Meta AI has shockingly released a basic multi-modal language model called SPIRIT LM, which is a landmark achievement that can freely mix text and speech! It is based on a pre-trained text language model with 7 billion parameters, and extends to the speech mode through continuous training, realizing dual-modal understanding and generation of text and speech, and can even mix the two, bringing unexpected application effects. The editor of Downcodes will take you to have an in-depth understanding of the powerful functions of SPIRIT LM and the technological breakthroughs behind it.
Meta AI has recently open sourced a basic multi-modal language model called SPIRIT LM, which can freely mix text and speech, opening up new possibilities for multi-modal tasks of audio and text.
SPIRIT LM is based on a 7 billion parameter pre-trained text language model and extends to speech modalities through continuous training on text and speech units. It can understand and generate text like a large text model, and it can also understand and generate speech. It can even mix text and speech together to create various magical effects! For example, you can use it for speech recognition, and Convert speech into text; you can also use it for speech synthesis to convert text into speech; you can also use it for speech classification to determine what emotion a piece of speech expresses.
What's even more powerful is that SPIRIT LM is also particularly good at "emotional expression"! It can recognize and generate a variety of different voice intonations and styles, making the AI's voice sound more natural and emotional. You can imagine that the voice generated by SPIRIT LM is no longer the cold machine voice, but like a real person speaking, full of joy, anger, sorrow and joy!
In order to make AI better "emotional", Meta researchers have also specially developed two versions of SPIRIT LM:
"Basic Edition" (BASE): This version mainly focuses on the phoneme information of speech, which is the "basic composition" of speech.
"Expressive version" (EXPRESSIVE): In addition to phoneme information, this version also adds tone and style information, which can make the AI's voice more vivid and expressive.
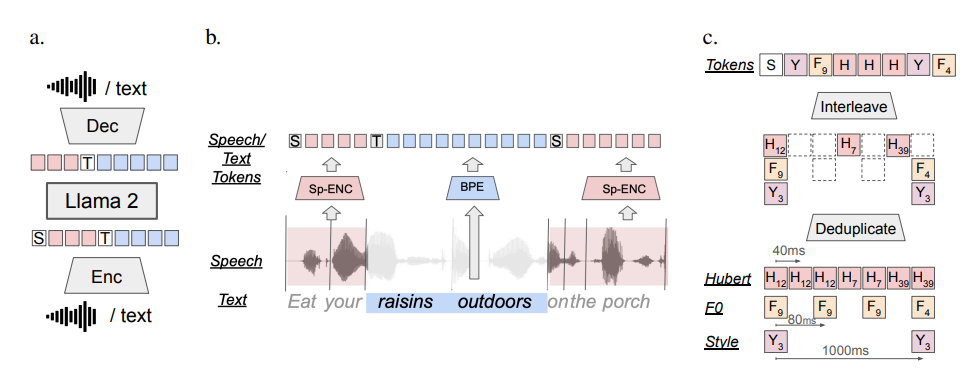
So, how does SPIRIT LM do all this?
Simply put, SPIRIT LM is trained based on LLAMA2, a super powerful text large model previously released by Meta. The researchers "fed" a large amount of text and speech data to LLAMA2 and adopted a special "interleaved training" method so that LLAMA2 can learn the rules of text and speech at the same time.
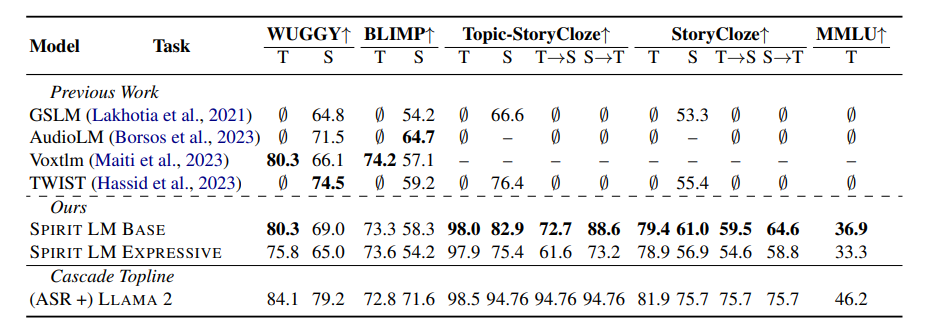
In order to test SPIRIT LM's "emotional expression" ability, Meta researchers also designed a new test benchmark - the "Speech-Text Sentiment Preservation Benchmark" (STSP). This test benchmark contains a variety of speech and text prompts expressing different emotions to test whether the AI model can accurately recognize and generate speech and text with corresponding emotions. The results show that the "expression version" of SPIRIT LM performs well in emotion retention and is currently the first AI model that can retain emotional information across modalities!
Of course, Meta researchers also admitted that SPIRIT LM still has many areas for improvement. For example, SPIRIT LM currently only supports English and needs to be expanded to other languages in the future; the model scale of SPIRIT LM is not large enough, and it is necessary to continue to expand the model scale and improve model performance in the future.
SPIRIT LM is Meta's major breakthrough in the field of AI. It opens the door for us to the "sounding and emotional" AI world. I believe that in the near future, we will see more interesting applications developed based on SPIRIT LM, so that AI can not only speak eloquently, but also express emotions like real people, and communicate with us more naturally and cordially!
Project address: https://speechbot.github.io/spiritlm/
Paper address: https://arxiv.org/pdf/2402.05755
All in all, the open source of SPIRIT LM has brought exciting progress to the field of multi-modal AI. Its emergence heralds that AI will achieve greater breakthroughs in voice interaction and emotional expression in the future. The editor of Downcodes will continue to pay attention to this field. The latest news, please stay tuned!