The research team of the Computing Innovation Institute of Zhejiang University has made a breakthrough in solving the problem of insufficient ability of large language models to process tabular data and launched a new model TableGPT2. With its unique table encoder, TableGPT2 can efficiently process various table data, bringing revolutionary changes to data-driven applications such as business intelligence (BI). The editor of Downcodes will explain in detail the innovation and future development direction of TableGPT2.
The rise of large language models (LLMs) has brought revolutionary changes to artificial intelligence applications. However, they have obvious shortcomings in processing tabular data. To address this problem, a research team from the Computing Innovation Institute of Zhejiang University has launched a new model called TableGPT2, which can integrate and process tabular data directly and efficiently, opening up new avenues for business intelligence (BI) and other data-driven applications. new possibilities.
The core innovation of TableGPT2 lies in its unique table encoder, which is specially designed to capture the structural information and cell content information of the table, thereby enhancing the model's ability to handle fuzzy queries, missing column names and irregular tables that are common in real-world applications. . TableGPT2 is based on the Qwen2.5 architecture and has undergone large-scale pre-training and fine-tuning, involving more than 593,800 tables and 2.36 million high-quality query-table-output tuples, which is an unprecedented scale of table-related data in previous research. .
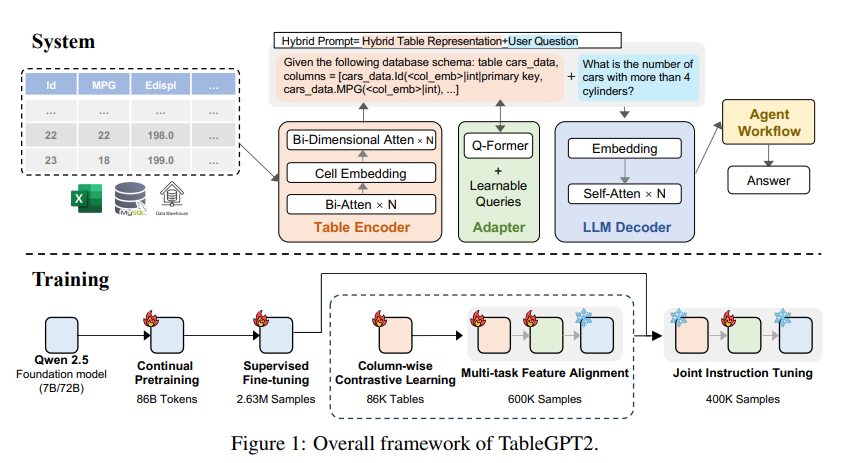
In order to improve the coding and reasoning capabilities of TableGPT2, the researchers conducted continuous pre-training (CPT), in which 80% of the data is carefully annotated code to ensure that it has strong coding capabilities. In addition, they also collected a large amount of inference data and textbooks containing domain-specific knowledge to enhance the model's inference capabilities. The final CPT data contains 86 billion strictly filtered tokens, which provides the necessary encoding and reasoning capabilities for TableGPT2 to handle complex BI tasks and other related tasks.
To address the limitations of TableGPT2 in adapting to specific BI tasks and scenarios, the researchers performed supervised fine-tuning (SFT) on it. They built a dataset covering a variety of critical and real-world scenarios, including multiple rounds of conversations, complex reasoning, tool usage, and highly business-oriented queries. The dataset combines manual annotation with an expert-driven automated annotation process to ensure data quality and relevance. The SFT process, using a total of 2.36 million samples, further refined the model to meet the specific needs of BI and other environments involving tables.
TableGPT2 also innovatively introduces a semantic table encoder that takes the entire table as input and generates a compact set of embedding vectors for each column. This architecture is customized for the unique properties of tabular data, effectively capturing the relationships between rows and columns through a bidirectional attention mechanism and hierarchical feature extraction process. In addition, a columnar contrastive learning method is adopted to encourage the model to learn meaningful, structure-aware tabular semantic representations.
In order to seamlessly integrate TableGPT2 with enterprise-level data analysis tools, the researchers also designed an agent workflow runtime framework. The framework consists of three core components: runtime hint engineering, secure code sandbox, and agent evaluation module, which together enhance the agent's capabilities and reliability. Workflows support complex data analysis tasks through modular steps (input normalization, agent execution, and tool invocation) that work together to manage and monitor agent performance. By integrating Retrieval Augmented Generation (RAG) for efficient contextual retrieval and code sandboxing for safe execution, the framework ensures that TableGPT2 delivers accurate, context-sensitive insights in real-world problems.
The researchers conducted an extensive evaluation of TableGPT2 on a variety of widely used tabular and general purpose benchmarks. The results show that TableGPT2 excels in table understanding, processing and reasoning, with an average performance improvement of 35.20% for a 7 billion parameter model, 720 The average performance of the 100 million parameter model increased by 49.32%, while maintaining strong general performance. For a fair evaluation, they only compared TableGPT2 to open-source, benchmark-neutral models such as Qwen and DeepSeek, ensuring balanced, versatile performance of the model on a variety of tasks without overfitting any single benchmark. test. They also introduced and partially released a new benchmark, RealTabBench, which emphasizes unconventional tables, anonymous fields, and complex queries to be more consistent with real-life scenarios.
Although TableGPT2 achieves state-of-the-art performance in experiments, challenges still exist in deploying LLM into real-world BI environments. The researchers noted that future research directions include:
Domain-specific coding: Enables LLM to quickly adapt enterprise-specific domain-specific languages (DSLs) or pseudocode to better meet the specific needs of enterprise data infrastructure.
Multi-Agent Design: Explore how to effectively integrate multiple LLMs into a unified system to handle the complexity of real-world applications.
Versatile table processing: Improve the model's ability to handle irregular tables, such as merged cells and inconsistent structures common in Excel and Pages, to better handle various forms of tabular data in the real world.
The launch of TableGPT2 marks LLM's significant progress in processing tabular data, bringing new possibilities for business intelligence and other data-driven applications. I believe that as research continues to deepen, TableGPT2 will play an increasingly important role in the field of data analysis in the future.
Paper address: https://arxiv.org/pdf/2411.02059v1
The emergence of TableGPT2 has brought a new dawn to the field of business intelligence. Its efficient table data processing capabilities and strong scalability indicate that data analysis will be more intelligent and convenient in the future. We look forward to TableGPT2 being more widely used in the future and bringing more value to all walks of life.