The editor of Downcodes learned that Ai2, a non-profit AI research institution, recently released its new OLMo2 series of language models, which is the second generation of its "Open Language Model" (OLMo) series. OLMo2 adheres to the concept of completely open source code, and its training data, tools and codes are fully open. This is particularly important in today's AI field and represents a new height in the development of open source AI. Unlike other models that claim to be "open", OLMo2 strictly follows the definition of the Open Source Initiative, meets the strict standards of open source AI, and provides the AI community with strong technical support and valuable learning resources.
Ai2, a non-profit AI research organization, recently released its new OLMo2 series, which is the second generation model of the "Open Language Model" (OLMo) series launched by the organization. The release of OLMo2 not only provides strong technical support for the AI community, but also represents the latest development of open source AI with its completely open source code.
Unlike other "open" language models currently on the market such as Meta's Llama series, OLMo2 meets the strict definition of the Open Source Initiative, which means that the training data, tools and code used for its development are public and accessible to anyone. and use. As defined by the Open Source Initiative, OLMo2 meets the organization's requirements for an "open source AI" standard, which was finalized in October this year.
Ai2 mentioned in its blog that during the development process of OLMo2, all training data, codes, training plans, evaluation methods and intermediate checkpoints were completely open, aiming to promote innovation and discovery in the open source community through shared resources. "By openly sharing our data, solutions and findings, we hope to provide the open source community with the resources to discover new methods and innovative technologies." Ai2 said.
The OLMo2 series includes two versions: one is OLMo7B with 7 billion parameters, and the other is OLMo13B with 13 billion parameters. The number of parameters directly affects the performance of the model, and versions with more parameters can usually handle more complex tasks. OLMo2 performed well on common text tasks, being able to complete tasks such as answering questions, summarizing documents, and writing code.

Picture source note: The picture is generated by AI, and the picture is authorized by the service provider Midjourney
To train OLMo2, Ai2 used a data set containing five trillion tokens. Token is the smallest unit in the language model. 1 million tokens are approximately equal to 750,000 words. The training data includes content from high-quality websites, academic papers, Q&A discussion boards, and synthetic mathematics workbooks, and is carefully selected to ensure the efficiency and accuracy of the model.
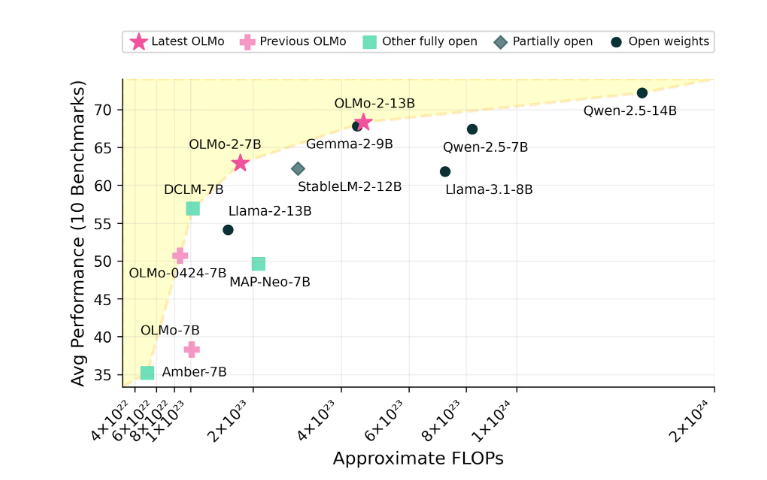
Ai2 is confident in the performance of OLMo2, claiming that it has competed with open source models such as Meta’s Llama3.1 in performance. Ai2 pointed out that the performance of OLMo27B even surpassed Llama3.18B and became one of the strongest fully open language models currently. All OLMo2 models and their components can be downloaded for free through the Ai2 official website and follow the Apache2.0 license, which means that these models can be used not only for research but also for commercial applications.
The open source nature of OLMo2 will greatly promote open cooperation and innovation in the field of AI, providing researchers and developers with a broader space for development. We look forward to OLMo2 bringing more breakthroughs and applications in the future.