The editor of Downcodes will explain to you the latest research results from Princeton University and Yale University! This research deeply explores the "Chain of Thought (CoT)" reasoning capabilities of large language models (LLM), revealing that CoT reasoning is not a simple application of logical rules, but a complex fusion of multiple factors such as memory, probability, and noise reasoning. The researchers selected the shift cipher cracking task and conducted in-depth analysis of three LLMs: GPT-4, Claude3 and Llama3.1. Finally, they discovered three key factors that affect the CoT inference effect, and proposed the inference mechanism of LLM. new insights.
Researchers from Princeton University and Yale University recently released a report on the "Chain of Thought (CoT)" reasoning capabilities of large language models (LLM), revealing the secret of CoT reasoning: it is not purely symbolic reasoning based on logical rules, but It combines multiple factors such as memory, probability and noise reasoning.
The researchers used cracking the shift cipher as a test task and analyzed the performance of three LLMs: GPT-4, Claude3 and Llama3.1. A shift cipher is a simple encoding in which each letter is replaced by a letter shifted forward a fixed number of places in the alphabet. For example, move the alphabet forward 3 places, and CAT becomes FDW.
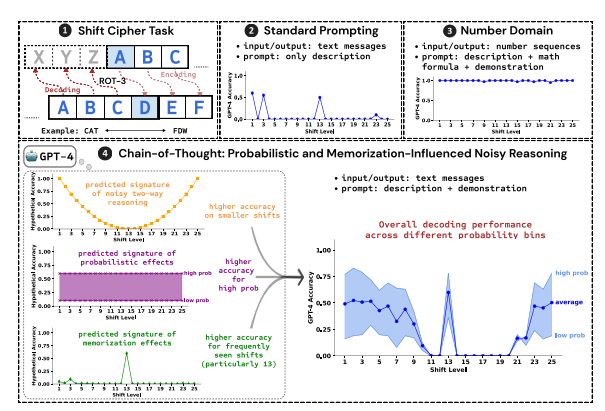
The research results show that the three key factors affecting the CoT reasoning effect are:
Probabilistic: LLM prefers to generate higher probability outputs, even if the inference steps lead to lower probability answers. For example, if the inference step points to STAZ, but STAY is a more common word, LLM may "self-correct" and output STAY.
Memory: LLM remembers a large amount of text data during pre-training, which affects the accuracy of its CoT inference. For example, rot-13 is the most common shift cipher, and the accuracy of LLM on rot-13 is significantly higher than other types of shift ciphers.
Noise inference: The inference process of LLM is not completely accurate, but there is a certain degree of noise. As the shift amount of the shift cipher increases, the intermediate steps required for decoding also increase, and the impact of noise inference becomes more obvious, causing the accuracy of LLM to decrease.
The researchers also found that LLM’s CoT reasoning relies on self-conditioning, that is, LLM needs to explicitly generate text as the context for subsequent reasoning steps. If the LLM is instructed to "think silently" without outputting any text, its reasoning ability is significantly reduced. In addition, the effectiveness of the demonstration steps has little impact on CoT reasoning. Even if there are errors in the demonstration steps, the CoT reasoning effect of LLM can still remain stable.
This study shows that LLM's CoT reasoning is not perfect symbolic reasoning, but incorporates multiple factors such as memory, probability and noise reasoning. LLM shows the characteristics of both a memory master and a probability master during the CoT reasoning process. This research helps us gain a deeper understanding of LLM’s reasoning capabilities and provides valuable insights for developing more powerful AI systems in the future.
Paper address: https://arxiv.org/pdf/2407.01687
This research report provides a valuable reference for us to understand the "thinking chain" reasoning mechanism of large language models, and also provides a new direction for the design and optimization of future AI systems. The editor of Downcodes will continue to pay attention to the cutting-edge developments in the field of artificial intelligence and bring you more exciting content!