The latest multi-modal language model BLIP-3-Video released by the Salesforce AI research team provides a solution for efficiently processing the growing video data. This model aims to improve the efficiency and effect of video understanding, and is widely used in fields such as autonomous driving and entertainment, bringing innovation to all walks of life. The editor of Downcodes will explain in detail the core technology and excellent performance of BLIP-3-Video.
Recently, the Salesforce AI research team launched a new multi-modal language model-BLIP-3-Video. With the rapid increase of video content, how to efficiently process video data has become an urgent problem to be solved. The emergence of this model aims to improve the efficiency and effectiveness of video understanding and is suitable for various industries from autonomous driving to entertainment.
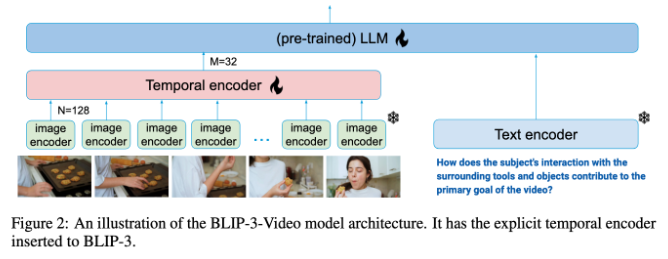
Traditional video understanding models often process videos frame by frame and generate a large amount of visual information. This process not only consumes a lot of computing resources, but also greatly limits the ability to process long videos. As the amount of video data continues to grow, this approach becomes increasingly inefficient, so it is critical to find a solution that captures the key information of the video while reducing the computational burden.
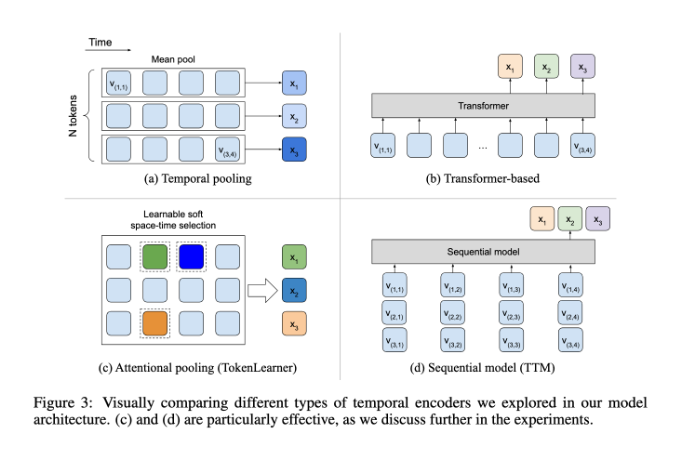
In this regard, BLIP-3-Video performs quite well. This model successfully reduces the amount of visual information required in the video to 16 to 32 visual markers by introducing a "temporal encoder". This innovative design greatly improves computational efficiency, allowing the model to complete complex video tasks at a lower cost. This temporal encoder employs a learnable spatiotemporal attention pooling mechanism that extracts the most important information from each frame and integrates it into a compact set of visual markers.
BLIP-3-Video also performs very well. By comparing with other large-scale models, the study found that the accuracy of this model in video question answering tasks is comparable to that of top models. For example, the Tarsier-34B model requires 4608 markers to process 8 frames of video, while BLIP-3-Video only needs 32 markers to achieve an MSVD-QA benchmark score of 77.7%. This shows that BLIP-3-Video significantly reduces resource consumption while maintaining high performance.
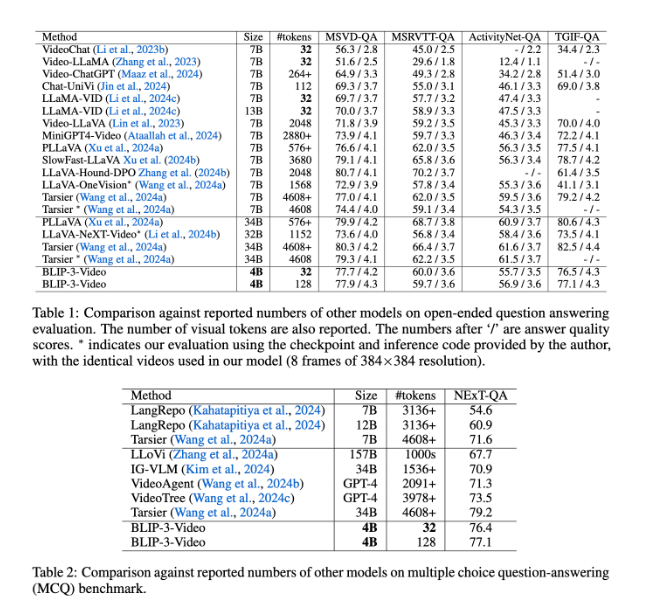
In addition, the performance of BLIP-3-Video in multiple-choice question and answer tasks cannot be underestimated. In the NExT-QA data set, the model achieved a high score of 77.1%, and in the TGIF-QA data set, it also achieved an accuracy of 77.1%. These data demonstrate the efficiency of BLIP-3-Video in handling complex video problems.

BLIP-3-Video opens up new possibilities in video processing with its innovative timing encoder. The launch of this model not only improves the efficiency of video understanding, but also provides more possibilities for future video applications.
Project entrance: https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
BLIP-3-Video provides a new direction for future video technology development with its efficient video processing capabilities. Its excellent performance in video question and answer and multiple-choice question and answer tasks demonstrates its huge potential in resource saving and performance improvement. We look forward to BLIP-3-Video playing a role in more fields and promoting the advancement of video technology.