With the rapid development of AI technology, the demand for visual language models is growing day by day, but its high computing resource requirements limit its application on ordinary devices. The editor of Downcodes will introduce to you today a lightweight visual language model called SmolVLM, which can run efficiently on devices with limited resources, such as laptops and consumer-grade GPUs. The emergence of SmolVLM has brought more users the opportunity to experience advanced AI technology, lowered the threshold for use, and also provided developers with more convenient research tools.
In recent years, there has been an increasing demand for the application of machine learning models in vision and language tasks, but most models require huge computing resources and cannot run efficiently on personal devices. Especially small devices such as laptops, consumer GPUs, and mobile devices face huge challenges when processing visual language tasks.
Taking Qwen2-VL as an example, although it has excellent performance, it has high hardware requirements, which limits its usability in real-time applications. Therefore, developing lightweight models to run with lower resources has become an important need.
Hugging Face recently released SmolVLM, a 2B parameter visual language model specially designed for device-side reasoning. SmolVLM outperforms other similar models in terms of GPU memory usage and token generation speed. Its main feature is the ability to run efficiently on smaller devices, such as laptops or consumer-grade GPUs, without sacrificing performance. SmolVLM finds an ideal balance between performance and efficiency, solving problems that were difficult to overcome in previous similar models.
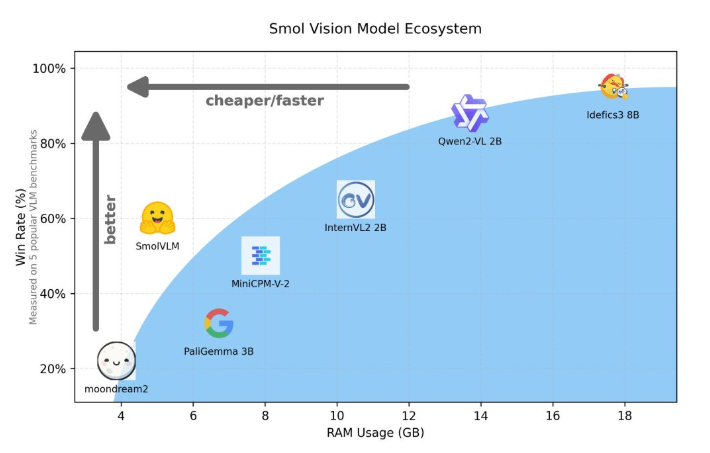
Compared with Qwen2-VL2B, SmolVLM generates tokens 7.5 to 16 times faster, thanks to its optimized architecture, which makes lightweight inference possible. This efficiency not only brings practical benefits to end users, but also greatly enhances the user experience.
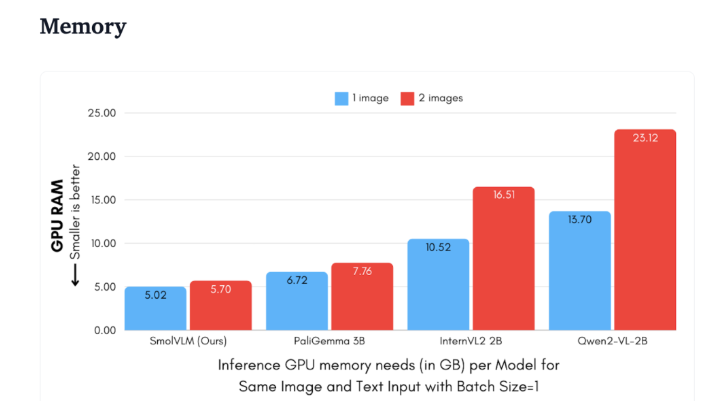
From a technical perspective, SmolVLM has an optimized architecture that supports efficient device-side inference. Users can even easily make fine-tuning on Google Colab, greatly lowering the threshold for experimentation and development.
Due to its small memory footprint, SmolVLM is able to run smoothly on devices that were previously unable to host similar models. When testing a 50-frame YouTube video, SmolVLM performed well, scoring 27.14%, and outperformed the two more resource-intensive models in terms of resource consumption, demonstrating its strong adaptability and flexibility.
SmolVLM is an important milestone in the field of visual language models. Its launch enables complex visual language tasks to be run on everyday devices, filling an important gap in current AI tools.
SmolVLM not only excels in speed and efficiency, but also provides developers and researchers with a powerful tool to facilitate visual language processing without expensive hardware expenses. As AI technology continues to become more popular, models like SmolVLM will make powerful machine learning capabilities more accessible.
demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
All in all, SmolVLM has set a new benchmark for lightweight visual language models. Its efficient performance and convenient use will greatly promote the popularization and development of AI technology. We look forward to more similar innovations in the future, allowing AI technology to benefit more people.