. This is less of a product and more of an infrastructure.
These AI platforms must be open source. IBM and Meta participate in a group called the Artificial Intelligence Alliance that promotes open source artificial intelligence platforms. We need these platforms to be open source because we need diversity in these AI systems.

We need them to understand all the languages, all the cultures, all the value systems in the world, and you're not going to get that from just a single system produced by a company on the West Coast or the East Coast of the United States. This must be a contribution from all over the world.
Of course, training financial models is very expensive, so only a few companies are able to do this. If companies like Meta can provide the underlying model as open source, then the world can fine-tune it for their own purposes. This is the philosophy adopted by Meta and IBM.

So open source AI is not just a good idea, it is necessary for cultural diversity and perhaps even the preservation of democracy.
Training and fine-tuning will be done through crowdsourcing or by an ecosystem of startups and other companies.
That's one of the things that's driving the growth of the AI startup ecosystem is the availability of these open source AI models. How long will it take to reach general artificial intelligence? I don't know, it could take years to decades.

There have been a lot of changes along the way, and there are still many problems that need to be solved. This will almost certainly be more difficult than we think. This doesn’t happen in one day, but is a gradual, incremental evolution.
So it’s not that one day we will discover the secret of general artificial intelligence, turn on the machine and instantly have super intelligence, and we will all be wiped out by super intelligence, no, that is not the case.
Machines will surpass human intelligence, but they will be under control because they are goal-driven. We set goals for them and they accomplish them. Like many of us here are leaders in industry or academia.
We work with people smarter than us, and I certainly do too. Just because there are a lot of people smarter than me doesn't mean they want to dominate or take over, that's just the truth of the matter. Of course there are risks behind this, but I will leave that for discussion later, thank you very much.