In the field of AI image generation and understanding, existing models often face the challenge of balancing understanding and generation capabilities. They are inefficient and rely on a large number of pre-trained components. The JanusFlow framework launched by DeepSeek AI provides a new idea to solve this problem. The editor of Downcodes will give you an in-depth understanding of how JanusFlow achieves the unification of image understanding and generation through innovative architectural design, and achieves remarkable results.
Despite rapid progress in the field of AI-driven image generation and understanding, significant challenges remain that hinder the development of a seamless, unified approach.
Currently, models focused on image understanding tend to perform poorly at generating high-quality images, and vice versa. This task-separated architecture not only increases complexity, but also limits efficiency, making it cumbersome to handle tasks that require both understanding and generation. Additionally, many existing models rely too heavily on architectural modifications or pre-trained components to effectively perform any function, leading to performance trade-offs and integration challenges.
To solve these problems, DeepSeek AI launched JanusFlow, a powerful AI framework designed to unify image understanding and generation. JanusFlow solves the previously mentioned inefficiencies by integrating image understanding and generation into a unified architecture. This novel framework features a minimalist design that combines autoregressive language models with rectified flow, a state-of-the-art generative modeling approach.
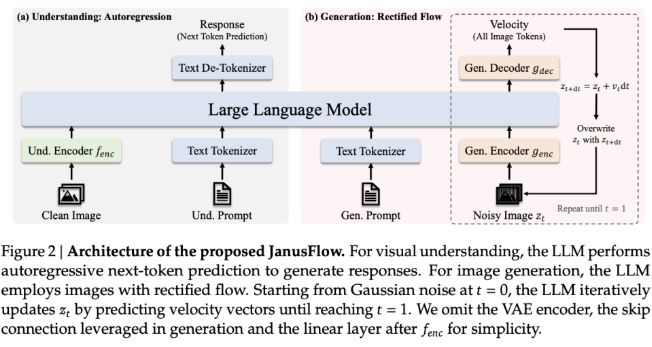
By eliminating the need for separate LLM and generation components, JanusFlow enables tighter functional integration while reducing architectural complexity. It introduces a dual encoder-decoder structure, decouples understanding and generation tasks, and ensures performance consistency in a unified training scheme by aligning representations.
In terms of technical details, JanusFlow integrates corrective flow and large language models in a lightweight and efficient manner. The architecture includes independent visual encoders for comprehension and generation tasks. During training, these encoders are aligned with each other to improve semantic consistency, allowing the system to perform well in image generation and visual understanding tasks.
This decoupling of encoders prevents interference between tasks, thereby enhancing the capabilities of each module. The model also employs classifier-free guidance (CFG) to control the alignment between generated images and textual conditions, thereby improving image quality. Compared to traditional unified systems that use diffusion models as external tools, JanusFlow provides a simpler and more direct generation process with fewer limitations. The effectiveness of this architecture is demonstrated by its ability to match or exceed the performance of many task-specific models on multiple benchmarks.
The importance of JanusFlow lies in its efficiency and versatility, filling a critical gap in multimodal model development. By eliminating the need for independent generation and understanding modules, JanusFlow enables researchers and developers to leverage a single framework for multiple tasks, significantly reducing complexity and resource usage.
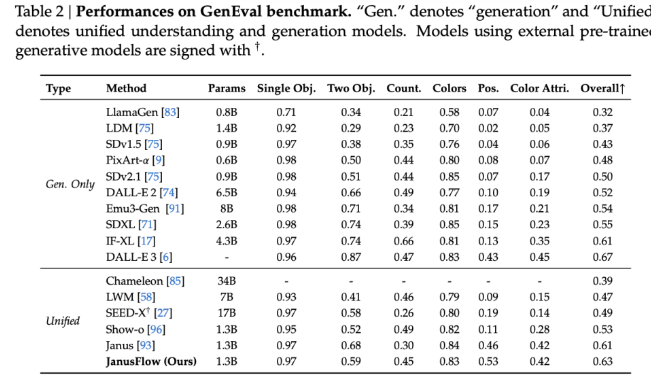
Benchmark results show that JanusFlow outperforms many existing unified models with scores of 74.9, 70.5 and 60.3 on MMBench, SeedBench and GQA respectively. In terms of image generation, JanusFlow surpassed SDv1.5 and SDXL, with a score of 9.51 for MJHQ FID-30k and a score of 0.63 for GenEval. These metrics demonstrate its excellent ability to generate high-quality images and handle complex multi-modal tasks with only 1.3B parameters.
In conclusion, JanusFlow has taken an important step towards developing a unified AI model capable of simultaneous image understanding and generation. Its minimalist approach—focused on integrating autoregressive capabilities with corrective flows—not only improves performance but also simplifies model architecture, making it more efficient and accessible.
By decoupling the visual encoder and aligning representations during training, JanusFlow successfully bridges image understanding and generation. As AI research continues to push the boundaries of model capabilities, JanusFlow represents an important milestone toward creating more versatile and versatile multi-modal AI systems.
Model: https://huggingface.co/deepseek-ai/JanusFlow-1.3B
Paper: https://arxiv.org/abs/2411.07975
All in all, JanusFlow has shown great potential in the field of multi-modal AI with its efficient architecture and excellent performance, pointing out a new direction for the development of future AI models. Looking forward to JanusFlow playing a role in more application scenarios!